






 本文提出了一种名为HTS的方法,通过构建分层树结构来学习预设任务生成的特征表示,以优化小样本图像分类。HTS利用门控选择聚合组件,自适应地选择和融合特征,从而在FSL任务中实现更好的性能。实验结果显示,HTS在数据增强和自监督学习背景下,无论是单域还是跨域,都能显著提高少样本学习效果。
本文提出了一种名为HTS的方法,通过构建分层树结构来学习预设任务生成的特征表示,以优化小样本图像分类。HTS利用门控选择聚合组件,自适应地选择和融合特征,从而在FSL任务中实现更好的性能。实验结果显示,HTS在数据增强和自监督学习背景下,无论是单域还是跨域,都能显著提高少样本学习效果。
本文主要是讨论如何通过pretext tasks学习额外的特征表示以提高小样本图像分类的能力。基于此,本文提出了插件分层树结构感知(HTS)方法,该方法不仅可以学习FSL和借口任务之间的关系,还可以自适应地选择并聚合由借口任务产生的特征表示,从而最大化FSL任务的性能。引入了分层树构建组件和门控选择聚合组件来构建树结构,并找到更丰富的可转移知识,可以快速适应具有少量标记图像的新类。
分层树构建组件:这一组件的目标是为每个原始图像构建一个树结构,使得可以利用树的边来连接不同增强图像之间的特征信息,并利用树的级别表示从不同的pretext tasks中学习到的特征。当pretext tasks或增强图像发生变化时(例如添加、删除或修改),HTS方法能够灵活地调整树的层次或节点数量。树的结构为{Eφ(xi) g1→ Eφ(x1i ) g2→ · · · gj→ Eφ(xj i ) · · · gJ→ Eφ(xJ i )}
门控选择聚合组件:在本文中,使用了基于Tree-based Long Short Term Memory (TreeLSTM)作为门控聚合器。该组件的目的是有效利用树结构进行学习和推理,通过保留树结构信息以模拟FSL和增强图像之间的关系,并通过选择性聚合所有子节点的信息自底向上提升父节点的性能。
聚合过程形式化为:{h0i agg←− h1i agg←− · · · agg←− hr i · · · agg←−Eφ(xJ i )}
选择TreeLSTM的原因:
- 来自不同借口任务的增强图像可以组织成树结构中具有可变长度的序列。
- TreeLSTM 为每个子节点生成一个遗忘门,允许它从相应的子节点过滤信息。这种顺序聚合增强了上层节点的输出。
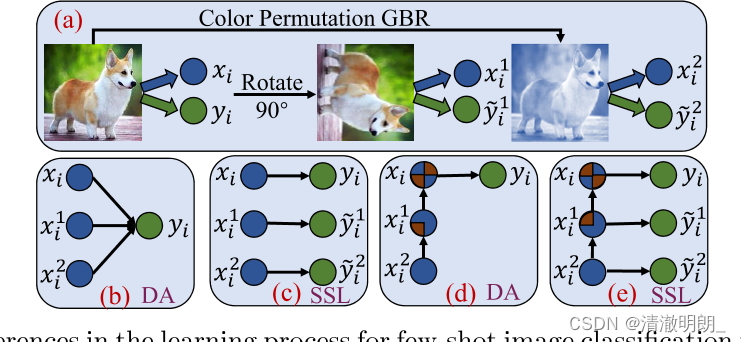
图1 :使用以前工作和我们的工作之间的借口任务进行少样本图像分类的学习过程差异。(a) 显示了使用 FSL 图像生成增强图像的过程。(b) 和 (c) 显示了 DA 或 SSL 设置下先前工作的学习过程,它不加选择地使用所有图像。(d) 和 (e) 显示了我们在 DA 或 SSL 设置下工作的学习过程,可以利用分层树结构自适应地选择有用的特征表示。
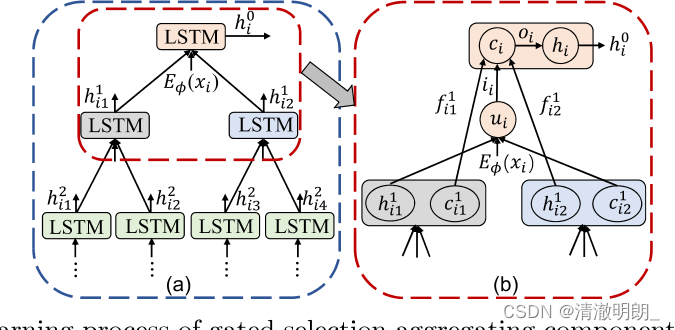
图2所示。门控选择聚合组件的学习过程。(a) 表明聚合器从底层顺序和分层聚合信息。(b) 详细说明了 TreeLSTM 的内部聚合(例如,两个级别)。图中标记的下标表示子节点的数量,上标表示级别的数量,不同的颜色是不同的 LSTM 单元。
创新点:
-
提出了HTS方法:本文提出了一种新的方法,即基于Hierarchical Tree Structure-aware(HTS)的方法,用于增强少样本学习任务的性能。HTS方法通过构建树结构来建模原始图像和增强图像之间的关系,并采用门控选择聚合组件来自适应地选择和聚合特征表示,以最大化少样本学习任务的性能。
-
使用预设任务增强特征表示:本文利用预设任务(如数据增强和自监督学习)来生成增强图像,并将这些图像用于增强少样本学习任务的性能。与传统的方法不同,本文不仅仅是简单地将增强图像与原始图像混合在一起,而是通过HTS方法来有效地利用增强图像的信息,从而提高模型的泛化能力。
-
建模图像之间的关系:HTS方法通过构建树结构来建模原始图像和增强图像之间的关系。这种树结构不仅能够捕捉图像之间的相似性和差异性,还可以有效地组织和利用图像的语义信息,从而提高模型的性能。
-
适用于各种少样本学习方法:HTS方法可以与任何基于元学习的少样本学习方法相结合,从而提高这些方法的性能。这使得HTS方法具有很强的通用性和灵活性,可以适用于各种不同类型的少样本学习任务。
DA与SSL的区别
- 数据增强(DA):通过应用各种变换或扰动(如旋转、镜像、颜色变换等)来生成增强图像,以扩充训练数据集。
- 自监督学习(SSL):设计自动生成标签或任务,利用数据本身的结构或属性,而不是依赖外部注释或标签。
实验:
-
实验设置和数据集选择:作者选择了四个常用的少样本图像分类基准数据集:mini ImageNet、tiered ImageNet、CUB-200-2011和CIFAR-FS。实验采用了5-way 1-shot和5-way 5-shot的设置,每个实验中含有15个未标记的查询图像。作者采用了Conv4和ResNet12作为编码器,并使用了PyTorch进行实现。
-
预训练任务选择:作者选择了旋转和颜色排列这两个常用的预训练任务,并将它们应用于图像增强。预训练任务的不同子集被用于不同的实验设置。
-
RQ1:预训练任务在FSL中的性能:作者对比了使用不同借口任务进行图像增强的方法在FSL任务上的性能。结果表明,并非所有借口任务都能带来良好的性能提升,我们需要为不同的数据集找到合适的借口任务。
-
RQ2:HTS在单域和跨域情况下的性能:作者评估了HTS方法在单域和跨域情况下的性能。实验结果表明,HTS方法在各种情况下都能够显著提高少样本学习的性能,并且在跨域设置下也表现出色。
-
RQ3:自适应选择聚合:作者通过可视化实验展示了HTS方法中门控选择聚合组件的自适应能力,证明了该方法可以自适应地学习不同子节点的特征表示。
-
RQ4:消融实验:作者进行了一系列的消融实验,评估了不同预训练任务、不同子节点数量和不同树级别对HTS方法性能的影响。实验结果表明,HTS方法在不同设置下都能够取得显著的性能提升。















 2335
2335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









