







1. 概述
这篇文章的方法融合自然场景下文字检测和识别,使用语义分割实现了端到端的文本检测和识别。该方法源自于Mask R-CNN,在头部实现文本检测与文本识别,文本检测的结果影响文本识别的性能,而反过来识别的结果能帮助检测器去排除一些非文本的检测结果。
这篇文章解决的是自然场景下文本的检测与识别,那么自然场景的文本是任意形状的,那么就带来了两个问题:
1)文本无法已经无法使用任意四边形进行边界界定,文中是说使用mask分割掩膜来实现任意文本的检测;
2)对于一般情况下CRNN识别的文本场景是1D的数据结构,但是现在输入的是2D的掩膜图,这是文章需要解决的,在后面内容介绍;
下图中的左边两幅是使用现有的方法进行检测得到的结果,最后一张是使用这篇文章的方法进行检测得到的结果。

文章的主要贡献:
1)提供了一个端到端可训练的任意文本检测识别模型;
2)文章的方法可以检测任意形状的文本,使用是mask去检测,而不是多边形,对应的文本识别也是通过mask来实现的;对于文本的识别一般有三种策略:逐字符识别、逐单词识别以及序列识别,基于序列的识别在1D的场景下广泛使用,对于当前需要处理的任意场景任意文本情况下,文章还是采取逐字符识别的方式实现本文识别的。
2. 模型架构
2.2 整体结构
文章提出的框架结构见下图2,其由四个部分组成:由FPN(Feature Pyramid Network)组成的基础网络、一个用于产生文本区域候选的RPN网络、一个用于边界框回归的Fast R-CNN回归子网络、一个用于文本呢与字符分割的生成掩膜分支。

对于前面的三个组成成分,已经是早有的东西,这里就不过多解释了。说一下这里的掩膜分支,这里的掩膜主要完成两个任务,第一个是分割出整个趋于的掩膜;第二个是分割出单字符类别的掩膜,其结构见下图3。这里需要注意的是在Faster R-CNN头中输入的特征图是
7
∗
7
7*7
7∗7的,但是这里掩膜分支里面将其固定为了
16
∗
64
16*64
16∗64的分辨率,猜想是因为一般情况下字符趋于是呈现长条形的。
2.2 标注生成
文章提出的新框架任务已经相较基础算法进行了修改,因而使用的标注方式也是不一样的,这里将一个文本区域的GT描述为
P
=
{
p
1
,
p
2
,
…
,
p
m
}
P=\{p_1,p_2,\dots,p_m\}
P={p1,p2,…,pm},结合图4就是其中的红色多边形部分(看不清楚的还是去对照原始文章吧-_-||),对于每个字符区域使用
C
=
{
c
1
=
(
c
c
1
,
c
l
1
)
,
…
,
c
n
=
(
c
c
n
,
c
l
n
)
}
C=\{c_1=(cc_1,cl_1),\dots,c_n=(cc_n,cl_n)\}
C={c1=(cc1,cl1),…,cn=(ccn,cln)},其中
c
c
j
cc_j
ccj代表的是字符的离别,
c
l
j
cl_j
clj代表的是字符的位置,结合图4就是每个字符的黄色框区域。在训练过程中对于整个的文本区域选用做小外接水平矩形去截取,结合图4就是图中绿色的框。在生成最后的RoI的时候使用的是下面的缩放关系实现分辨率的统一的。
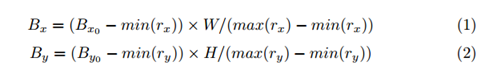

2.3损失函数定义
由于文章的算法是多任务,因而具有的损失函数也是多样的,先看整体的损失函数的定义吧,其形式如下:
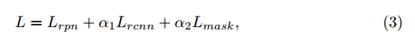
其中
L
r
p
n
,
L
r
c
n
n
L_{rpn},L_{rcnn}
Lrpn,Lrcnn分别代表的是RPN与边界框回归分类的误差,最后一项自然是mask分支的偏差了。
其中,mask分支的损失函数由两部分组成,一个是全局文本区域的分割损失(平均二元交叉熵损失),一个是字符类别分割的损失(加权空间soft-max损失)。在这里上面两个公式中包含的所有加权系数
α
1
,
α
2
,
β
\alpha_1,\alpha_2,\beta
α1,α2,β都设置为1。后面的内容中将详细介绍这两个损失。
字符区域的分割损失,这里定义区域的全部像素数为
N
N
N,
y
n
∈
(
0
,
1
)
y_n\in (0,1)
yn∈(0,1)是分类的类别,
x
n
x_n
xn是输出的像素,
S
(
x
)
S(x)
S(x)是一个sigmoid函数。
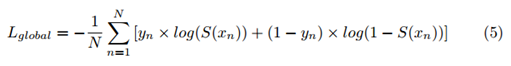
字符分割的损失,这里使用
T
T
T代表分类的类别数目,
N
N
N是每个字符映射图中的像素个数,输出
X
X
X就是维度为
N
∗
T
N*T
N∗T的矩阵,因而空间的soft-max损失就可以被定义为:
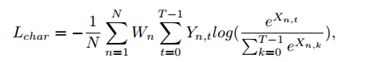
这里
Y
Y
Y是
X
X
X对应的gt,权重
W
W
W用于平衡字符类与背景类的损失,背景类使用
N
n
e
g
N_{neg}
Nneg表示,因而权重就可以表示为如下的形式:
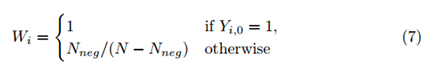
3. 实验结果
旋转本文检测结果:

扭曲文本检测结果:
















 480
480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









