







✅作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,
代码获取、论文复现及科研仿真合作可私信。
🍎个人主页:Matlab科研工作室
🍊个人信条:格物致知。
更多Matlab完整代码及仿真定制内容点击👇
🔥 内容介绍
随机配置网络(SCN)是一种用于数据分类和预测的强大工具。它通过模拟大量的随机配置来构建模型,从而实现对数据的有效分类和预测。在本文中,我们将探讨基于随机配置网络的数据分类预测方法,以及它在实际应用中的优势和局限性。
首先,让我们来了解一下SCN分类的基本原理。SCN利用随机配置的方式来构建模型,通过大量的随机实验来获取数据的特征和模式。然后,利用这些特征和模式来对新的数据进行分类和预测。SCN分类方法的核心思想是通过模拟大量的随机配置来获取数据的概率分布,从而实现对数据的有效分类和预测。
SCN分类方法的优势之一是其对大规模数据的处理能力。由于SCN通过模拟大量的随机配置来构建模型,因此它能够有效地处理大规模的数据,并且能够在短时间内对数据进行分类和预测。这使得SCN在处理大规模数据时具有明显的优势,尤其是在金融、医疗等领域的应用中。
此外,SCN分类方法还具有较高的准确性和稳定性。由于SCN通过模拟大量的随机配置来构建模型,因此它能够充分地挖掘数据的特征和模式,从而实现对数据的准确分类和预测。同时,由于SCN具有较高的稳定性,因此它在处理不稳定的数据时也能够保持较高的分类和预测准确性。
然而,SCN分类方法也存在一些局限性。首先,由于SCN需要模拟大量的随机配置来构建模型,因此它在计算资源和时间上的消耗较大。这使得SCN在实际应用中可能会面临一定的计算压力。其次,由于SCN是基于概率分布的方法,因此它在处理非线性数据时可能会存在一定的局限性,需要进一步的改进和优化。
综上所述,基于随机配置网络的数据分类预测方法具有较高的准确性和稳定性,尤其在处理大规模数据时具有明显的优势。然而,它也面临一定的计算压力和对非线性数据的局限性。我们期待未来能够进一步改进和优化SCN分类方法,使其在更广泛的领域中发挥更大的作用。
📣 部分代码
%% 清空环境变量warning off % 关闭报警信息close all % 关闭开启的图窗clear % 清空变量clc % 清空命令行%% 导入数据res = xlsread('数据集.xlsx');%% 划分训练集和测试集temp = randperm(357);P_train = res(temp(1: 240), 1: 12)';T_train = res(temp(1: 240), 13)';M = size(P_train, 2);P_test = res(temp(241: end), 1: 12)';T_test = res(temp(241: end), 13)';N = size(P_test, 2);%% 数据归一化[p_train, ps_input] = mapminmax(P_train, 0, 1);p_test = mapminmax('apply', P_test, ps_input);t_train = ind2vec(T_train);t_test = ind2vec(T_test );
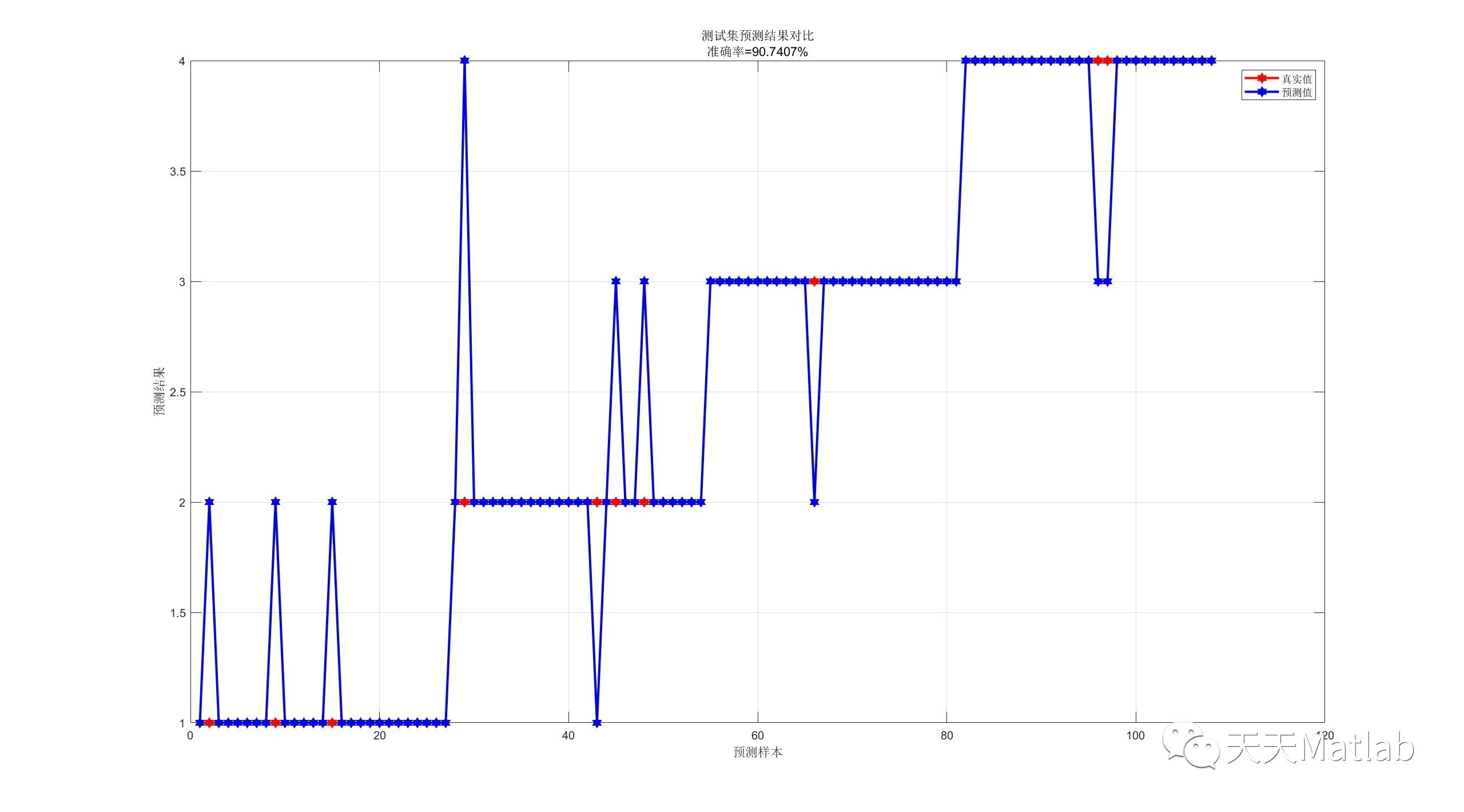
⛳️ 运行结果



🔗 参考文献
本程序参考以下中文EI期刊,程序注释清晰,干货满满。
[1]胡明豪,黄 海.基于随机配置网络的服装分类方法[J].建模与仿真, 2023.DOI:10.12677/MOS.2023.125406.
















 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











