






摘要:
本文主要记录这一段时间对本地大模型搭建的心得。
作为一个资深程序员,在AI席卷全球的时候,深深感觉到了一丝危机感,不禁有一个想法不断在脑海闪现:我会不会真的哪一天被AI给取代了?
从哪入手
程序员出生的我,掌握了很多语言,从前端到数据库,再到运维,基本都能一个人搞定,所以,我对搭建一个AI程序还是很自信的。
于是,我开始研究各个比较火的大模型:Chatgpt3.5、chatgpt4.0、chatgpt4o、llama、通义千问、豆包、等等。
发现他们的api从以前的不收费到现在的慢慢开始收费,我相信,后面肯定会收费的。于是,我就有了搭建本地大模型的方法,用别人的再爽,那也是别人的,万一哪天,别人宕机了,或者涨价了,你是用还是不用呢?
调研本地安装方法
当有了搭建的想法之后,就是落地了。怎么安装本地大模型呢?于是各种搜索,,,,挺费时间的,还需要实践。不得不说,你们运气真好,碰到我了。
经过实践之后,我发掘了两套部署方式:
1、LmStudio ,这个简单,把这个工具下载下来,然后,再工具里面下载大模型就行了。
1.1工具下载地址:https://lmstudio.ai/
下载完之后,直接安装就行了。
打开之后的界面是这个样子:

1.2 这里需要点左边最后一个文件夹,修改一下你模型下载的地址,不然你下载的模型都会默认在C盘。

1.3 然后就是下载大模型了
在主页,你可以选择你要下载的大模型,然后下载。
下载半天你会发现,下载不了,爆红了:

此时不要着急,找到它下载的配置文件,一般在:C:\Users\你的电脑名称.cache\lm-studio。
打开下面的文件:

把所有的:huggingface.co换成:hf-mirror.com
保存后,重新打开LmStudio,点try_resume,发现可以下载了。

下载完之后,你就可以用啦。
2、ollama,这个稍微有点复杂
2.1 首先下载这个软件
地址是:https://ollama.com/download
下载完之后,安装。
这个是没有桌面快捷方式的,看到这个小猪就算成功:

安装完之后,配置环境变量,这个在我的电脑里面。
可以修改系统环境变量更改模型下载位置:OLLAMA_MODELS=D:\Ollama(自定义下载位置)
通过 ollama --verison 或 ollama -v 可以查看 ollama 版本。若运行时出现警告 Warning: could not connect to a running Ollama instance,是因为 ollama 没有运行,执行 ollama serve 命令运行 ollama 即可。
2.2 官网下载安装模型
本文依 codegemma为例,如果使用其他模型一样的操作
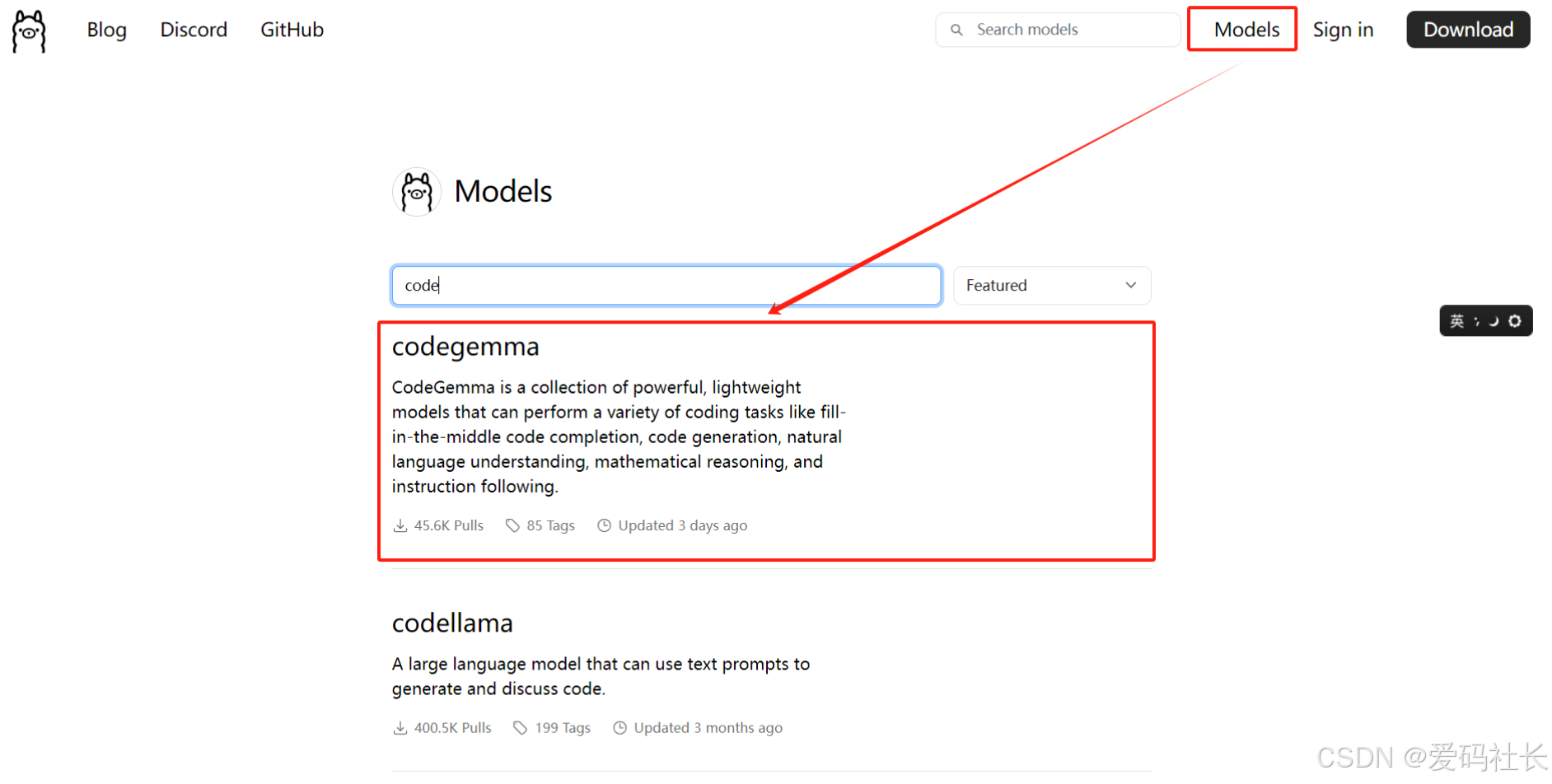
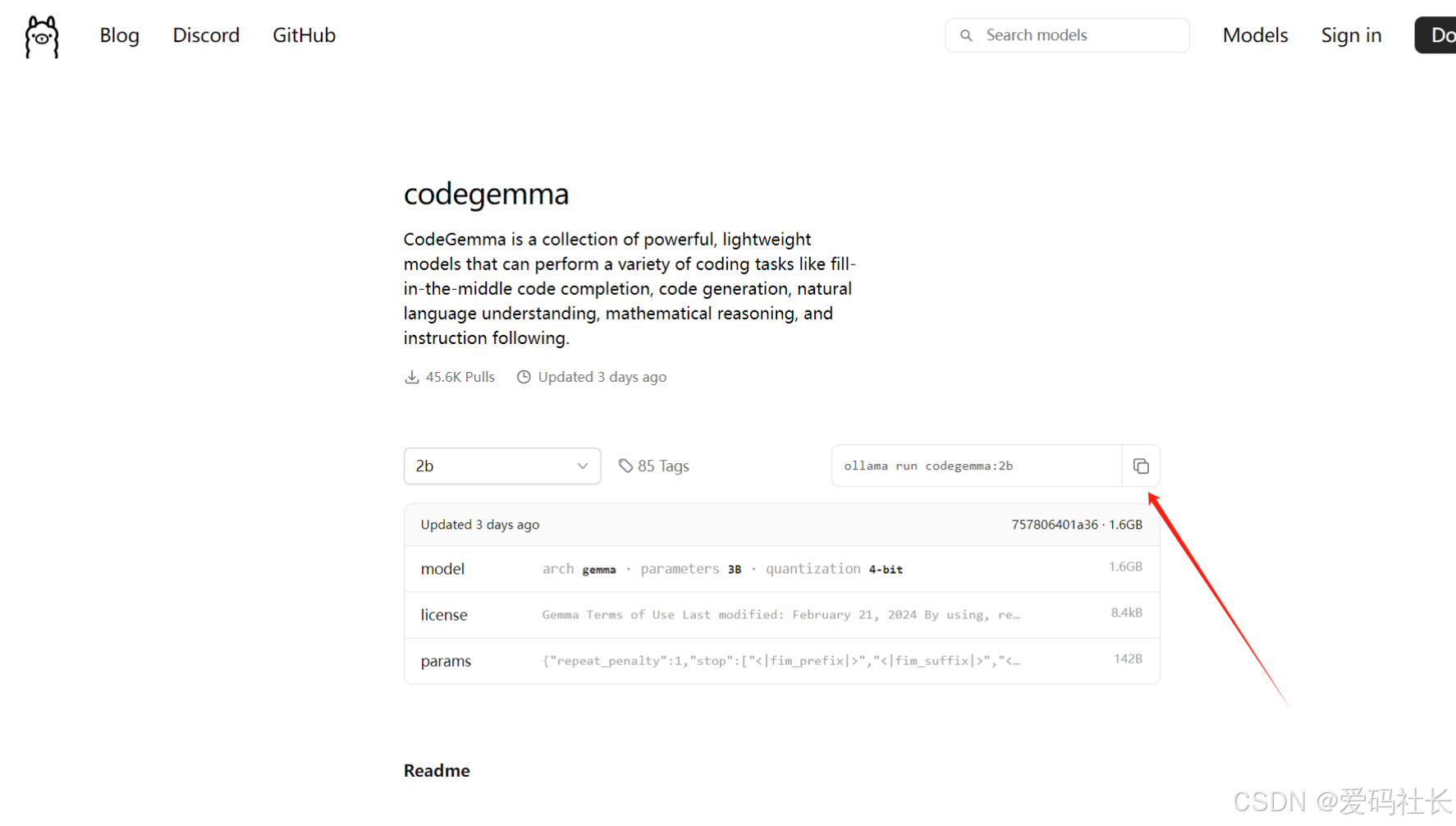
2b: 最低配,有点SB。不智能,不推荐
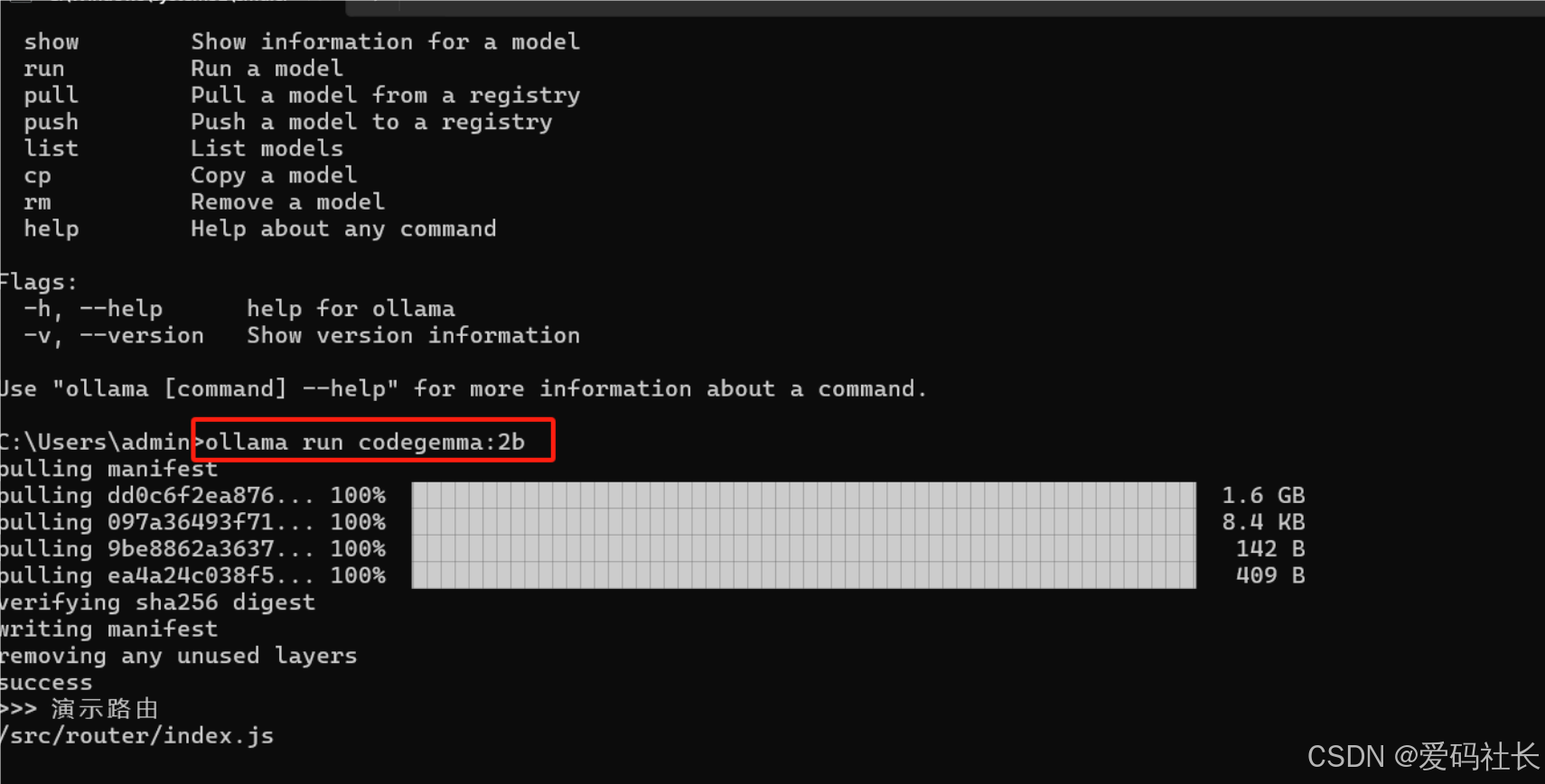
命令:ollama run codegemma:2b
7b: 内存8G以上,建议16G电脑上这个版本更好一点,碾压2b版本。预计占用1.5G内存,CPU要求高,低压U估计压不住,时间太长
命令:ollama run codegemma:7b
7b全量: 说是更智能,没体验。建议16G或者32G电脑上这个版本,cpu要求更高
命令:ollama run codegemma:7b-code-fp16
带instruct: 能够理解自然语言输入,并根据指令生成相应的代码。
带code: 预训练的模型,专门用于代码补全和根据代码前缀和/或后缀生成代码。
带2b: 最新的预训练模型,提供了最多两倍更快的代码自动补全功能。它的目标是提高代码补全的速度和效率。就是回复的有点拉胯
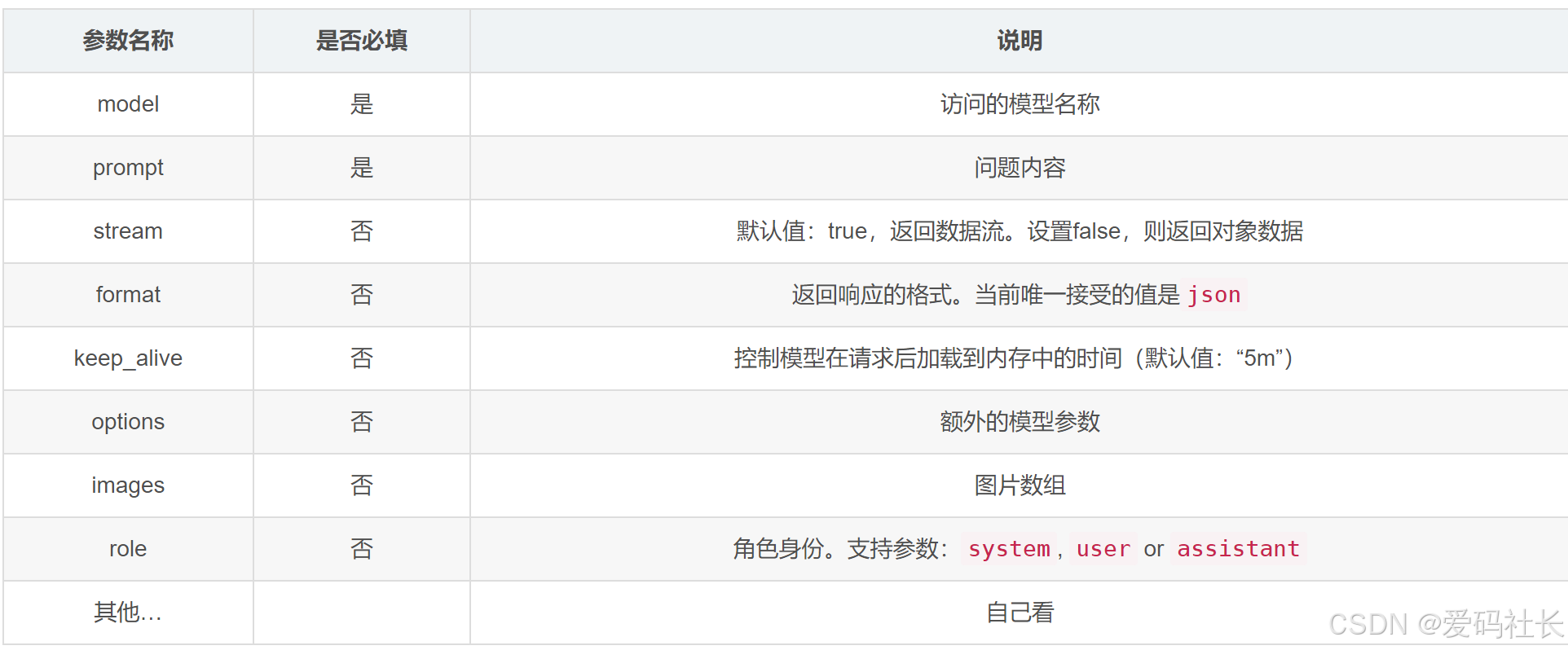
2.3 API接口调用:
由于实际使用命令行问答很不方便,改造成api调用。都是 POST 接口
/ai/generate:结果一起返回,等待时间较长
/ai/chat:对话模式,有一点结果就立马输出
详细api文档说明:https://github.com/ollama/ollama/blob/main/docs/api.md?plain=1
支持json数据返回、图片问答、row数据等
案例:
axios.post(`http://localhost:11434/api/generate`, {
model: "codegemma:7b",
prompt: "正则匹配大陆手机号码是否正确",
format: "json",
stream: false,
// options: {
// num_keep: 15,
// seed: 42,
// num_predict: 100,
// top_k: 20,
// top_p: 0.9,
// tfs_z: 0.5,
// typical_p: 0.7,
// repeat_last_n: 33,
// temperature: 0.8,
// repeat_penalty: 1.2,
// presence_penalty: 1.5,
// frequency_penalty: 1.0,
// mirostat: 1,
// mirostat_tau: 0.8,
// mirostat_eta: 0.6,
// penalize_newline: true,
// // stop: ["\n", "user:"],
// numa: false,
// num_ctx: 1024,
// num_batch: 2,
// num_gqa: 1,
// num_gpu: 1,
// main_gpu: 0,
// low_vram: false,
// f16_kv: true,
// vocab_only: false,
// use_mmap: true,
// use_mlock: false,
// rope_frequency_base: 1.1,
// rope_frequency_scale: 0.8,
// num_thread: 8,
// },
});
当然,ollama还可以搭配现有比较成熟的webui使用。
webui使用步骤
windows系统,需要安装win版的docker
webui 项目地址:https://github.com/open-webui/open-webui
使用CPU运行
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
使用GPU运行
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway --gpus=all -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
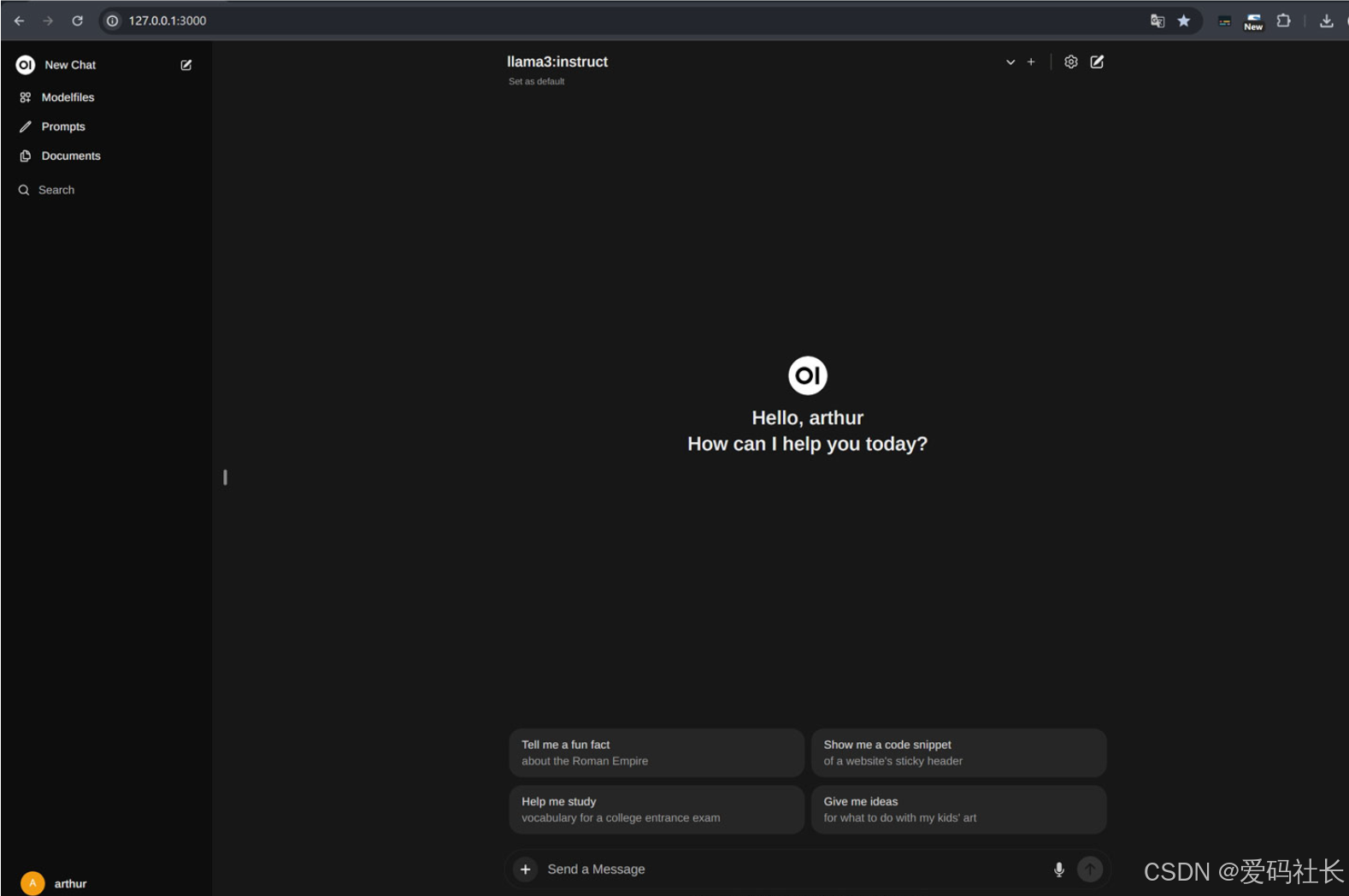
安装完成之后,可以通过本地地址:http://127.0.0.1:3000 进行访问
注:如果需要其他电脑也可以访问这个api,需要配置环境变量:OLLAMA_HOST
比如: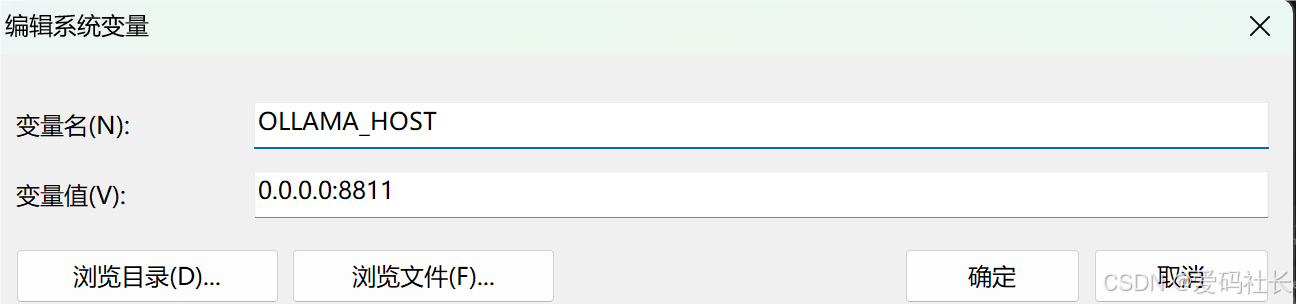
到此结束,你已经可以在本地玩大模型啦,有不懂的可以加我v,一起沟通哦。



















 1684
1684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











