







参考代码:sc_depth_pl
1. 概述
介绍:基于运动恢复的自监督深度估计算法中会假设所处的场景是静止的,但是实际中这样的假设是不现实的,因而运动的物体和遮挡就会违反之前的场景先验假设,从而导致对应区域上出现深度预测异常。对于物体的运动和遮挡情况,在之前的工作中有采用直接预测运动场、分割方法标注、光流场、几何先验等方法进行补救,但是作用范围也是有限的。同时,由于物体边界的模糊性也会导致深度估计的边缘模糊。对此文章提出了一种使用伪深度(pseudo-depth)作为深度引导(这个伪深度其实是由一个深度估计模型预测输出的,虽然不准确但是能提供基本的轮廓和远近信息),从而提升自监督深度估计方法的预测能力。
将文章的输出结果(第三排)与自监督深度估计方法的结果(第二排)进行对比,见下图:
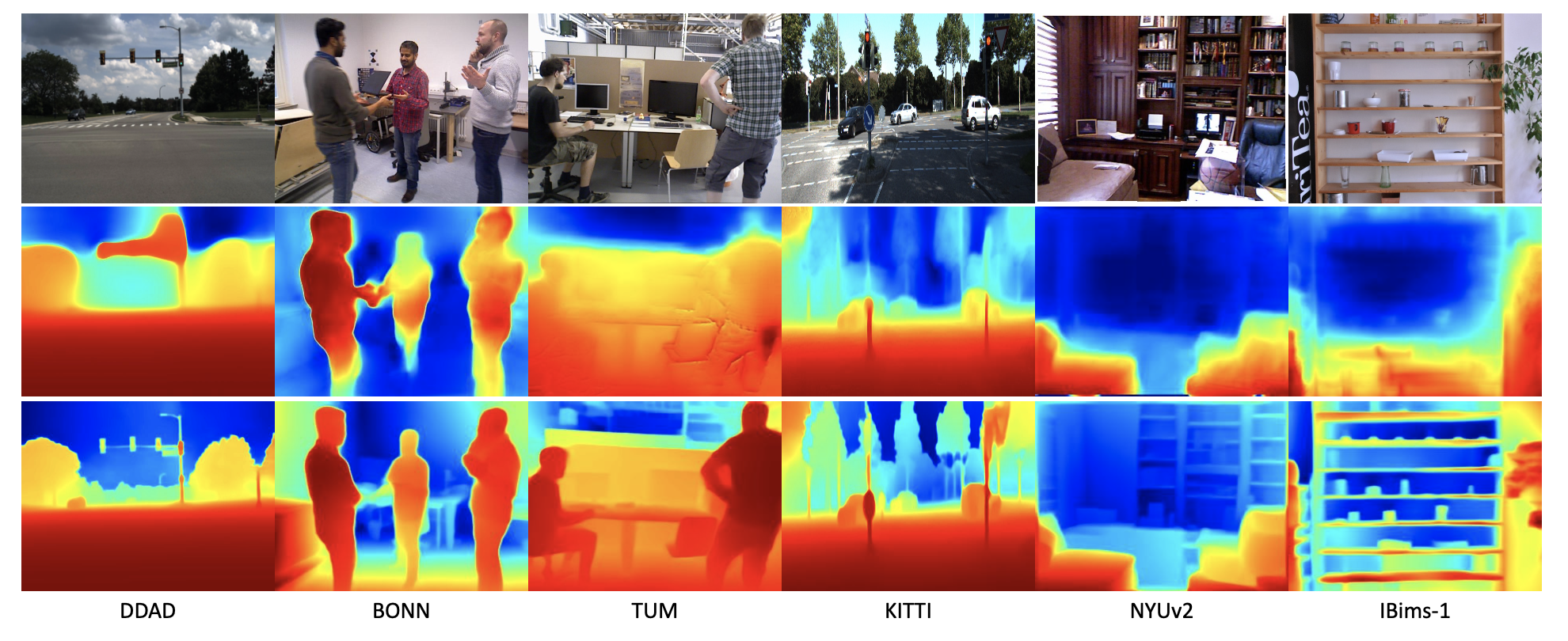
从图中可以明确看到文章的方法输出结果更加准确,同时细节也更多。不过文章的方法是在加入pseudo-depth下才能得到巨大提升的,而对应的深度估计模型也是需要数据进行训练的,也会存在各种各样的corner-case,只能说这样的方法对大部分场景能较好处理。
2. 方法设计
2.1 方法设计
文章的方法见下图所示:
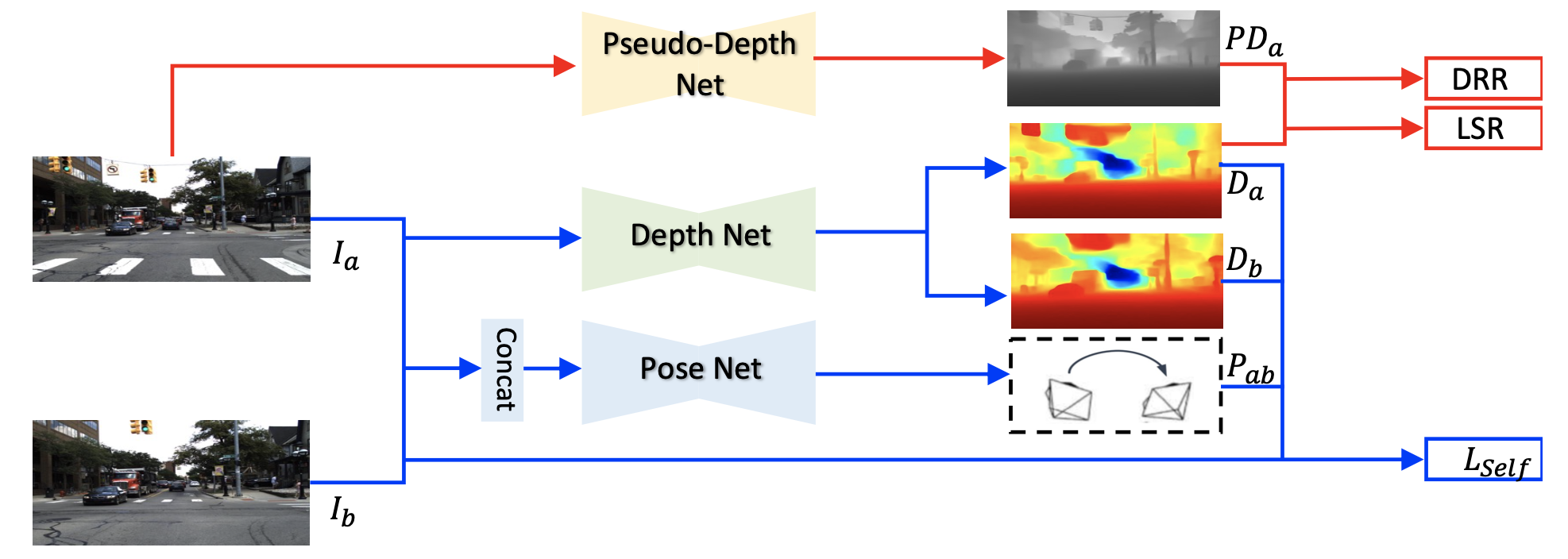
从图中可以看到在自监督方法基础上添加了pseudo-depth约束:DRR和LSR。对于自监督部分中对于运动情况的处理采用的是之前(版本为V1~V2)中使用到的深度一致性假设,记当前帧和前一帧的预测深度图表示为 D a , D b D_a,D_b Da,Db,则使用估计出的pose信息进行变换之后两者的神对差异应该比较小,因而可以建立约束损失函数:
L G = 1 ∣ V ∣ ∑ p ∈ V D d i f f ( p ) L_G=\frac{1}{|V|}\sum_{p\in V}D_{diff}(p) LG=∣V∣1p∈V∑Ddi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









