







【论文阅读】NSTransformers
0. 论文基本信息

发表刊物:NeurIPS
发表年度:2022
论文地址:https://arxiv.org/abs/2205.14415
论文源码:https://github.com/thuml/Nonstationary_Transformers
1. 简介
论文提出了一种用于提升非平稳时序预测效果的模型架构。该模型架构适用于transformer相关时序模型,可以提升这类模型的预测效果,并通过多个模型和数据集实验验证了效果。
非平稳时间序列数据的数据分布和统计值会随着时间而发生变化,这加大了模型预测的难度。过去有很多研究探索了如何消除非平稳时序数据的非平稳性,大部分研究提出的方案都是在预处理阶段将时序数据进行预处理,例如归一化或标准化,从而使模型输入接近平稳。这些方法确实能提升时序数据的可预测性,但是会导致输入数据丢失了非平稳性信息(论文将该问题命名为过平稳,英文为over-stationarization),而这些信息对于最终预测有可能是有帮助的。
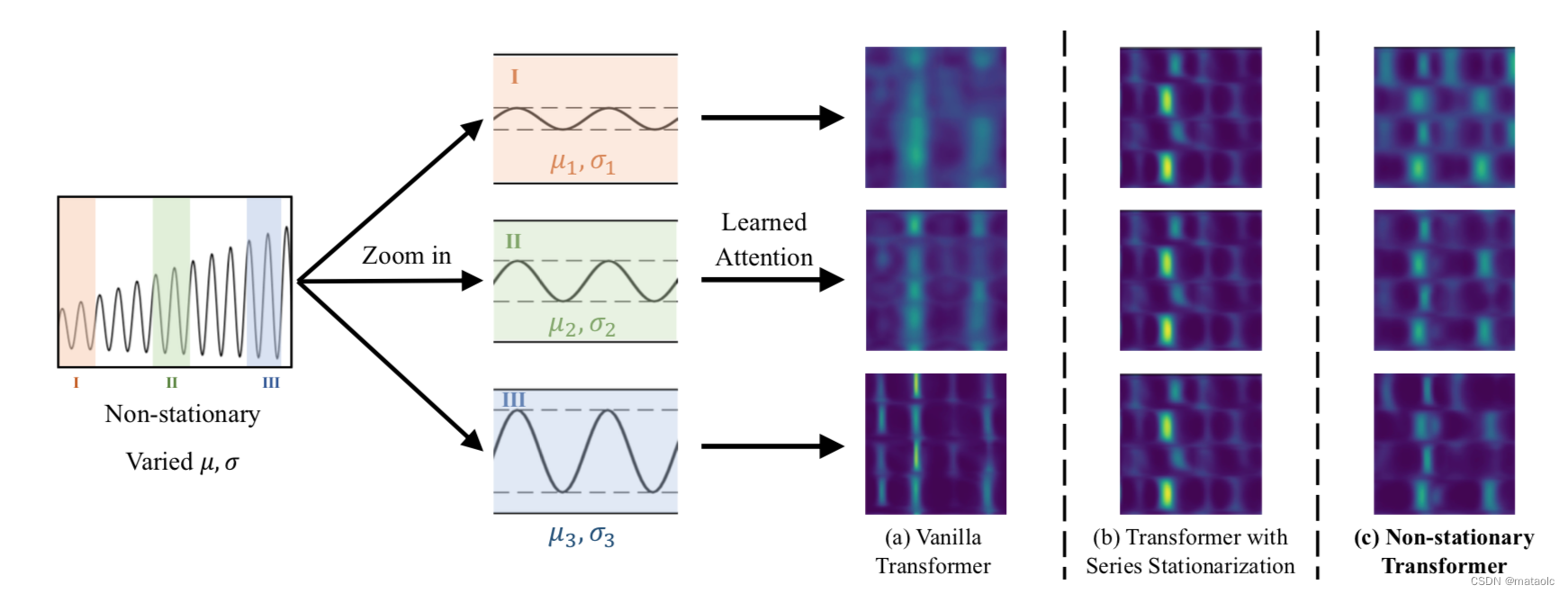
Transformer相关模型在时序预测中已经取得了很多成果。论文作者在实验中观察到由于非平稳信息的丢失导致学习到的attentions不能很好的区分开不同分布的时序数据,如图1b所示。
基于上述问题,论文提出了名为Non-stationary Transformers(NSTransformers)的模型架构,该模型架构包含了相互依赖的两个子模块:序列平稳化(Series Stationarization,SS)和去平稳注意力(De-stationary Attention,DA)。序列平稳化主要消除数据的非平稳性,从而提升序列的可预测性。去平稳注意力则将非平稳信息整合到注意力机制中,从而解决过平稳问题。
2. 模型架构
NSTransformers包含了相互依赖的两个子模块:序列平稳化(Series Stationarization)和去平稳注意力(De-stationary Attention)。
2.1 序列平稳化 Series Stationarization
序列平稳化包含包含两个子模块,标准化模块(Normalization module)和反标准化模块(De-normalization module)。
标准化模块
该模块将原始数据进行标准化。具体方法是,对与每个输入
x
=
[
x
1
,
x
2
,
.
.
.
,
x
S
]
T
x = [x_1, x_2, ..., x_S]^T
x=[x1,x2,...,xS]T,将其转化为
x
′
=
[
x
1
′
,
x
2
′
,
.
.
.
,
x
S
′
]
x^{\prime} = [x_1^{\prime}, x_2^{\prime}, ..., x_S^{\prime}]
x′=[x1′,x2′,...,xS′],转化方法如下:

反标准化模块
该模块作用于最后,将模型输出结果反标准化。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fiXyYUES-1671375701060)(evernotecid://C2D57F4D-3AA0-4F7A-A5E7-B738EFC3E2DB/appyinxiangcom/12187595/ENResource/p1241)]](https://img-blog.csdnimg.cn/e99961b37b124d58a17888fd7cd3e317.png#pic_center)
2.2 去平稳注意力 De-stationary Attention
去平稳注意力模块
原始Self-attention:

基于Embedding层和FFN层的线性假设,并推导后得到:


论文将这两个参数定义为去平稳化因子(De-stationary factors)。在实现时,使用了一个简单的MLP从原始数据及对应的均值方差中获取到去平稳化因子,使其能够自适应地去学习。

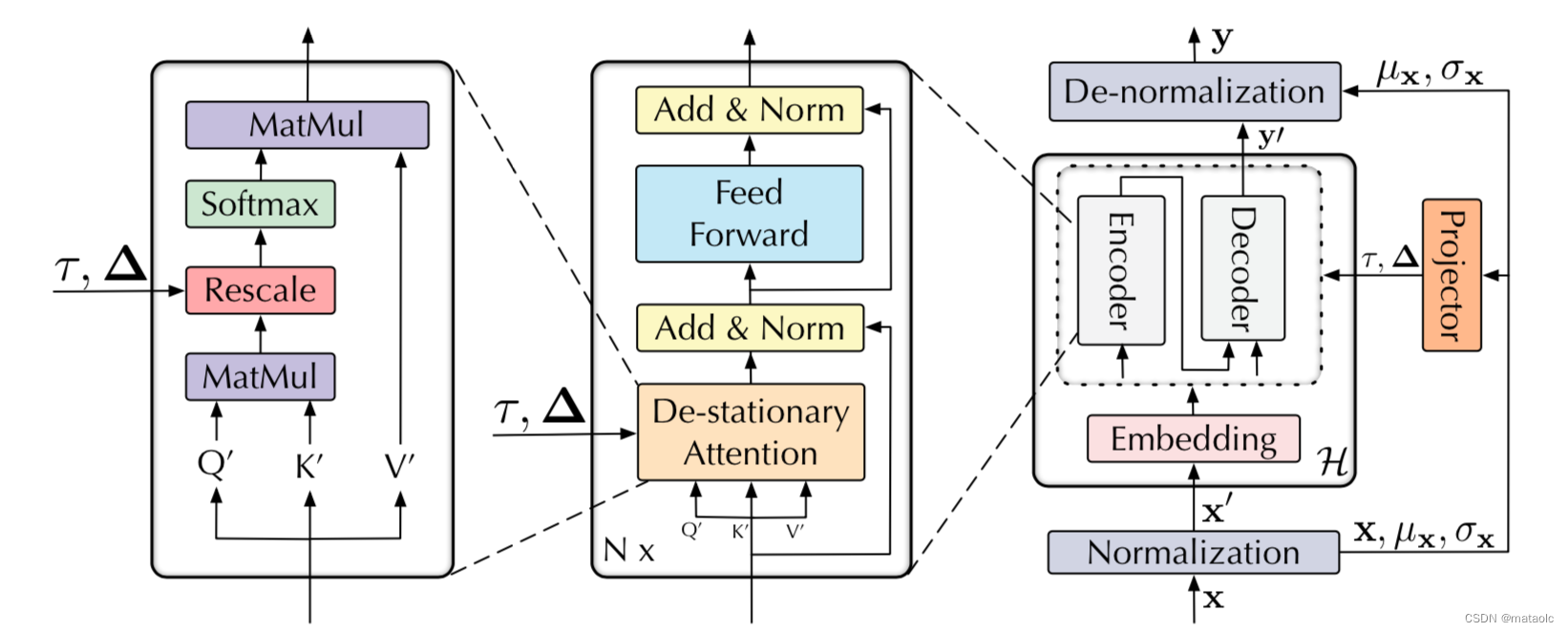
2.3 整体结构
NSTransformers的整体架构如图2所示。主模型使用Encoder-Decoder架构的Transformer或其变种。平稳化模块的两个子模块分别作用于Encoder前和Decoder后。Transformer的自注意力计算中的softmax算子替换成去平稳注意力算子。
3. 实验
3.1 模型效果
作者在6个时序数据集以及多个Transformer变种上做了实验。
数据集信息如下:

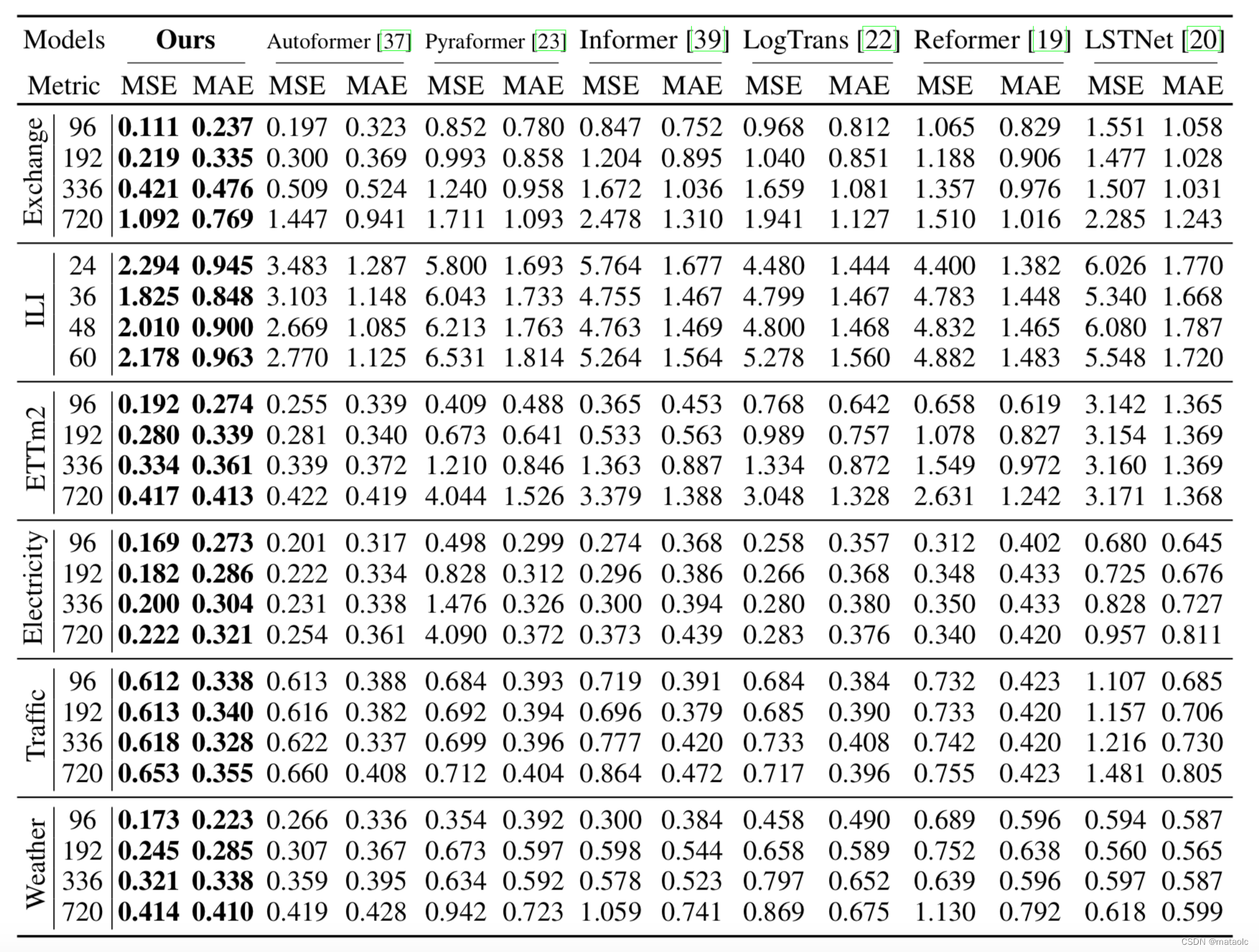
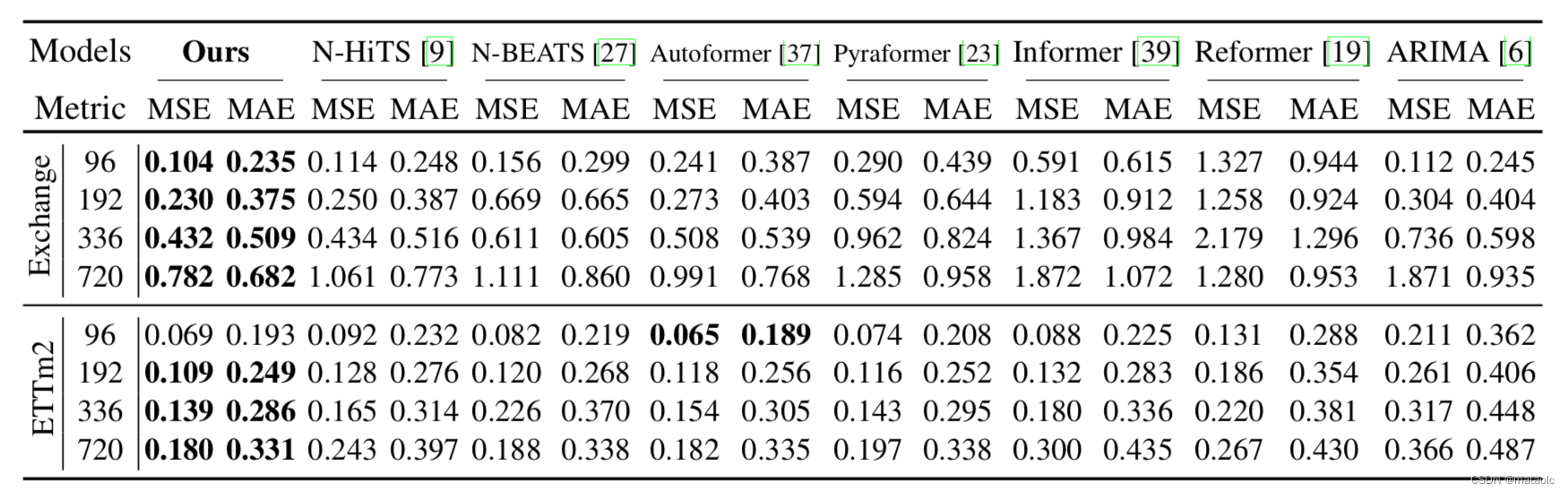
与近期提出的多个Transformer变种时序预测模型对比,不管是多元时序预测还是单元时序预测,论文提出的模型框架均取得了SOTA效果,特别在非平稳数据集上提升更显著。下面两个表分别展示了多元时序预测实验结果和单元时序预测实验结果。
3.2 架构通用性
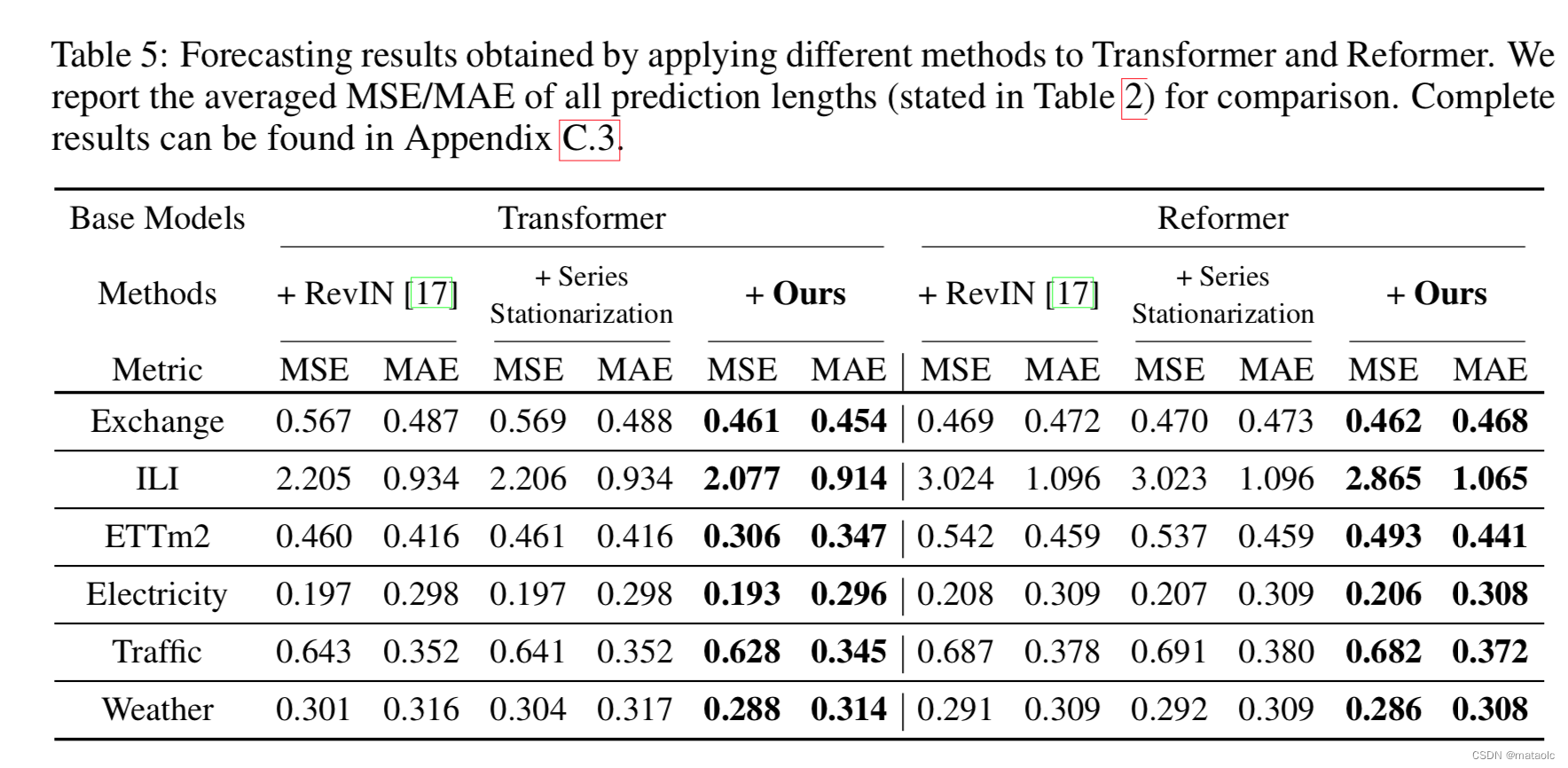
在多个Transformer变种上应用论文提出的模型架构,并进行实验,结果显示该框架对这些模型的效果都有一定程度的提升。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W4BCXYOX-1671375701066)(evernotecid://C2D57F4D-3AA0-4F7A-A5E7-B738EFC3E2DB/appyinxiangcom/12187595/ENResource/p1252)]](https://img-blog.csdnimg.cn/fbdaf4db271f45e7bc3f3eb8b18c7796.png)
3.3 消融实验
作者对比了使用平稳化方案和使用论文方案的预测效果和平稳性差异,以探索论文方案的有效性。
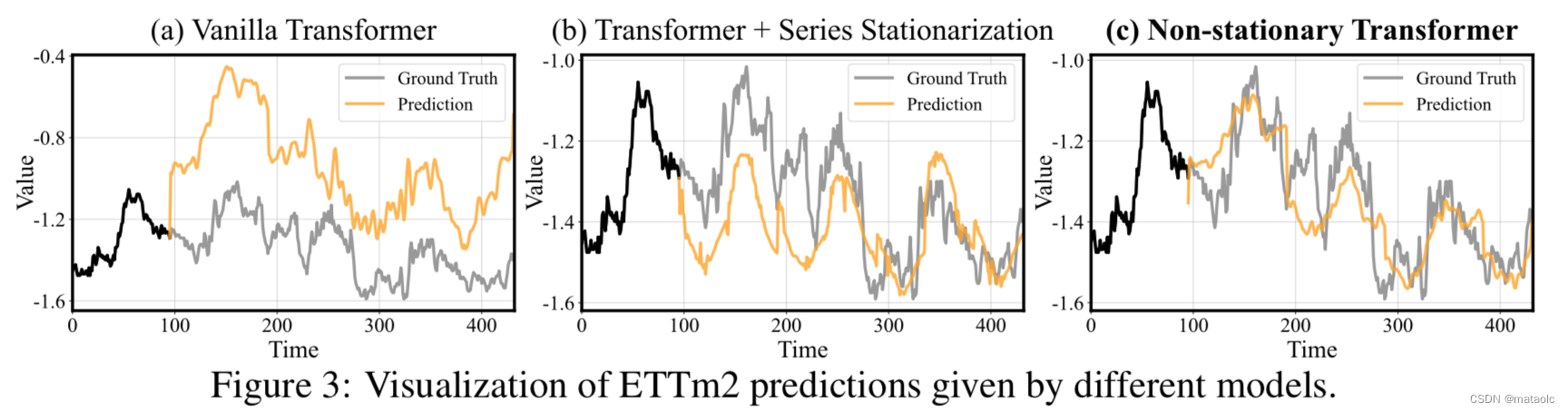
不管是通过case定性分析还是定量分析,都可以看出论文方案的有效性。也说明仅使用平稳化后的信息来预测有一定的局限性,通过一定的机制再加入非平稳信息可以提升模型对非平稳序列预测的潜力。
3.4 模型分析
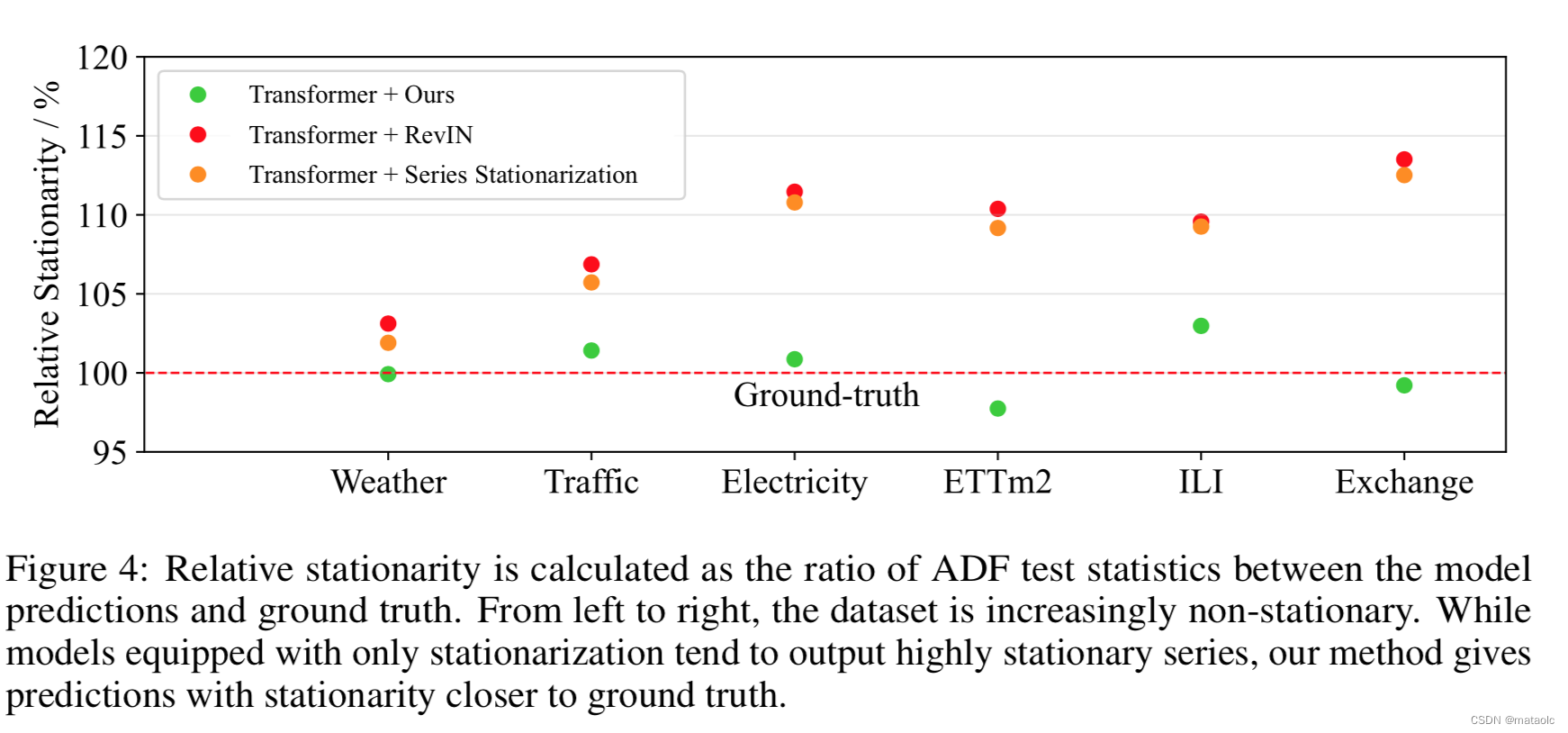
序列平稳化使窗口间的序列之间的统计量对齐,一定程度上可以缓解深度模型在泛化能力差的问题,但是会导致模型倾向于产生过于平稳的预测输出。引入模型内部的去平稳化注意力之后,预测输出的过平稳问题得到缓解,这有助于取得更加精确的时序预测。
4. 总结
非平稳时序预测之前的主流思路都是研究热河将非平稳数据平稳化,本文提出了一种有效的模型架构,不仅考虑了数据的平稳化,还利用了非平稳信息来提升模型预测能力,并通过大量实验验证了效果。














 1268
1268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









