







课程地址:https://class.coursera.org/ntumlone-001/class
课件讲义:http://download.csdn.net/download/malele4th/10212756
注明:文中图片来自《机器学习技法》课程和部分博客
建议:建议读者学习林轩田老师原课程,本文对原课程有自己的改动和理解
Lecture 4 soft-margin SVM
上节课我们主要介绍了Kernel SVM。先将特征转换和计算内积这两个步骤合并起来,简化计算、提高计算速度,再用Dual SVM的求解方法来解决。Kernel SVM不仅能解决简单的线性分类问题,也可以求解非常复杂甚至是无限多维的分类问题,关键在于核函数的选择,例如线性核函数、多项式核函数和高斯核函数等等。但是,我们之前讲的这些方法都是Hard-Margin SVM,即必须将所有的样本都分类正确才行。这往往需要更多更复杂的特征转换,甚至造成过拟合。本节课将介绍一种Soft-Margin SVM,目的是让分类错误的点越少越好,而不是必须将所有点分类正确,也就是允许有noise存在。这种做法很大程度上不会使模型过于复杂,不会造成过拟合,而且分类效果是令人满意的。
目录
1 Motivation and Primal Problem(动机和原始问题)
上节课我们说明了一点,就是SVM同样可能会造成overfit。原因有两个,一个是由于我们的SVM模型(即kernel)过于复杂,转换的维度太多,过于powerful了;另外一个是由于我们坚持要将所有的样本都分类正确,即不允许错误存在,造成模型过于复杂。如下图所示,左边的图Φ1是线性的,虽然有几个点分类错误,但是大部分都能完全分开。右边的图Φ4是四次多项式,所有点都分类正确了,但是模型比较复杂,可能造成过拟合。直观上来说,左边的图是更合理的模型。

如何避免过拟合?方法是允许有分类错误的点,即把某些点当作是noise,放弃这些noise点,但是尽量让这些noise个数越少越好。回顾一下我们在机器学习基石笔记中介绍的pocket算法,pocket的思想不是将所有点完全分开,而是找到一条分类线能让分类错误的点最少。而Hard-Margin SVM的目标是将所有点都完全分开,不允许有错误点存在。为了防止过拟合,我们可以借鉴pocket的思想,即允许有犯错误的点,目标是让这些点越少越好。

为了引入允许犯错误的点,我们将Hard-Margin SVM的目标和条件做一些结合和修正,转换为如下形式:
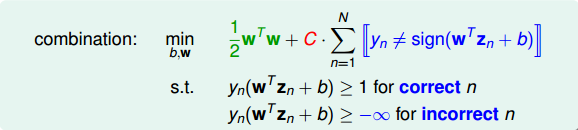
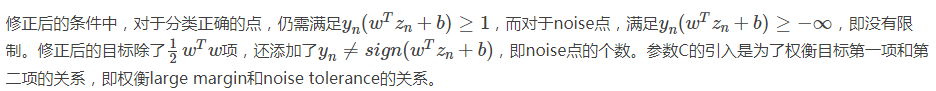
我们再对上述的条件做修正,将两个条件合并,得到:
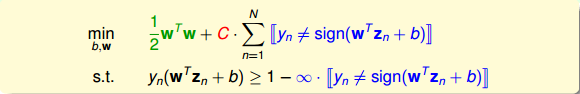
这个式子存在两个不足的地方。首先,最小化目标中第二项是非线性的,不满足QP的条件,所以无法使用dual或者kernel SVM来计算。然后,对于犯错误的点,有的离边界很近,即error小,而有的离边界很远,error很大,上式的条件和目标没有区分small error和large error。这种分类效果是不完美的。

为了改正这些不足,我们继续做如下修正:


其中, ξn 表示每个点犯错误的程度, ξn=0 ,表示没有错误, ξn 越大,表示错误越大,即点距离边界(负的)越大。参数C表示尽可能选择宽边界和尽可能不要犯错两者之间的权衡,因为边界宽了,往往犯错误的点会增加。large C表示希望得到更少的分类错误,即不惜选择窄边界也要尽可能把更多点正确分类;small C表示希望得到更宽的边界,即不惜增加错误点个数也要选择更宽的分类边界。
与之对应的QP问题中,由于新的参数 ξn 的引入,总共参数个数为d^+1+N,限制条件添加了 ξn≥0 ,则总条件个数为2N。

2 Dual problem
接下来,我们将推导Soft-Margin SVM的对偶dual形式,从而让QP计算更加简单,并便于引入kernel算法。首先,我们把Soft-Margin SVM的原始形式写出来:
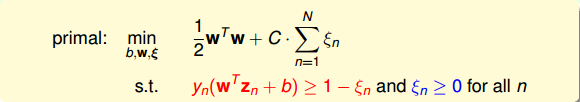
然后,跟我们在第二节课中介绍的Hard-Margin SVM做法一样,构造一个拉格朗日函数。
因为引入了 ξn ,原始问题有两类条件,所以包含了两个拉格朗日因子 αn 和 βn 。拉格朗日函数可表示为如下形式:
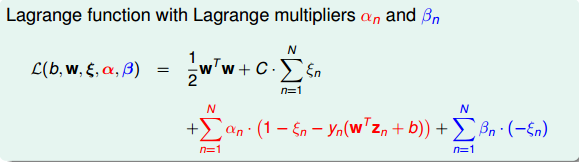
接下来,我们跟第二节课中的做法一样,利用Lagrange dual problem,将Soft-Margin SVM问题转换为如下形式:
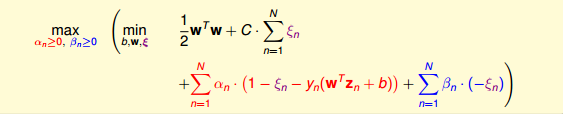

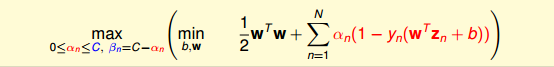

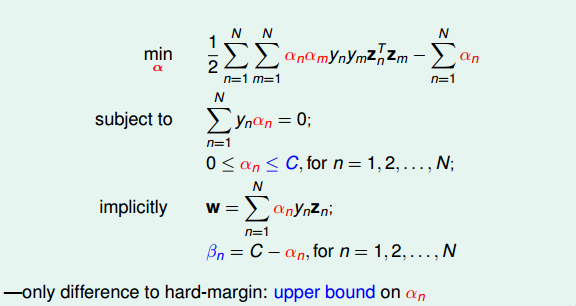

3 Messages behind Soft-Margin SVM
推导完Soft-Margin SVM Dual的简化形式后,就可以利用QP,找到Q,p,A,c对应的值,用软件工具包得到αn的值。或者利用核函数的方式,同样可以简化计算,优化分类效果。Soft-Margin SVM Dual计算αn的方法过程与Hard-Margin SVM Dual的过程是相同的。



接下来,我们看看C取不同的值对margin的影响。例如,对于Soft-Margin Gaussian SVM,C分别取1,10,100时,相应的margin如下图所示:
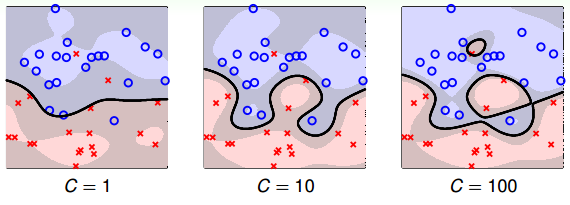
从上图可以看出,C=1时,margin比较粗,但是分类错误的点也比较多,当C越来越大的时候,margin越来越细,分类错误的点也在减少。正如前面介绍的,C值反映了margin和分类正确的一个权衡。C越小,越倾向于得到粗的margin,宁可增加分类错误的点;C越大,越倾向于得到高的分类正确率,宁可margin很细。我们发现,当C值很大的时候,虽然分类正确率提高,但很可能把noise也进行了处理,从而可能造成过拟合。也就是说Soft-Margin Gaussian SVM同样可能会出现过拟合现象,所以参数(γ,C)的选择非常重要。

所以,在Soft-Margin SVM Dual中,根据αn的取值,就可以推断数据点在空间的分布情况。

4 model Selection
在Soft-Margin SVM Dual中,kernel的选择、C等参数的选择都非常重要,直接影响分类效果。例如,对于Gaussian SVM,不同的参数(C,γ),会得到不同的margin,如下图所示。
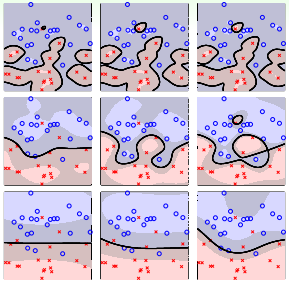
其中横坐标是C逐渐增大的情况,纵坐标是γ逐渐增大的情况。不同的(C,γ)组合,margin的差别很大。那么如何选择最好的(C,γ)等参数呢?最简单最好用的工具就是validation。
validation我们在机器学习基石课程中已经介绍过,只需要将由不同(C,γ)等参数得到的模型在验证集上进行cross validation,选取
Ecv
最小的对应的模型就可以了。例如上图中各种(C,γ)组合得到的
Ecv
如下图所示:

因为左下角的Ecv(C,γ)最小,所以就选择该(C,γ)对应的模型。通常来说,Ecv(C,γ)并不是(C,γ)的连续函数,很难使用最优化选择(例如梯度下降)。一般做法是选取不同的离散的(C,γ)值进行组合,得到最小的Ecv(C,γ),其对应的模型即为最佳模型。这种算法就是我们之前在机器学习基石中介绍过的V-Fold cross validation,在SVM中使用非常广泛。
V-Fold cross validation的一种极限就是Leave-One-Out CV,也就是验证集只有一个样本。对于SVM问题,它的验证集Error满足:
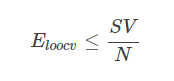

SV的数量在SVM模型选择中也是很重要的。一般来说,SV越多,表示模型可能越复杂,越有可能会造成过拟合。所以,通常选择SV数量较少的模型,然后在剩下的模型中使用cross-validation,比较选择最佳模型。
5 总结
本节课主要介绍了Soft-Margin SVM。我们的出发点是与Hard-Margin SVM不同,不一定要将所有的样本点都完全分开,允许有分类错误的点,而使margin比较宽。然后,我们增加了 ξn 作为分类错误的惩罚项,根据之前介绍的Dual SVM,推导出了Soft-Margin SVM的QP形式。得到的 αn 除了要满足大于零,还有一个上界C。接着介绍了通过 αn 值的大小,可以将数据点分为三种:non-SVs,free SVs,bounded SVs,这种更清晰的物理解释便于数据分析。最后介绍了如何选择合适的SVM模型,通常的办法是cross-validation和利用SV的数量进行筛选。















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









