







MTP(Multi-Token Prediction):提升大模型性能的利器
一、引言
在自然语言处理领域,大型语言模型(LLMs)已经取得了显著的成果。然而,这些模型在训练和推理过程中面临着一些挑战,其中最主要的问题之一是生成效率低下。传统的单token预测方法(Next-Token Prediction)在训练和推理阶段都需要逐个生成token,这不仅耗时,而且难以学习长距离的依赖关系。为了解决这些问题,MTP(Multi-Token Prediction)技术应运而生。
二、为什么要做 MTP
1. 背景
当前主流的大模型都是基于解码器(decoder-based)的结构,在训练和推理阶段,对于一个序列的生成过程,都是token-by-token的。每次生成一个token时,都需要频繁与访存交互,加载KV-Cache,再通过多层网络做完整的前向计算。这种访存密集型的任务通常会因为访存效率形成训练或推理的瓶颈。
2. MTP方法的作用
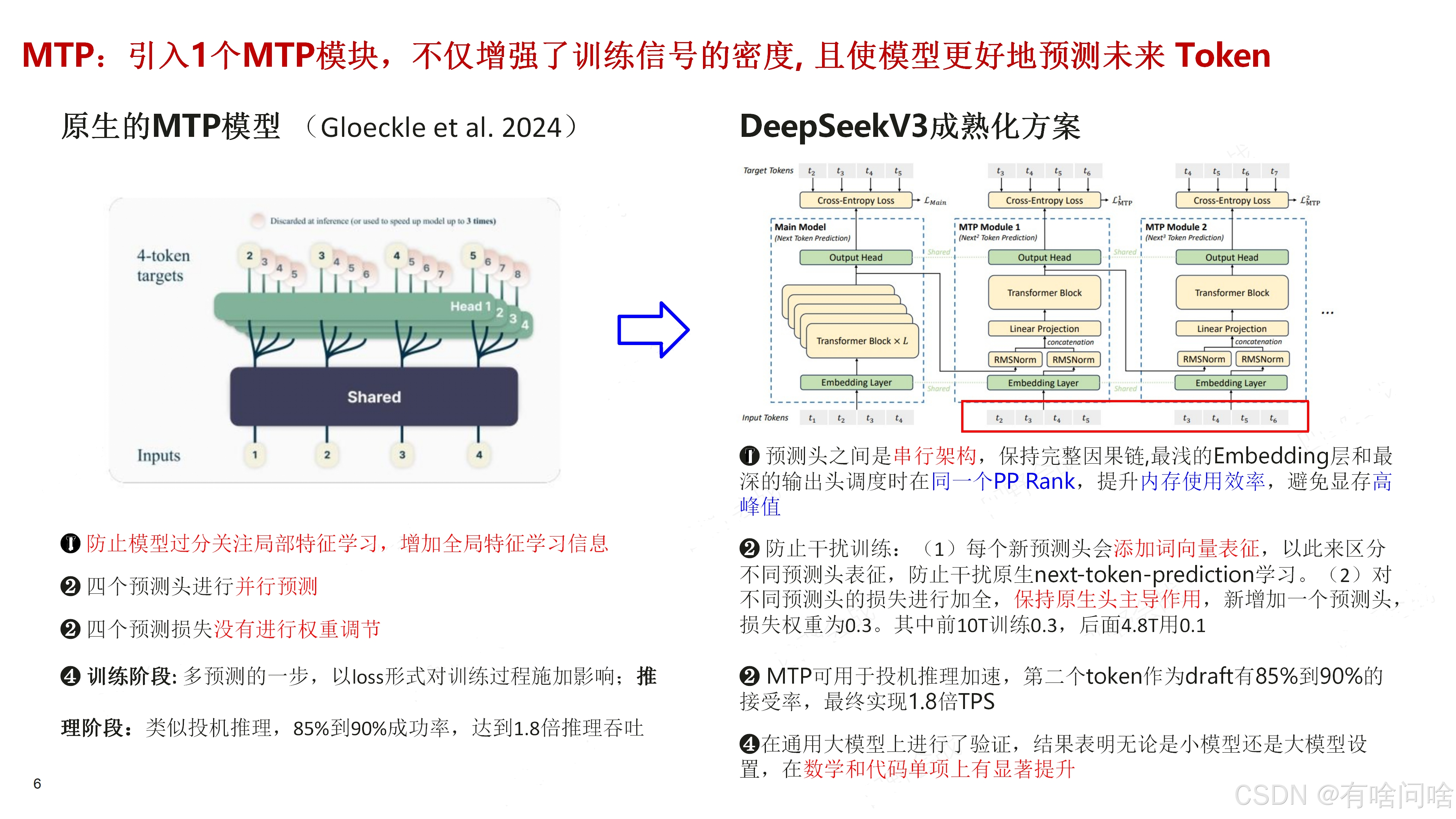
MTP的核心思想是通过解码阶段的优化,将1-token的生成转变为multi-token的生成,从而提升训练和推理的性能。具体来说:
- 训练阶段:一次生成多个后续token,可以一次学习多个位置的label,进而有效提升样本的利用效率,提升训练速度。
- 推理阶段:通过一次生成多个token,实现成倍的推理加速来提升推理性能。
三、MTP的核心原理与公式推导
1. 核心原理
MTP方法的核心是在训练阶段让模型一次性预测多个未来的token,而不是像传统方法那样只预测下一个token。这样可以迫使模型学习更长的token依赖关系,从而更好地理解上下文,避免陷入局部决策的学习模式。
2. 公式推导
在传统的单token预测方法中,模型的训练目标是最大化下一个token的预测概率,其损失函数可以表示为:
L 1 = − ∑ t log P θ ( x t + 1 ∣ x 1 : t ) L_1 = -\sum_t \log P_\theta(x_{t+1} | x_{1:t}) L1=−
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











