






DeepVisionary 每日深度学习前沿科技推送&顶会论文分享,与你一起了解前沿深度学习信息!
引言:探索语言模型的定制化控制
在现代人工智能的应用中,语言模型扮演了至关重要的角色。随着大型语言模型(LLMs)的广泛部署,对于词汇、风格和特征的定制化控制变得愈发重要。本文介绍了一种新颖的推理框架——模型算术,它允许在不需要模型重新训练或高度特定数据集的情况下,组合和偏置LLMs。此外,该框架比直接提示和以往的控制文本生成(CTG)技术能更精确地控制生成文本。通过模型算术,我们能够将之前的CTG技术表达为简单的公式,并自然地扩展它们以形成新的、更有效的公式。此外,我们展示了推测性采样技术在我们的设置中的扩展,这使得在多个组合模型上进行高效的文本生成成为可能,且仅比单一模型略有开销。我们的实证评估表明,模型算术允许对生成文本进行细粒度控制,并在降低文本毒性的任务上超越了最先进的技术。
论文基本信息
- 标题: Controlled Text Generation via Language Model Arithmetic
- 作者: Jasper Dekoninck, Marc Fischer, Luca Beurer-Kellner, Martin Vechev
- 链接: https://arxiv.org/pdf/2311.14479.pdf
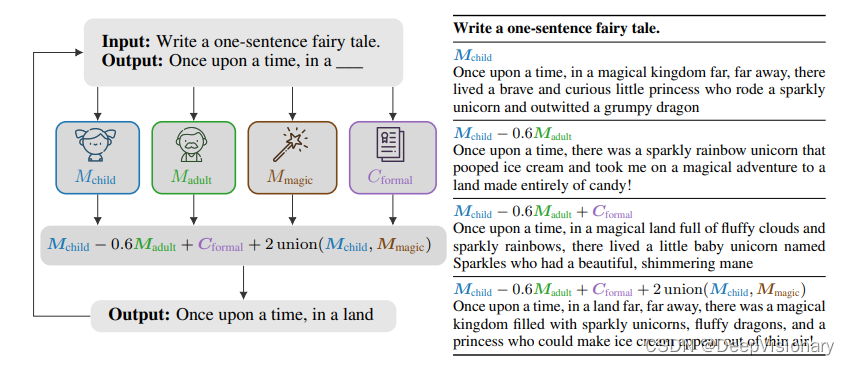
模型算术的介绍与定义
模型算术是一种新颖的推理框架,用于组合和偏置大型语言模型(LLMs),而无需对模型进行(重新)训练或使用高度特定的数据集。这种方法允许在不直接提示的情况下更精确地控制生成的文本,比以前的受控文本生成(CTG)技术更为有效。通过模型算术,我们可以将先前的CTG技术表达为简单的公式,并自然地将它们扩展到新的、更有效的公式中。
在模型算术中,我们可以自然地结合多个模型和属性,以精确控制每个组成部分的影响。例如,我们可以将针对儿童的模型(Mchild)与针对成人的模型(Madult)结合,通过特定的权重(例如0.6)来调整成人模型的影响,进而生成更适合儿童的故事内容。此外,还可以通过添加形式化分类器(Cformal)来增加正式程度,或使用特殊的联合操作符来强调魔法和儿童语言,从而进一步偏置生成过程,获得最终所需的文本输出。
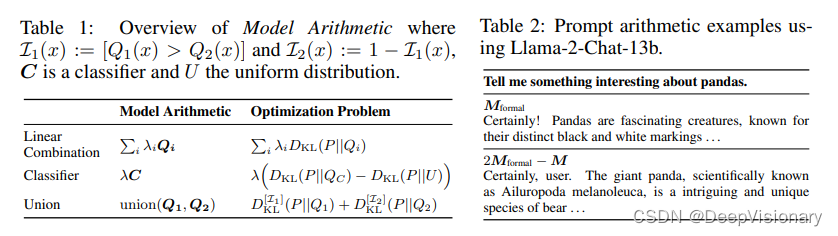
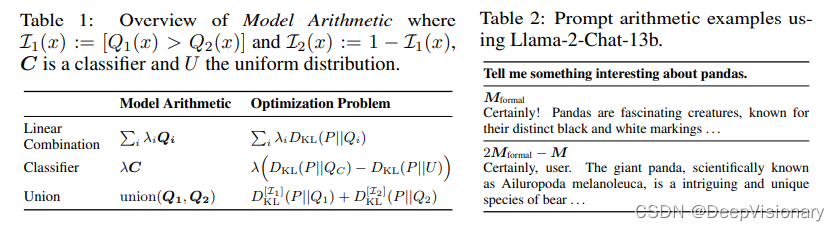
模型算术的实现方法
模型算术的实现涉及几个关键步骤,首先是定义各个模型和属性的组合方式。这通常通过线性组合的方式来实现,其中包括标准输出的LLM(M)作为Q1(λ1 = 1),然后使用其他分布Qi来偏向(如果λi > 0)或偏离(如果λi < 0)某个特定属性。
此外,模型算术还引入了“联合操作符”,这是一种非线性组合方式,允许将两个输入分布Q1和Q2以直观的方式结合,这种方式代表了两个分布特征的联合,从而能够引入不常见或相异的属性。例如,如果Q1或Q2中的任何一个对某个标记分配了高概率,则联合操作符也会为这个标记分配高概率。
在实际应用中,模型算术还可以通过推广的推测性采样(Speculative Sampling)来实现高效的文本生成。这种方法通过在模型算术公式中选择一个或多个术语作为提议模型,从而推迟更昂贵术语的评估,直到生成了一个推测性的标记序列,最终由完整的公式F验证。这种方法显著减少了模型调用的数量,并提高了推理速度,使得模型算术在处理复杂公式时更为高效。

高效的模型算术:推广的推测性采样
在处理大型语言模型(LLM)的复杂组合时,推测性采样(Speculative Sampling)的推广显得尤为重要。推测性采样原本用于通过一个较小的模型提出候选词,然后由更大的模型进行验证,以此减少单个LLM的延迟。在模型算术的背景下,这种方法被扩展应用,以便在执行模型算术公式时,推迟更昂贵的模型调用的评估。
通过这种推广的推测性采样,我们可以在只有边际开销的情况下执行由多个模型组成的公式,大大减少了模型调用次数,据报道,减少了高达64%。这种方法不仅提高了推测性采样的效率,而且还扩展到了以前的控制文本生成(CTG)技术,这些技术现在可以通过模型算术表达。
例如,考虑一个简单的模型算术公式,其中包括儿童语言模型(Mchild)和成人语言模型(Madult)。通过应用推广的推测性采样,我们可以先暂时使用Mchild生成文本,然后再根据需要调用Madult来调整生成的文本,以确保文本更符合目标受众的期望。
这种方法的实际应用包括了在生成文本时实时调整多个模型的输出,以优化性能和响应速度,从而在保持生成文本质量的同时,显著提高了处理速度。
模型算术的评估
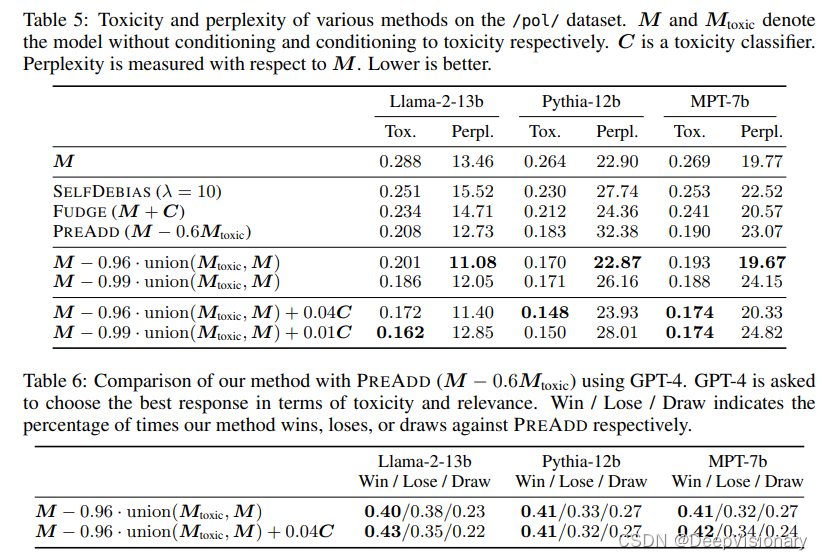
模型算术的评估显示了其在多个方面的优越性。首先,它在减少文本生成中的有害内容方面表现优异。通过使用模型算术,研究人员能够精细地控制生成文本的属性,如减少有害内容。在使用/pol/数据集进行的测试中,模型算术生成的回复在毒性评分上显著低于其他方法,如FUDGE和PREADD。
此外,模型算术还提供了对生成文本属性的细粒度控制。通过组合不同的模型和调节器,研究人员能够精确地调整输出文本的风格、情感和主题。例如,通过结合使用联合操作符和分类器术语,可以在保持文本流畅性的同时,实现对特定属性的高度控制。
最后,推广的推测性采样在模型算术中的应用显著提高了推理速度。在实验中,这种方法在处理复杂的模型算术表达式时,减少了模型调用次数,并提高了推理速度,这对于实时应用尤为重要。
总的来说,模型算术及其评估展示了这一方法在控制文本生成中的高效性和灵活性,特别是在处理需要细粒度控制的应用时,如互动聊天机器人、内容过滤和个性化内容生成等。
讨论与未来方向
在控制文本生成的领域,模型算术提供了一种全新的方法论,使得我们能够通过简单的公式组合多个模型和属性,从而精确控制生成文本的内容。这种方法不仅提高了生成文本的精确度,还大大提升了效率。通过引入推测性采样(speculative sampling),模型算术能够在保持生成效率的同时,减少对多个模型的调用需求。
未来的研究可以在几个方向上进行扩展和深化:
1. 增强模型算术的表达能力: 尽管当前的模型算术已经能够处理多种控制需求,但其表达能力仍有提升空间。例如,开发新的操作符来处理更复杂的属性组合或更细粒度的控制。
2. 优化推测性采样策略: 当前的推测性采样已经能够有效减少模型调用次数,未来可以通过改进算法进一步优化性能,例如通过动态调整推测步骤的深度或采用更智能的模型选择策略。
3. 扩展到更多应用场景: 模型算术的应用不应局限于现有的几种文本生成任务。未来可以探索将其应用于更广泛的场景,如自动编写代码、生成艺术文本等。
通过这些研究,我们可以更好地理解和利用大型语言模型的潜力,为用户提供更加丰富和个性化的文本生成服务。
结论:模型算术在控制文本生成中的创新应用
本文介绍的模型算术方法,为控制文本生成领域带来了创新的视角和实用的工具。通过将不同的模型和属性以算术形式组合,我们能够精确地控制生成文本的各个方面,如风格、情感和主题等。这种方法比传统的直接提示或微调模型更为高效和灵活。
实验结果显示,模型算术在减少文本生成中的有害内容方面,超过了现有的最先进技术。此外,通过推广推测性采样,模型算术在保持生成质量的同时,显著提高了生成效率。
总之,模型算术极大地丰富了我们对大型语言模型控制能力的理解和应用,展示了在保证文本生成质量和效率的前提下,如何有效地实现文本生成的精细控制。未来的研究将进一步扩展这一框架的功能和应用范围,推动个性化和安全的文本自动生成技术的发展。
关注DeepVisionary 了解更多深度学习前沿科技信息&顶会论文分享!















 669
669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









