







主页:Dynamo-Depth
参考代码:dynamo-depth
动机与出发点
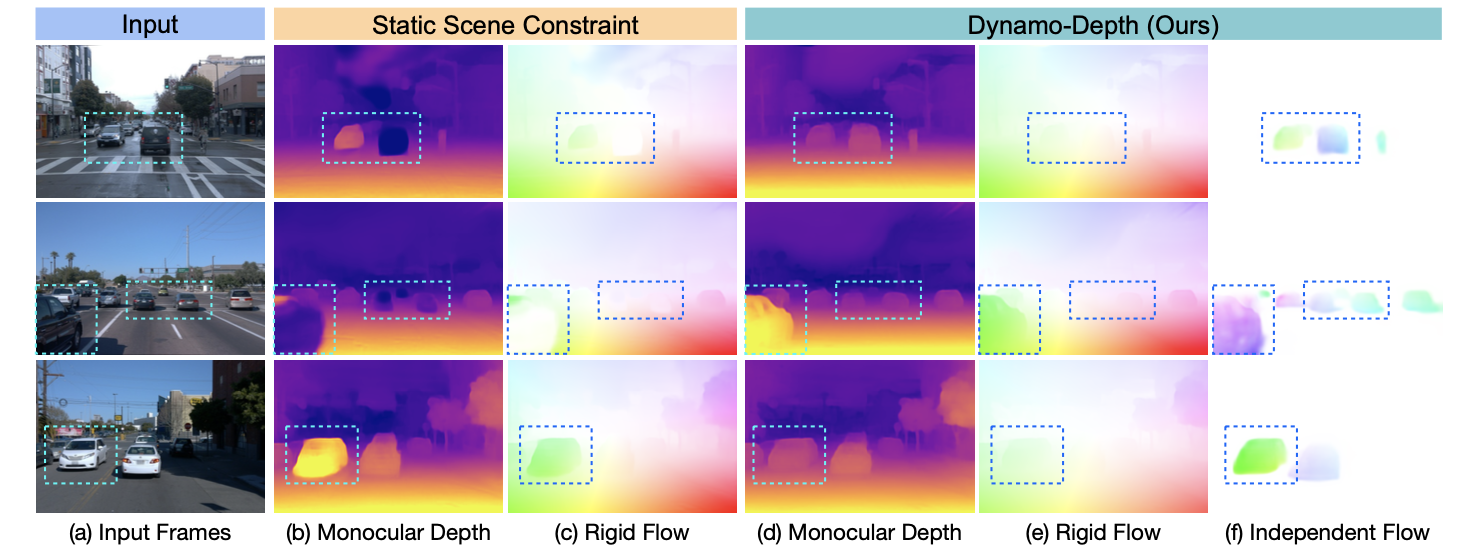
这是一份很棒的工作,对自监督深度估计中的运动目标场景做了细致分析,并给出了对应解决方案以提升自监督深度架构对于运动目标深度估计的性能。对原始自监督深度估计的模型观察,文章指出静态目标相比动态目标更快收敛,也就是说随着迭代次数的增多,动态目标上深度估计表现出的错误会越来越多,这是一个很重要的观察。对于动态目标的建模,一般采用3D运动场稀疏化进行约束,但是自监督深度估计在训练的早期,网络是不稳定的且充满噪声,则一个好的运动目标mask初始化和合理的约束机制是很重要的。那么在运动目标mask和3D运动场的加持下就能对运动目标比较好地建模,那么对应运动目标带来的孔洞问题便可以很大程度上得到缓解。下面就对比了违反静态假设导致的深度估计错误的典型结果
方法设计
观察文章的网络结构,与MonoDepth2这类自监督深度估计算法在上半部分支路:深度估计网络和位姿估计网络部分,是一致的。在此基础上增加3D运动场估计和运动目标估计,从而实现对于运动目标针对性建立补偿
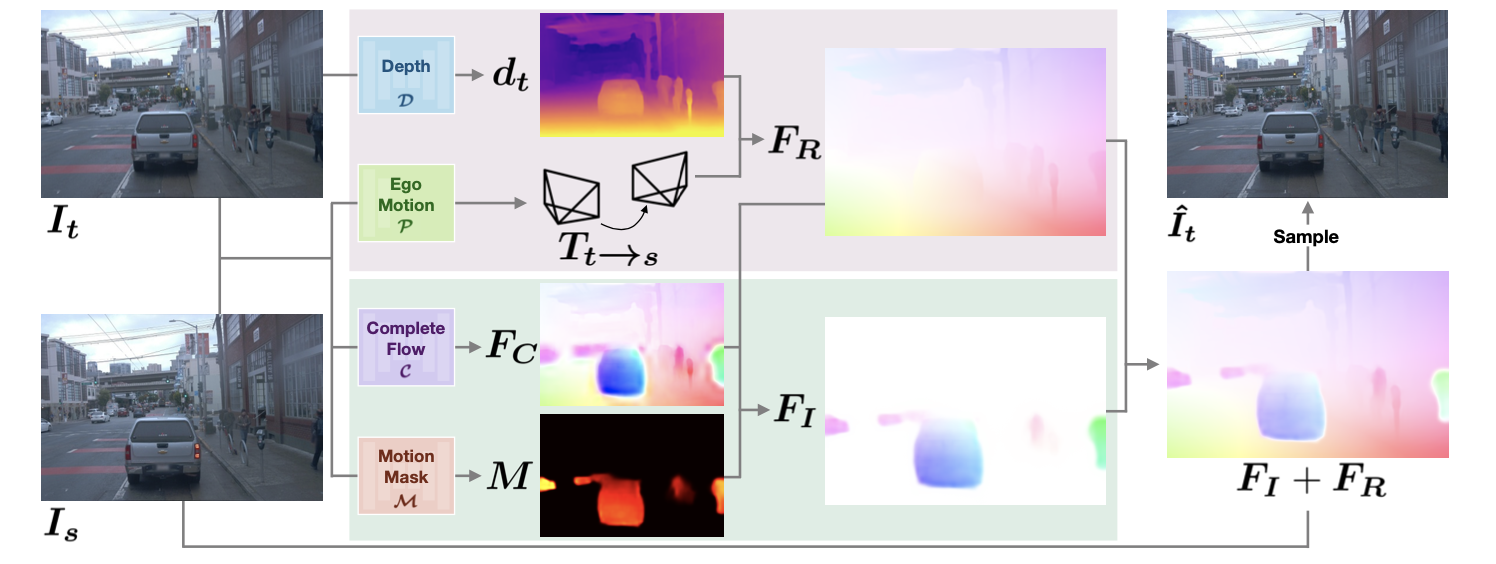
在上图中可以看到对于运动的描述分为两个部分:相机自身运动下 静态目标的刚体运动
F
R
F_R
FR 和 运动目标自身独立的运动
F
I
F_I
FI,目的便是需要求取后一个的具体值,这样才能对整个运动场进行补偿,这也是动态场景下自监督深度估计成功的重要条件。
运动目标mask和3D运动场的初始化
对于mask的建模采用而止mask的形式,只是里面大部分像素都是0,代表静止元素。而3D运动场就是场景中每个像素在3D下的运动估计,之前的论文中有直接对它进行稀疏化约束的,对应实验结果也证明是可行的。在这篇文中通过额外预测运动目标mask的方式减轻了3D运动场估计的难度,有助于稳定网络训练过程。
基于上面对不同epoch深度估计模型的观察,深度估计上的空洞是在迭代的后期才出现的,那么可以取未经过改进的自监督深度估计(如第5 epoch下)前期模型用于运动目标mask和3D运动场的初始化,有助于整体网络的稳定。
损失函数的约束
自监督深度估计肯定会带光度重构误差项,对于这篇文章需要约束的东西多了,那么对应的约束项也要对应增加。对于结果的平滑损失
L
s
L_s
Ls增加3D运动场
F
C
F_C
FC和运动mask (
M
M
M)的平滑约束
L
s
=
γ
s
d
l
s
(
d
t
∗
,
I
t
)
+
γ
s
s
c
l
s
(
F
C
,
I
t
)
+
γ
s
m
l
s
(
M
,
I
t
)
L_s=\gamma_{sd}l_s(d_t^{*},I_t)+\gamma_{ssc}l_s(F_C,I_t)+\gamma_{sm}l_s(M,I_t)
Ls=γsdls(dt∗,It)+γsscls(FC,It)+γsmls(M,It)
对于非运动目标区域需要保持3D运动场的估计结果与位姿+深度的变换结果近似
L
c
=
1
H
W
∑
p
(
1
−
M
(
p
)
)
⋅
F
D
(
p
)
,
F
D
(
p
)
=
∣
∣
F
C
(
p
)
−
F
R
(
p
)
∣
∣
1
L_c=\frac{1}{HW}\sum_p(1-M(p))\cdot F_D(p),\ F_D(p)=||F_C(p)-F_R(p)||_1
Lc=HW1p∑(1−M(p))⋅FD(p), FD(p)=∣∣FC(p)−FR(p)∣∣1
对于非运动目标区域对应mask的位置上应该为0,采用二值交叉墒去约束
L
m
=
g
(
{
M
(
p
)
:
∀
p
s
.
t
.
F
D
(
p
)
≤
m
e
a
n
(
F
D
)
}
)
L_m=g(\{M(p):\forall_p\ s.t.\ F_D(p)\le mean(F_D)\})
Lm=g({M(p):∀p s.t. FD(p)≤mean(FD)})
在3D点云空间通过随机采样一致性约束深度平面
L
g
=
1
H
W
∑
p
R
e
L
U
(
d
t
g
(
p
)
−
d
t
∗
(
p
)
)
L_g=\frac{1}{HW}\sum_pReLU(d_t^g(p)-d_t^{*}(p))
Lg=HW1p∑ReLU(dtg(p)−dt∗(p))
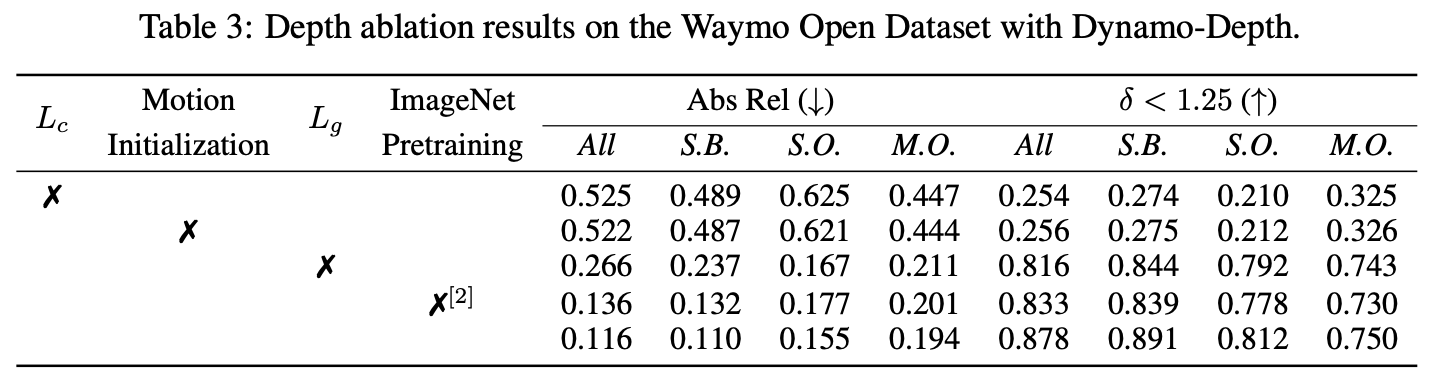
那么上面的几个损失函数项对性能的见下表所示:
实验结果
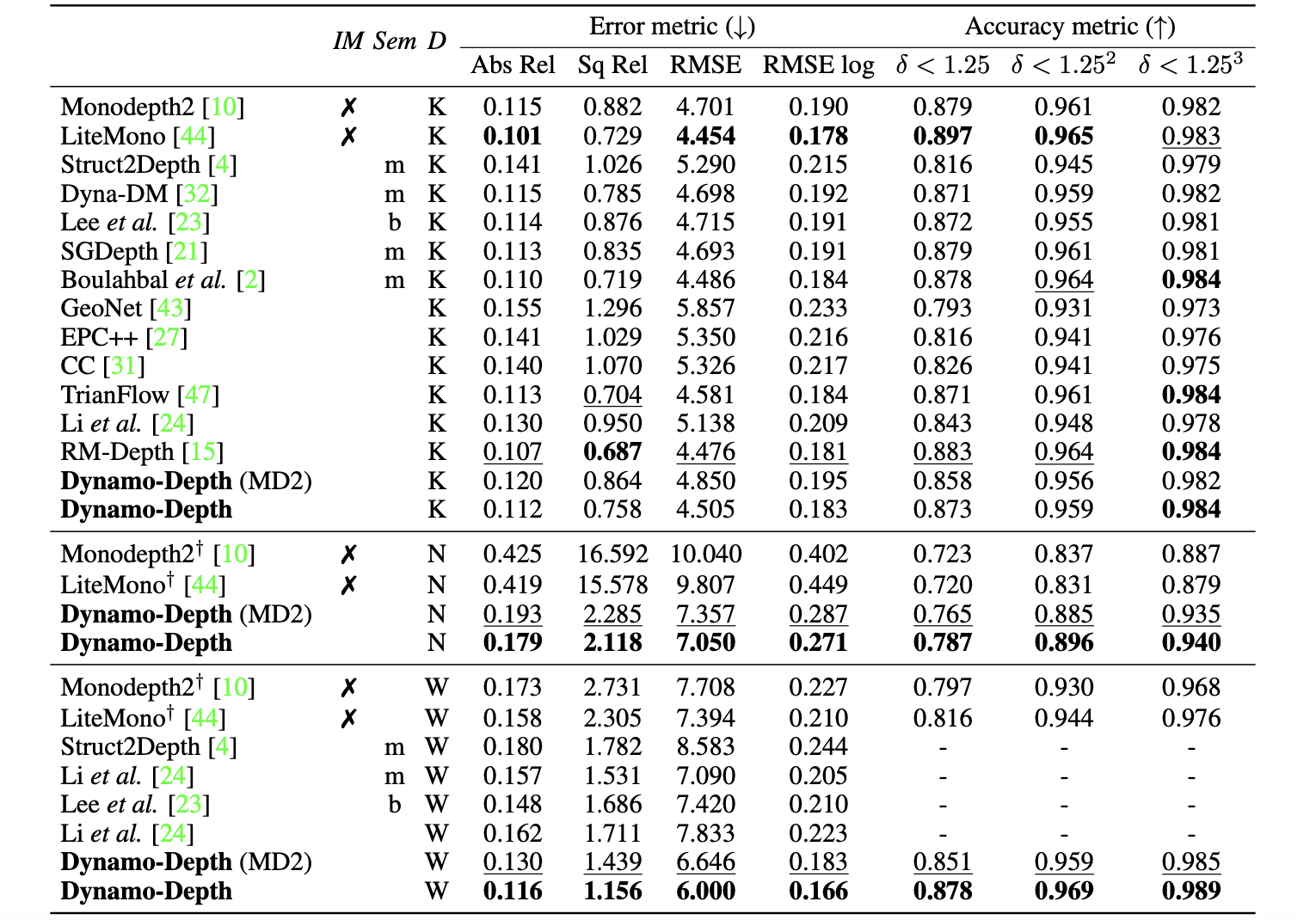
KITTI数据集下的性能比较:
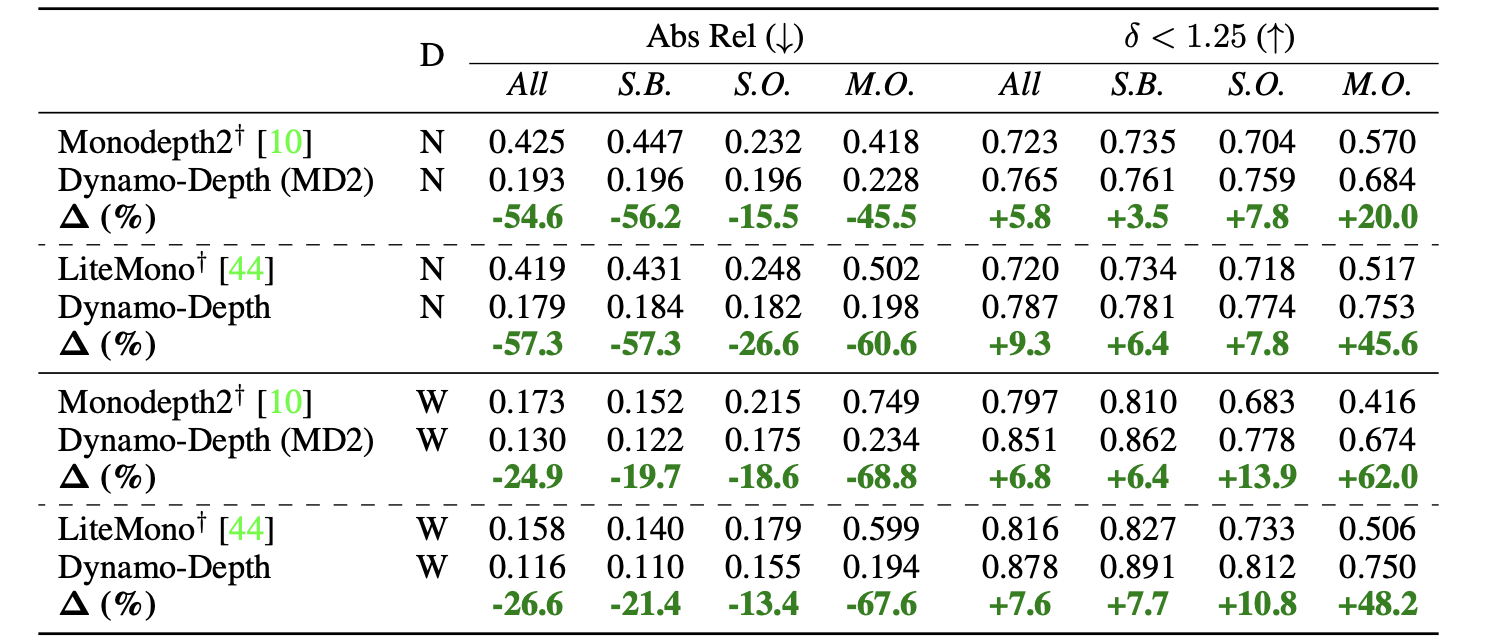
NuScenes下的性能比较:















 144
144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









