







https://docs.nvidia.com/cuda/index.html
这里写目录标题
OpenCL 与OpenGl
OpenCL和OpenGL都是一种并行计算框架,但它们的功能和适用场景有所不同。
OpenCL(Open Computing Language)是一个开放标准的跨平台编程框架,旨在实现各种类型的并行计算,包括CPU、GPU、DSP等。OpenCL可以利用各种硬件资源,支持许多不同的设备和体系结构,并可用于构建大规模并行计算、机器学习、深度学习和图形处理等应用程序。OpenCL的主要优点是它能够利用各种可用的硬件,并且可以在不同厂商提供的设备之间有效地移植代码。
OpenGL(Open Graphics Library)是一个图形渲染API,用于在3D应用程序中渲染图形,包括游戏、虚拟现实、建筑设计等。OpenGL使用GPU加速渲染图形,使得图形处理速度更快,渲染质量更高。与OpenCL相比,OpenGL更关注于图形渲染方面,并不具备通用计算的能力。OpenGL可以在Windows、Linux、macOS等系统上运行,并且被广泛应用于工业设计、游戏制作和科学可视化等领域。
因此,OpenCL和OpenGL虽然均可用于并行计算,但主要的应用场景差异较大,需要根据具体的需求和硬件设备来选择使用哪种框架。
我的意思是OpenCL和OpenGL都是可用的框架,但它们的应用场景不同,需要根据具体需求来选择使用哪种框架。如果你的应用程序需要进行通用计算、机器学习或深度学习等任务,那么OpenCL可能更适合你的需求;而如果你需要进行图形渲染、虚拟现实等方面的任务,那么OpenGL则更适合你的需求。同时,有些任务也可以结合使用OpenCL和OpenGL,以实现更高效的并行计算和图形渲染。
release note
Chapter 5. Known Issues
就讲了一堆版本依赖,特征,解决了什么问题,已知有什么问题等等
CUDA Features Archive
nsight visual studio
https://developer.nvidia.com/nsight-visual-studio-edition
安装指导
本地下载和网络下载
When installing CUDA on Windows, you can choose between the Network Installer and the Local Installer. The Network Installer allows you to download only the files you need. The Local Installer is a stand-alone installer with a large initial download. For more details, refer to the Windows Installation Guide.
OpenACC(Open Accelerators)是一个针对并行计算的开放式编程标准,旨在简化 GPU 或加速器的编程过程,以提高编程效率和性能。
OpenACC 由多个计算机硬件厂商和技术公司联合发起,其中包括 NVIDIA、AMD、ARM 和 Cray 等。OpenACC 标准是基于指令集的编程方法,类似于 OpenMP,通过在源代码中插入特定的编译指令来实现并行加速。
与 OpenMP 不同的是,OpenACC 的主要目标是加速科学应用程序等大规模并行计算问题,它使用高级编译器自动化并行化、分解和优化代码。此外,OpenACC 还提供了许多可移植、可扩展的编程模型和工具,可以通过各种编程语言和支持 OpenACC 的编译器进行使用。
总之,OpenACC 是一种开放式、高度可移植和易于使用的并行计算编程标准,它可以帮助开发人员更轻松地利用 GPU 或加速器等并行硬件资源来提高程序性能。
bili 视频
https://www.bilibili.com/video/BV1vJ411D73S/?spm_id_from=333.880.my_history.page.click&vd_source=e7d12c9f66ab8294c87125a95510dac9
1
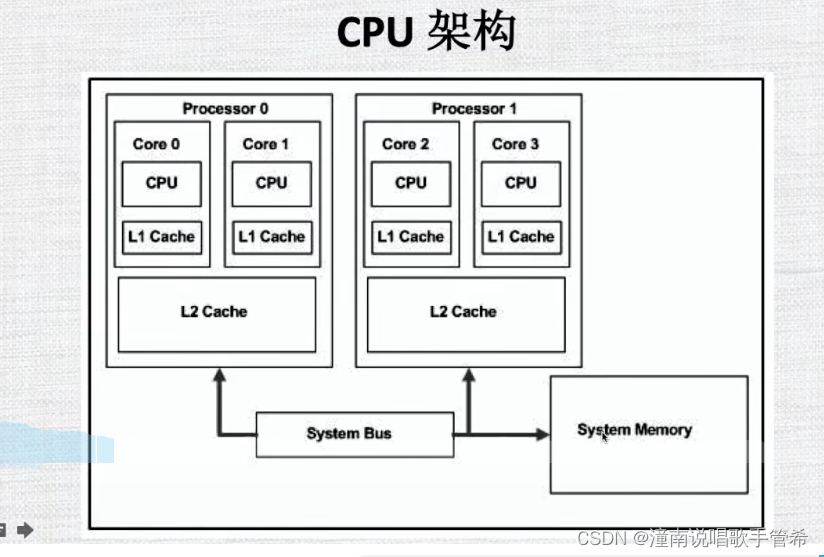
cpu架构和 gpu架构
单个cpu 多核
gpu 他推出了很多版本
c2050 版本
Fermi
SM 流多处理器
SP 流处理器
架构3
3层架构

需要专门的语言处理gpu计算 其他的公司opencl openacc
cuda为英伟达公司推出的和c/cpp绑定的语言,当然通过其他语言也是支持的。
内存拷贝 线程管理,设计用于高速运算,全局同步,复杂逻辑。
接口延迟
硬件上GPU插在主板上,一般机器pcie线速度可以16或32g每秒,在一些超级计算上延迟高一些
英伟达和 IBM 合作推出了一个名为 NVLink 的高速互联接口。
NVLink 是一种基于片上网络的高速点对点连接技术,它可以实现 CPU、GPU 和其他加速器之间的直接通信,无需传统的 PCI Express 总线架构。与传统的PCIe连接方式相比,NVLink使用更高的带宽、更低的延迟和更好的可扩展性,使得在使用 CPU 和 GPU 等异构计算资源时,可以更高效地共享数据和协同计算。
NVLink 在英伟达 GPU 和 IBM POWER 架构中广泛应用,可以显著提高深度学习、高性能计算和人工智能等领域的应用程序性能。例如,在 IBM 的 Summit 超级计算机和 Sierra 超级计算机中, NVLink 技术被用于连接 GPU 加速器和 CPU,以提供强大的计算能力和数据处理能力。
总之,NVLink 是英伟达和 IBM 共同推出的一种高速互连技术,可以提供更高效的CPU、GPU和其他加速器之间的数据传输,使得在高性能计算和人工智能等领域的应用中取得更好的性能表现。

cpu逻辑控制,管理 GPU计算核心

GPU线程切换延迟低
连接
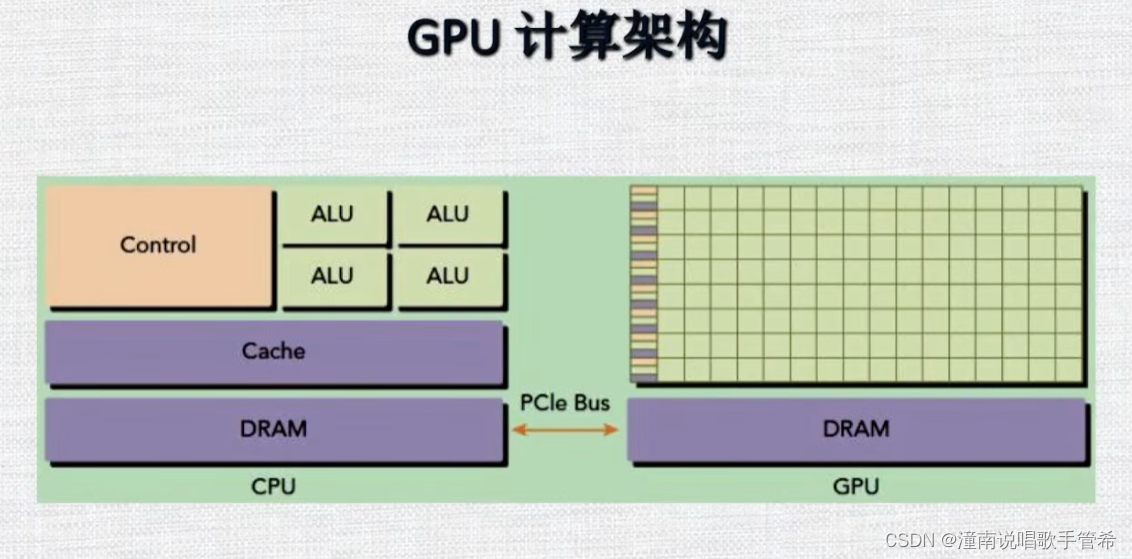
各有各的内存,通过接口互相拷贝,进行计算。
现在GPU可以申请一块内存共同访问
是的,对于 CPU 和 GPU 之间的数据传输,拷贝和访问延迟问题一直是一个需要解决的问题。为了解决这个问题,现在的 GPU 已经可以申请一块内存,即所谓的“统一虚拟内存”(Unified Virtual Memory, UVM)。
在使用 UVM 技术后,GPU 可以像 CPU 一样访问主机内存,从而避免了 CPU 和 GPU 之间数据传输时需要进行频繁拷贝和绑定内存的操作。具体地,UVM 技术可以通过软件调度将主机内存自动映射到 GPU 在其地址空间的一部分,从而让 CPU 和 GPU 共享同一块物理内存,大大降低了数据传输延迟,并且减少了程序代码中的内存管理复杂度。
此外,UVM 还提供了一些高级特性,如动态分配、延迟读取和精确定位等,可让开发人员更轻松地在 CPU 和 GPU 之间进行协同计算。这些特性允许开发人员在使用 OpenACC、CUDA 和 OpenCL 等并行编程框架时更好地控制内存资源和数据流,提高了程序性能和效率。
总之,UVM 技术是一种可用于在 CPU 和 GPU 之间共享内存的高级特性,它能够有效地降低数据传输延迟,并为开发人员提供更高效的并行编程模型。
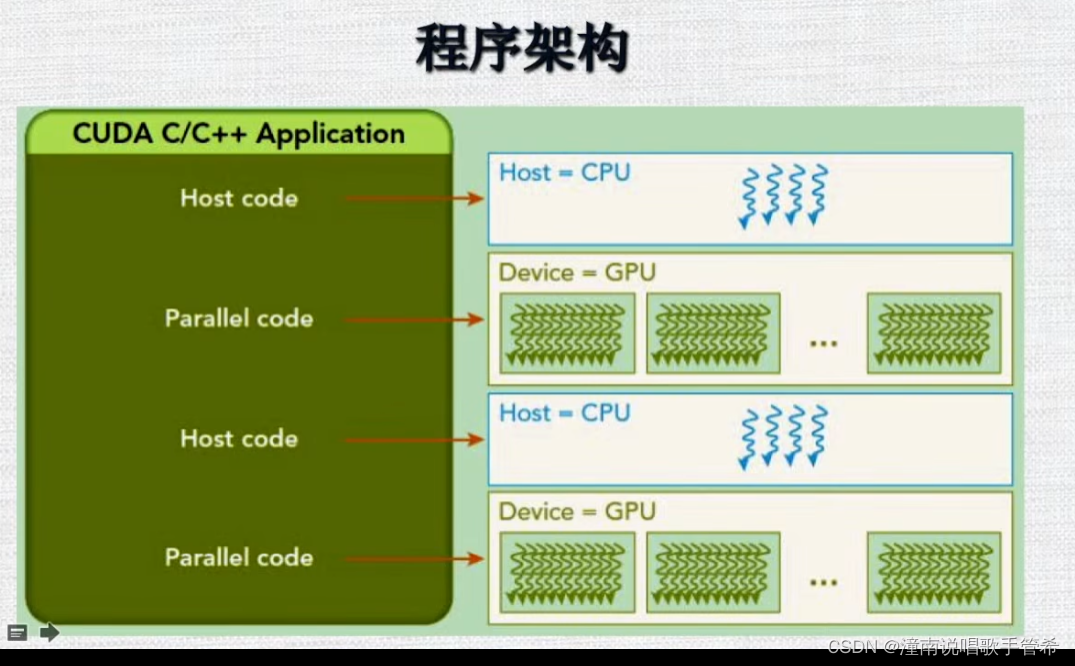
当代码运算计算量大的时候转换到gpu上

cuda可以和c和cpp混编


底层 内存管理 线程管理
如何在gpu下做规约,

GPU硬件架构综述
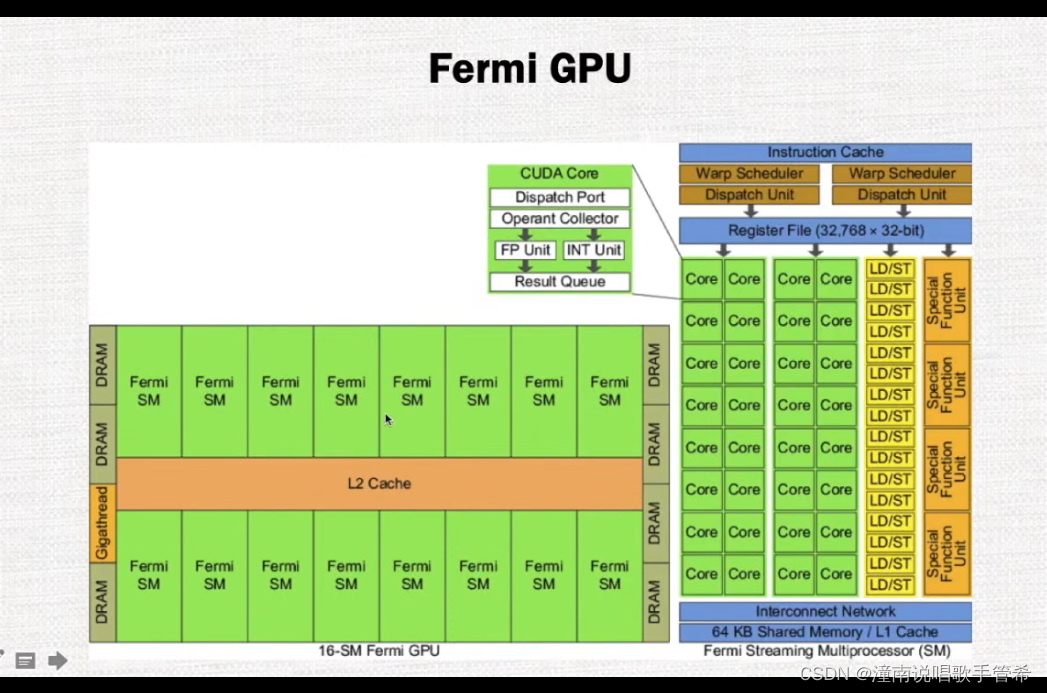
16个流多处理器通过L2高速缓存 相连
每个流多处理器架构 共享内存和L1加起来64kb可以分配
Dispatch Port(调度端口)是指现代 CPU 中用于调度指令执行的逻辑单元,也称为调度器或调度单元。
在一个 CPU 中,指令从内存中读取并在处理单元(Execution Unit, EU)中执行。然而,由于指令的执行顺序和其所需资源之间的依赖关系可能非常复杂,因此需要一个专门的逻辑单元来协调指令的执行,并将其调度到可用的 EU 上进行处理。这个逻辑单元就是 Dispatch Port。
Dispatch Port 通常由多个硬件线程组成,每个线程都可以独立地执行指令调度操作。它的主要任务是收集从前端发来的指令,并将它们投递到可用的 EU 或其他可用资源上进行处理。在指令执行期间,Dispatch Port 还会管理资源的分配和回收,以确保指令按正确的顺序进行执行,并尽可能利用 CPU 的并行性以提高性能。
总之,Dispatch Port 是现代 CPU 中用于调度指令执行的逻辑单元,它负责收集、分配和投递指令到可用的处理单元上进行执行,以实现计算资源的最大化利用和程序性能的最大化优化。
LD/ST 是从内存中读取(Load)和写入(Store)数据的指令缩写。在计算机体系结构中,LD 和 ST 指令通常用于访问寄存器或内存中存储的数据,以及将计算结果写回寄存器或内存中。
LD 指令被用于从内存中读取数据,并将其加载到一个寄存器中,它是一种典型的数据访问指令。具体来说,当处理器执行 LD 指令时,它会根据指定的内存地址从内存中读取数据,并将数据加载到一个寄存器中。在数据加载完成后,程序可以使用寄存器中的数据进行计算或其他操作。
ST 指令则用于将数据从寄存器或其他处理器状态写入到内存中。具体来说,当处理器执行 ST 指令时,它会将指定的寄存器或其他处理器状态中的数据写入到指定的内存地址中。在写操作完成后,程序可以根据需要对内存中的数据进行后续的读取或修改操作。
总之,LD/ST 指令是计算机体系结构中的两种基本数据访问指令,它们可以帮助程序对寄存器或内存中存储的数据进行读取和写入操作,从而实现各种计算和数据处理任务。
架构2
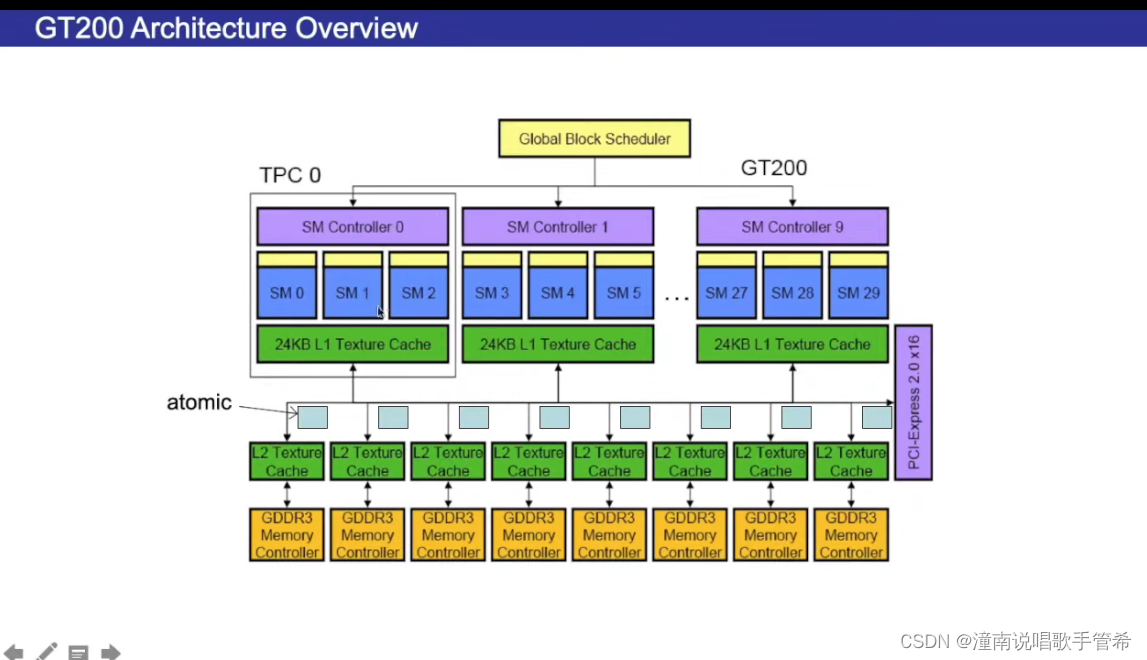
这里的流处理器不是平等的
这里3个组成一块,可以通过L2缓存与显存连接
atomic
在计算机科学中,Atomic(原子)通常指可以被“原子化”执行的操作或代码块。原子操作是一个不可分割的操作,即一旦开始执行,就不能被中断或分割为更小的部分。也就是说,原子操作可以保证整个操作具有原子性,即要么全部执行成功,要么全部不执行。
在并发编程中,原子操作是非常重要和常见的概念。多个线程或进程同时访问共享资源时,为了避免竞态条件或死锁等问题,需要使用原子操作来确保多个操作之间的同步和一致性。比如,在多线程编程中,常用的原子操作包括CAS(Compare-and-Swap)、Add等。
在编程语言中,通常有专门的原子操作库或函数,可以提供多种原子操作。例如,在Java中,提供了AtomicInteger等原子操作类,在C++11中,也提供了std::atomic等原子类型和操作函数。
总之,Atomic(原子)通常是指可以被“原子化”执行的操作或代码块。它在并发编程和共享资源访问中起着非常重要的作用,可以帮助程序员避免竞态条件或死锁等问题,并保障多个操作之间的同步和一致性。
memory controller
Memory Controller(内存控制器)是一种位于计算机主板或处理器芯片中的硬件逻辑,用于管理计算机系统中的内存访问和数据传输。它负责将来自处理器和其他I/O设备的数据写入到内存中,并从内存中读取数据返回给处理器或其他设备。
在一个计算机系统中,内存控制器通常与处理器或芯片组集成在一起,它可以通过内存总线(Memory Bus)或其他高速通道向 RAM 或其他类型的内存进行数据传输。内存控制器还能够管理内存中的读写操作,以确保所有的内存访问和数据传输都能高效、正确地完成,并维护内存的一致性和完整性。
内存控制器的工作原理是将程序或数据存储在内存中,当需要时,CPU 会向内存控制器发送内存地址,并从内存中获取相关数据。内存控制器本身也被视为一种特殊的处理器,它使用专门的内存控制指令来操作内存,并且可以将内存数据进行缓存,以提高内存访问速度。
总之,Memory Controller 是一种位于计算机主板或处理器芯片中的硬件逻辑,它用于管理计算机系统中的内存访问和数据传输,以及维护内存的一致性和完整性。它在计算机体系结构中起着重要作用,对计算机的性能和稳定性都有着直接的影响。

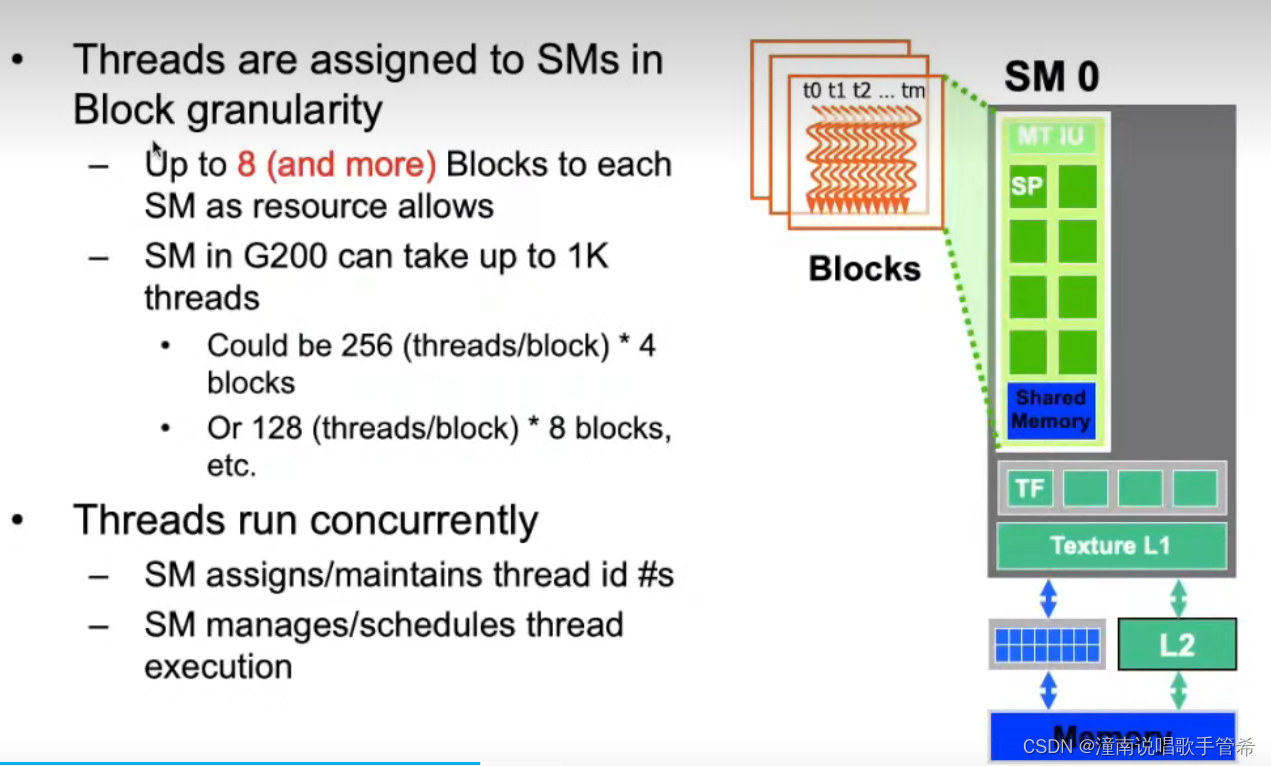
多个流处理器组成一个小组
流多处理器
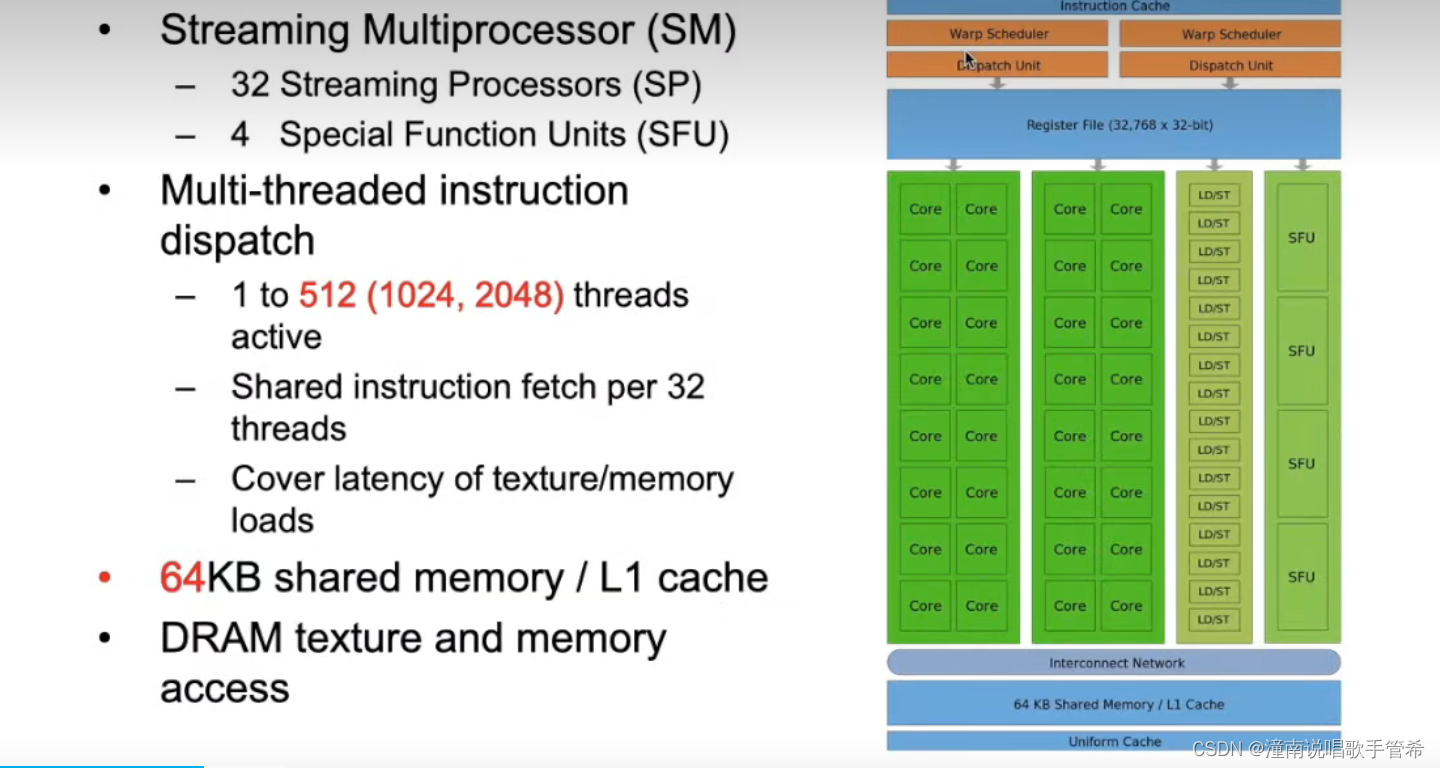
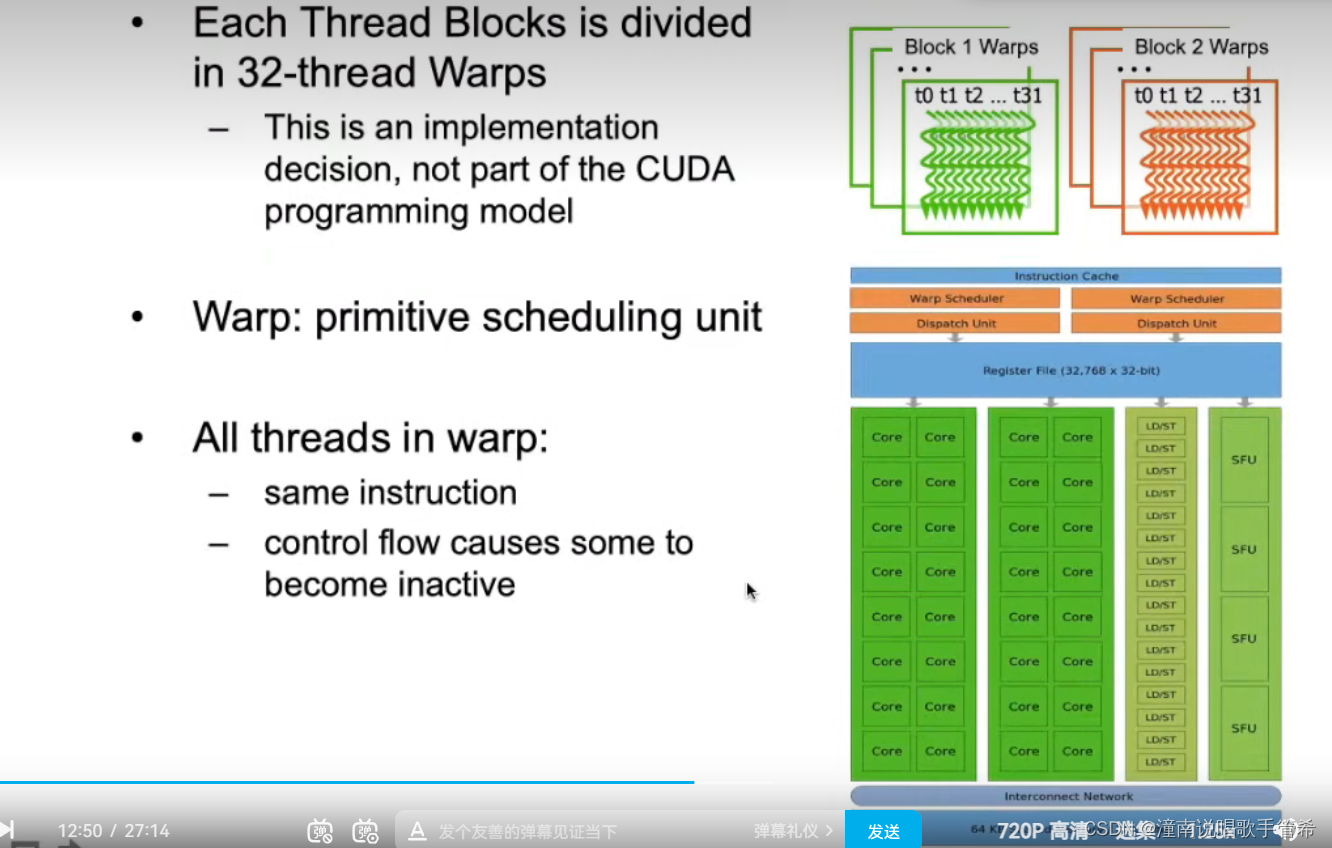
每32个线程称为一个wrap,最基本的程序处理单位,虚拟的并行结构。
每个wrap执行相同的,128线程分为4个wrap
Wrap scheduler 通常用于任务调度和函数执行,这些操作主要是 CPU 密集型的,因此并不需要使用 GPU 来加速这些操作。在 GPU 中也没有直接支持 Wrap scheduler 的相关功能。
然而,如果你的任务涉及到了大规模的数据处理或机器学习等 GPU 计算密集型工作,那么你可以使用基于 GPU 加速的 Python 库(如 TensorFlow、PyTorch 等)来完成任务,并将任务调度交给 Wrap scheduler 来管理。在这种情况下,你需要确保将 GPU 相关的代码嵌入到 Wrap scheduler 调度的任务中,以便更好地利用 GPU 资源。
需要注意的是,GPU 资源比较宝贵,一些任务可能会占据很多 GPU 资源并导致其他任务受到影响。因此,在使用 Wrap scheduler 来调度 GPU 计算的同时,你需要对 GPU 资源进行合理的分配和管理,以确保资源的最大化利用和任务的高效执行。
3及结构 块 网格
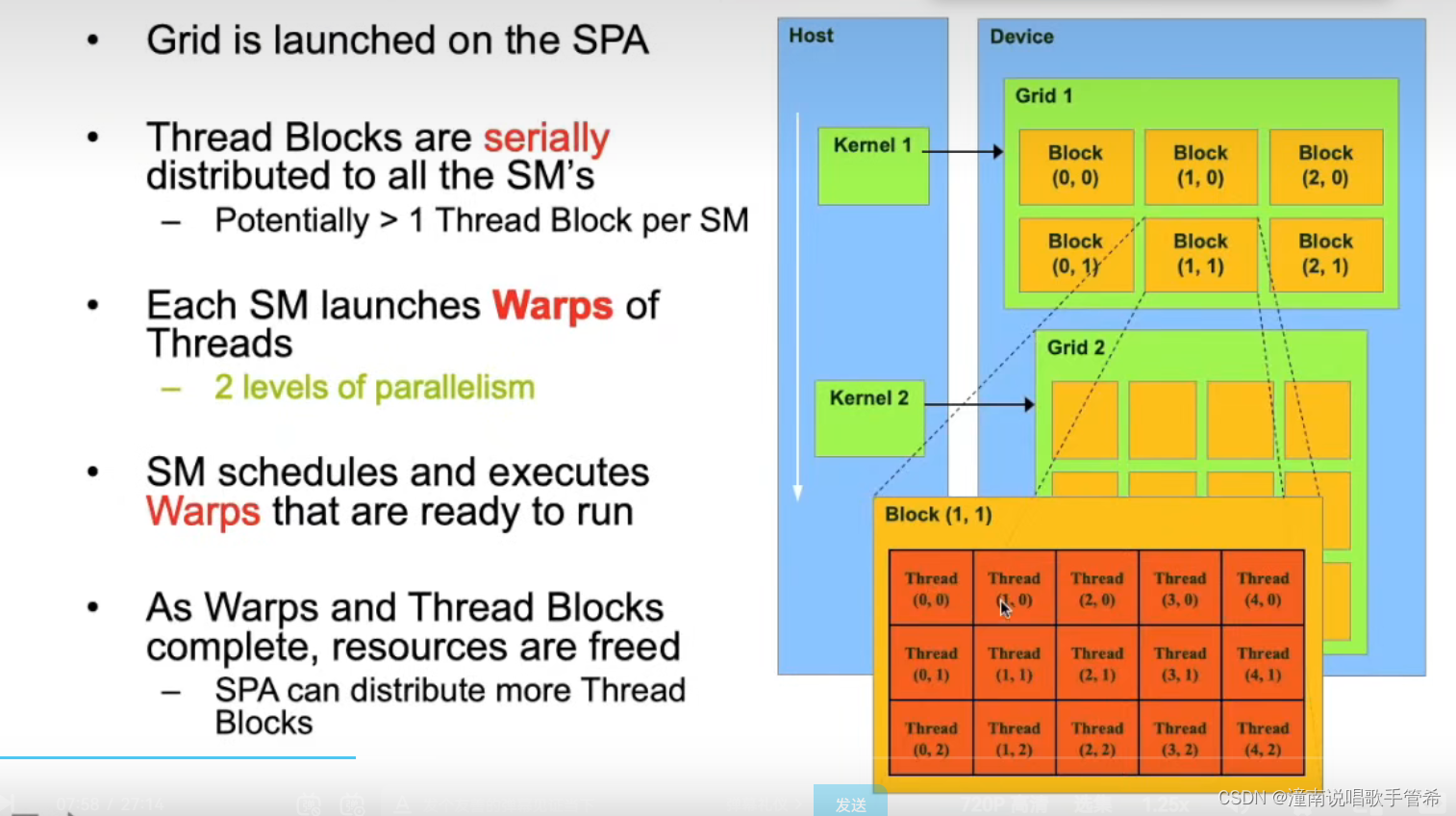
Bolck排序,Blcok中 thread也是排序的,32个thread组成一个wrap
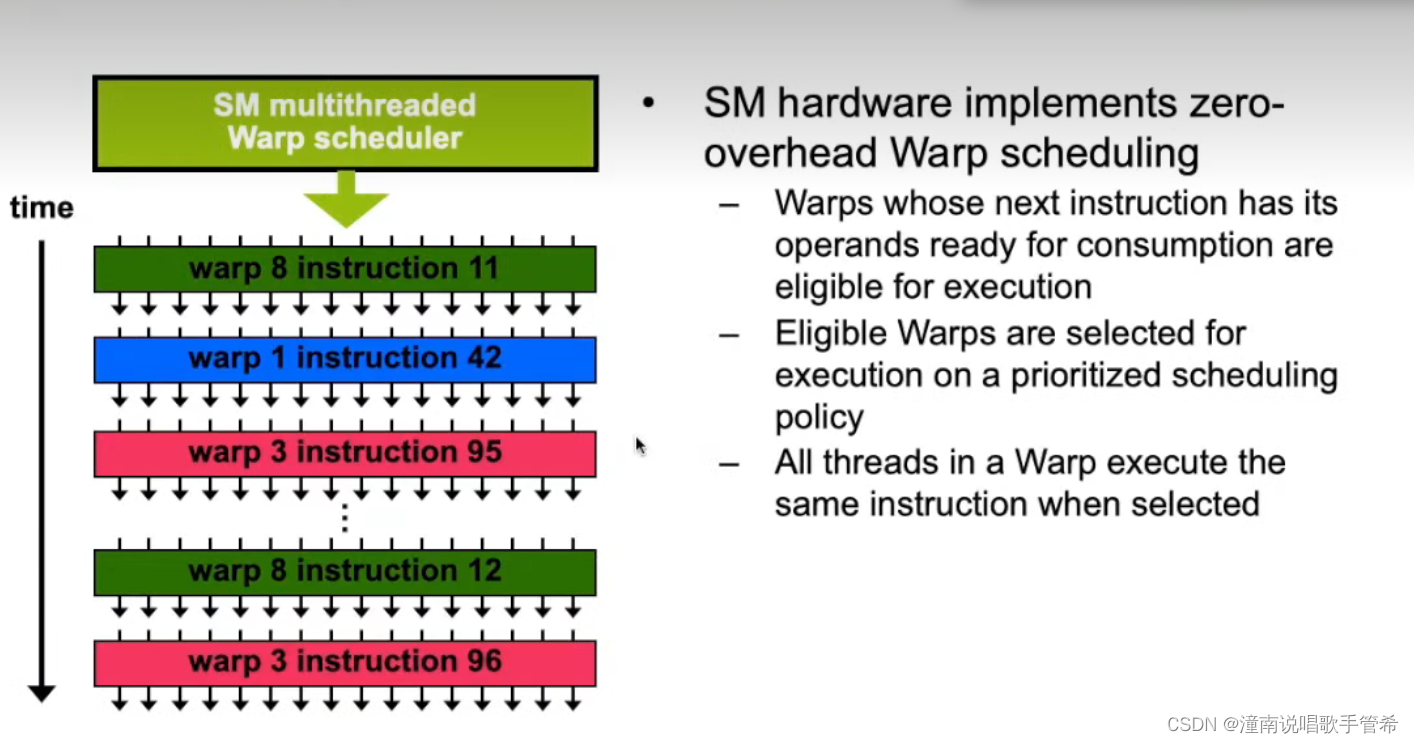
wrap调度器对wrap进行调度,按照优先级,一个wrap中所有的线程执行相同的命令,如果有if else之类的指令,可能造成分散,串行执行造成效率降低
在计算科学中,执行程序的基本三级结构是块、网格和节点。它们通常用于描述并行计算应用中的数据分割和任务分配。
块(Block):块是一个二维或三维的局部计算区域,通常包含许多相邻的处理器。块通常用于将计算区域分为小块,每个块由一个处理器或多个处理器共同处理。
块不能太大也不能太小 一般都是128 256
网格(Grid):网格是多个块的集合,在三维空间中可以看作是一个立体形状的网格结构。一个网格通常由数千个块组成,每个块可能包含数百个处理器,这些处理器可以并行执行同样的任务。
节点(Node):节点是物理上的计算单元,在分布式计算环境中通常指存储处理器、内存和网络互联的服务器。多个节点可以形成一个集群,一个程序可以在这个集群上并行运行,每个节点负责对应的计算任务。
这三个概念通常被用于解决大规模计算问题。通过将计算区域分解为块,每个块由一个或多个处理器执行,可以实现更高效的并行计算。而将块组合成网格,可以进一步增加并行计算的规模和效率。最后,将多个节点连接到一起形成一个集群,可以在更大的计算资源上执行并行计算任务。
在 CUDA 中,实现 GPU 上的并行计算时通常可以使用两个级别的并行性:线程块级别并行和线程级别并行。
线程块级别并行:线程块级别并行是指将数据分为多个块(Block),每个块由多个线程(Thread)组成。每个线程块可以独立处理其分配的数据块,从而实现更高效的并行计算。在处理大量数据时,线程块级别并行通常会带来显著的性能提升。
线程级别并行:线程级别并行是指在每个线程块内部使用多个线程来处理数据。这些线程可以协同工作以实现更高效的计算,并共享局部内存。线程级别并行通常用于实现单个线程块内的计算密集型任务,并且它们通常需要使用同步机制进行协同工作。
应该注意的是,线程块级别并行和线程级别并行之间存在紧密耦合关系。GPU 上的计算任务通常需要同时使用这两个级别的并行性,以充分利用 GPU 的计算资源。例如,在具有许多线程块的情况下,一些线程块可以通过线程级别并行来处理其内部的数据,从而提高整体性能。
因此,在使用 CUDA 进行并行计算时,需要仔细考虑如何合理地利用线程块级别并行和线程级别并行。正确使用这两个级别的并行性可以显著提高程序的性能和可扩展性。
wrap调度 zero-overhead零开销
访问缓存,速度快不要浪费,比方说读到5个内存,你就用了1个

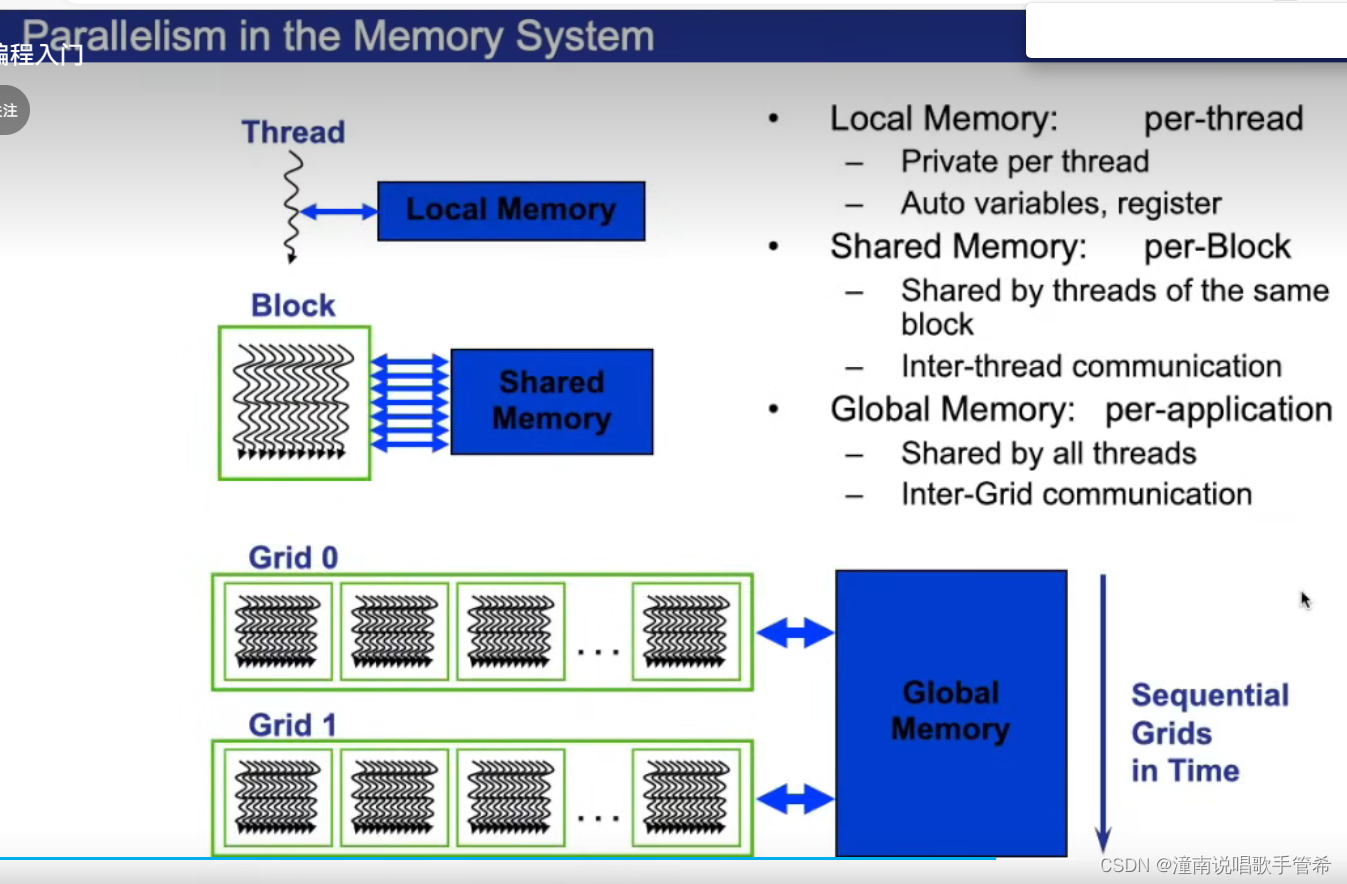
在一个块内,每个线程有自己的局部内存,块还有自己的共享内存,和l1访问速度一样。
GPU不提供全局同步,但是可以算出局部内存的和再加起来。
使用共享内存比全局内存快很多,至少两个数量级,但是共享内存较小

如果每个块需要的寄存器越多,那么处于活跃的块数目较少,降低运行度。
保持多的块活跃减少切换的开销


每4个字节或32个比特分为一个bank
同时有几个线程访问同一个内存地址会造成冲突,只能以串行的方式,造成效率降低。如果访问不同的bank就不会存在该问题,1个时钟周期就可以
早期的分为前半个与后半个wrap,每半个访问有要求,

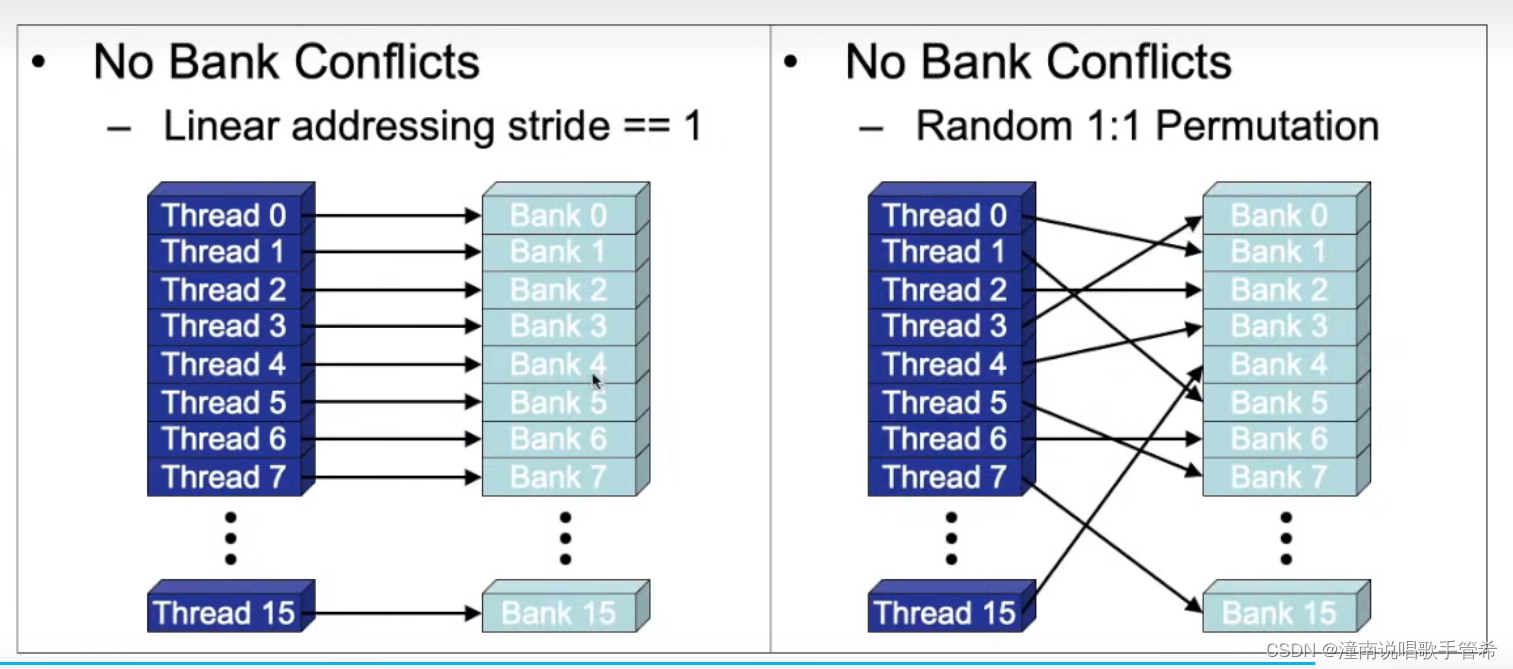
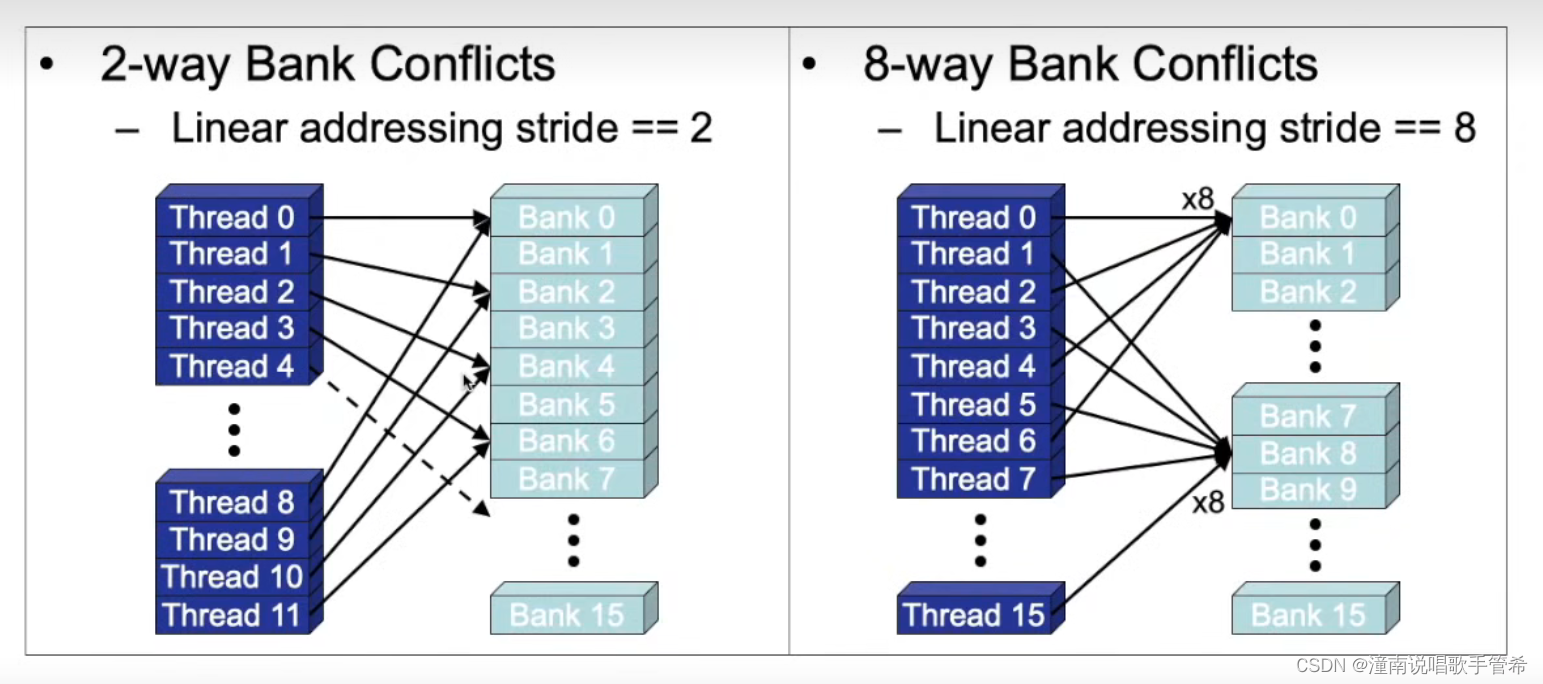
最近的GPU可能就不见得,可以通过广播的方式提高效率,减少时间。

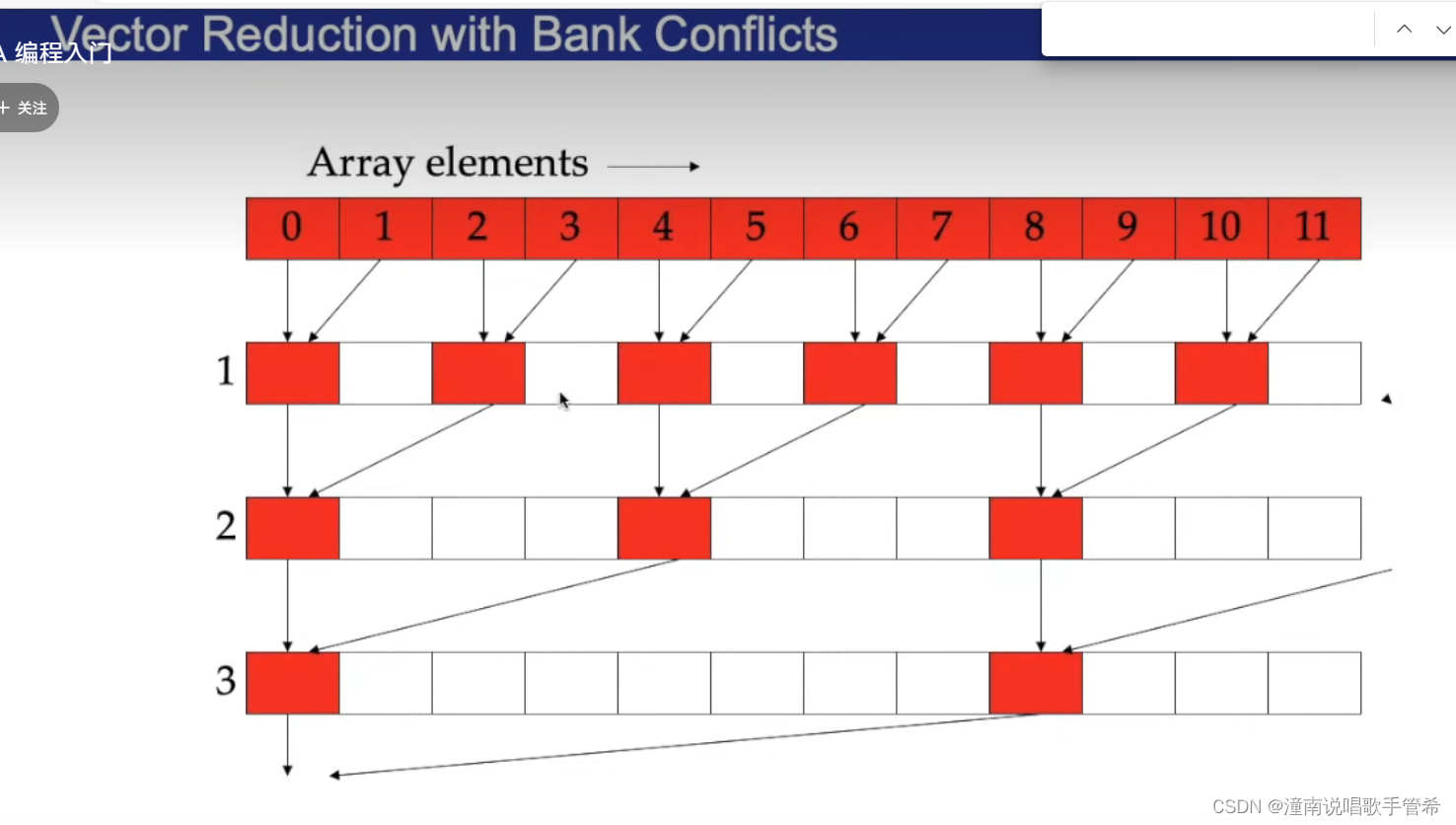
二叉树方式算出来
按照该方式访问可能存在冲突。
规约方式,通过对齐的方式减少
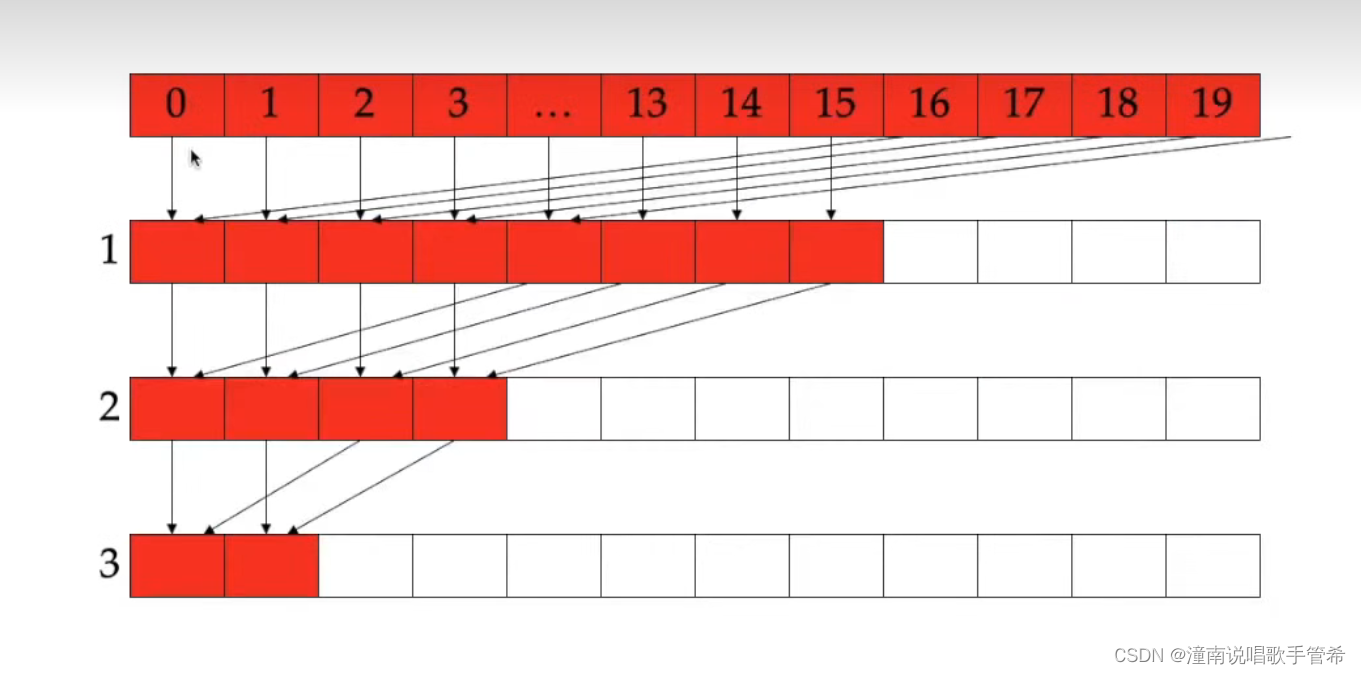
进程1访问的是内存0和16
cuda编程模型



global返回类型必须是void

启动了超过1百万个线程
bs一个块有多少线程,每个块有多大
gs有多少块
多少个网格 1维的网格和进程快
得到每个线程全局唯一的编号



32=6 block
53= 15
6*15=90
cuda程序层次结构

cpu 作为host调用完就走了,不管你是否执行完
device只能在gpu上执行和调用
cuda内置变量

线程和数据建立 一 一 对应关系
假设block是一维的,grid是二维的,

block id
在 CUDA 编程中,要获取当前线程块(block)在二维网格(grid)中的 ID,可以使用以下公式:
int block_id = blockIdx.x + blockIdx.y * gridDim.x;
这里的 blockIdx 是一个包含当前线程块的在网格中的二维索引的 CUDA 内置变量,其中 blockIdx.x 是当前线程块在 x 轴上的索引,blockIdx.y 是当前线程块在 y 轴上的索引。而 gridDim 是一个包含网格的尺寸的 CUDA 内置变量,其中 gridDim.x 是网格尺寸在 x 轴上的大小,gridDim.y 是网格尺寸在 y 轴上的大小。
我们可以将二维网格中的坐标转换为一个线性索引,以便于在程序中使用。通过将当前线程块 x 轴和 y 轴上的索引乘以网格尺寸在 x 轴上的大小,再加上当前线程块在 x 轴上的索引,就可以得到当前线程块在一维数组中的索引,即:
block_id = blockIdx.x + blockIdx.y * gridDim.x;
这个公式使用了基本的行优先 (row-major) 映射方式,其中每行具有固定数量的元素,我们可以认为是网格在内存中按行排列。这种映射方式通常用于矩阵计算和图形处理等任务中。
总之,blockIdx.x + blockIdx.y * gridDim.x 是用于在 CUDA 程序中获取当前二维网格中线程块 ID 的公式,它使用基本的行优先映射方式,将二维坐标转换为线性索引。这个公式可以帮助我们在 CUDA 编程中方便地访问当前线程块的 ID,并进一步实现并行计算。
blockIdx.x + blockIdx.y * gridDim.x 是一个在 CUDA 编程中常用的公式,用于计算当前线程块在二维网格中的唯一 ID。这个公式是通过将线程块在二维网格中的坐标转换为一个唯一的线性 ID 来实现的。具体来说,blockIdx.x 代表线程块在 x 轴上的索引,blockIdx.y 代表线程块在 y 轴上的索引,gridDim.x 代表网格在 x 轴上的尺寸。
这个公式的实际意义上可以理解为:我们将二维网格中的每个线程块映射到一个唯一的线性位置上。由于线性位置是一个一维的索引,因此需要将二维坐标映射到一维索引上,这就需要一定的算法。在这里我们采用的是基本的行优先 (row-major) 映射方式,在这种映射方式下,每行具有固定数量的元素,我们可以认为是网格在内存中按行排列。因此,我们需要将线程块在 y 轴上的坐标乘以网格在 x 轴上的尺寸,然后加上线程块在 x 轴上的索引,这样就可以得到线性位置的值,即:
int block_id = blockIdx.x + blockIdx.y * gridDim.x;
这个公式的结果是一个唯一的线性 ID,用于标识当前线程块在二维网格中的位置。可以根据这个 ID 对线程块进行排序、分配任务等操作,从而实现并行计算。
总之,blockIdx.x + blockIdx.y * gridDim.x 是一个用于计算当前线程块在二维网格中的唯一 ID 的公式,它将线程块在二维网格中的坐标映射到一个唯一的线性位置上,这个公式使用了基本的行优先映射方式。这个公式是在 CUDA 的定义中就已经固定下来的,而其实际意义则是用于实现并行计算中线程块的排序和分配等操作。
行优先
“行优先”是一种常用的存储方式,也被称为“按行存储”或者“逐行存储”,它在更广义上也可以被应用于数据结构中。
在计算机内部,所有的数据都会以二进制的形式存在内存中。我们需要通过一定的方式来将数据组织成可用的数据结构,以便程序能够方便地访问和操作。其中之一就是行优先存储方式。
在行优先存储方式中,数据会按照行的顺序依次排列在内存中。假设有一个 2D 数组 A,它的大小为 m x n(即有 m 行、n 列)。那么,在行优先存储方式中,数组中的元素会被按照以下方式存储:
A[0][0], A[0][1], ..., A[0][n-1], A[1][0], A[1][1], ..., A[1][n-1], ..., A[m-1][0], A[m-1][1], ..., A[m-1][n-1]
每一行的元素会按照顺序排列在一起,而每一列的元素则会交替出现,因此称为“行优先”。
行优先存储方式在很多编程任务中都比较常用,例如在图像处理和矩阵计算等领域中,因为它非常方便地支持一些操作,比如矩阵乘法和转置等。
在 CUDA 编程中,行优先存储方式也被广泛应用。例如,在计算机视觉中,我们可以将图像分割成若干个大小相同的块,然后将这些块按行优先的方式存储到 GPU 的内存中,便于并行计算和加速处理。
总之,行优先存储方式是一种将数据按照行的顺序存储到内存中的方式,在很多编程任务中都比较常用,同时也在 CUDA 编程中被广泛应用。
在行优先存储方式中,数组的每一行都按照相同的顺序排列在一起,因此每一行必须具有相同数量的元素,才能满足固定映射的要求。
具体来讲,假设数组 A 的大小为 m x n,那么在行优先存储方式中,第 i 行的数据会被存储在内存的第 i * n 个位置开始的连续 n 个位置上。这样一来,每一行就必须具有相同数量的元素,否则在存储到内存中时就无法一一对应。
举个例子,假设有如下的二维数组:
int A[2][3] = {
{1, 2, 3},
{4, 5, 6}
};
在行优先存储方式下,这个数组的元素会被存储成如下形式:
1 2 3 4 5 6
其中,每行均具有 3 个元素,因为数组定义时指定了每行的元素数量是 3。如果我们将第二行的元素数量修改为 4,代码如下:
int A[2][4] = {
{1, 2, 3},
{4, 5, 6, 7}
};
那么在行优先存储方式下,这个数组的元素就无法一一对应地存储到内存中了,因为第二行的数据量发生了改变。
综上所述,由于行优先存储方式需要将每一行的数据按照相同的顺序排列在一起,因此必须要求每行具有相同数量的元素,这样才能满足固定映射的要求,并且被方便地存储到内存中。
编号计算
在 CUDA 编程中,线程的执行需要以线程块(block)和线程网格(grid)的形式组织。其中,线程块是指一组具有相同程序控制流的线程,它们可以共同访问共享内存,并支持同步操作。而线程网格则是由多个线程块组成的二维数组,用于描述并发执行的线程总数。
在这样的编程模型下,可以通过使用内置的变量 threadIdx 和 blockIdx 来获取线程的 ID。其中,threadIdx 变量可以返回当前线程在其所属线程块中的索引,而 blockIdx 变量则可以返回当前线程所属的线程块在线程网格中的索引。使用这两个变量可以以一种简单的方式来获取线程的 ID,即:
- 对于一维线程块和一维线程网格:线程 ID =
blockIdx.x * blockDim.x + threadIdx.x。 - 对于二维线程块和二维线程网格:线程 ID =
(blockIdx.y * gridDim.x + blockIdx.x) * (blockDim.x * blockDim.y) + threadIdx.y * blockDim.x + threadIdx.x。
其中,blockDim 表示线程块的大小,gridDim 表示线程网格的大小,它们都是 CUDA 中的内置变量。需要注意的是,在 CUDA 中,线程块和线程网格的大小都必须事先确定,并且不同的 GPU 可以支持的大小也有所不同,因此在编程时需要根据具体的 GPU 确定合适的线程块和线程网格大小。
综上所述,CUDA 编程中的 get thread id 指的是通过内置变量 threadIdx 和 blockIdx 来获取线程的 ID,针对一维线程块和一维线程网格或者二维线程块和二维线程网格,可以使用不同的公式来计算线程 ID。
编号计算2
你提到的这个公式是用于在 2D 网格中获取线程 ID 的计算公式。具体来说,这个公式可以分解为如下三个部分:
-
blockIdx.x + blockIdx.y * gridDim.x:该部分用于计算当前线程块在整个网格中的坐标(假设线程块索引从(0, 0)开始)。其中,blockIdx.x表示当前线程块在 x 方向上的编号,blockIdx.y表示当前线程块在 y 方向上的编号,gridDim.x表示整个网格在 x 方向上的线程块数目。 -
blockDim.x:表示每个线程块中沿着 x 方向上的线程数目。 -
threadIdx.x:表示当前线程在其所属线程块中的编号(假设线程索引从0开始)。
将以上三个部分相加即可得到当前线程在整个网格中的唯一编号。需要注意的是,这个公式假定线程块和线程网格大小都是二维的(即 blockDim 和 gridDim 都是二维的 dim3 类型)。如果线程块或线程网格大小在某个方向上是一维的,则可以类似地修改公式来计算不同维度上的线程 ID。
总之,CUDA 编程中的计算量较大,需要使用多个线程并行计算。为了能够组织这些线程以有效地利用 GPU 的计算资源,我们需要使用线程块和线程网格来划分线程的执行。线程块和网格的大小可以通过 dim3 类型的变量来定义,线程块内部的线程可以使用内置的变量 threadIdx 来获取自己在线程块内的编号,而线程块本身则可以使用内置的变量 blockIdx 和 gridDim 来获取自己在整个网格中的编号和网格的大小。利用这些信息,我们可以设计出各种复杂的并行计算方案,并高效地利用 GPU 的计算资源进行计算。
这个公式也是用于在二维网格中获取线程 ID 的计算公式。
与之前的公式相比,最主要的区别在于它将 blockIdx.x 和 blockIdx.y 的计算顺序调换了一下。具体来说,该公式的计算过程如下:
-
首先,根据
blockIdx.x和blockIdx.y,计算当前线程块在整个网格中的唯一编号:blockIdx.x + blockIdx.y * gridDim.x; -
然后,将上面计算得到的编号乘以每个线程块中沿着 x 方向上的线程数目
blockDim.x,得到该线程块在整个网格中的偏移量; -
最后,加上当前线程在其所属线程块内的编号
threadIdx.x,即可得到当前线程在整个网格中的唯一编号。
需要注意的是,该公式假定线程块和线程网格大小都是二维的(即 blockDim 和 gridDim 都是二维的 dim3 类型),且线程块内部沿着 x 方向展开线程。
总之,CUDA 编程中使用线程块和线程网格来划分线程的执行,使用不同的公式可以获取当前线程在整个网格中的唯一编号。对于不同的应用场景,我们可以根据需要选择合适的公式来计算线程 ID,以便进行高效的并行计算。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









