







什么是卷积注意力模块
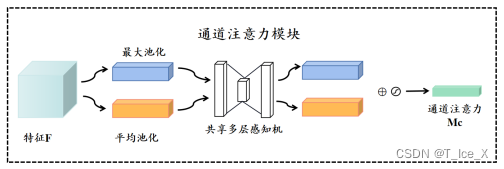
卷积注意力模块(Convolutional Block Attention Module,CBAM)是一种结合了通道注意力和空间注意力的轻量级模块,它可以嵌入任何卷积神经网络中。CBAM包含两块内容:通道注意力模块以及空间注意力模块,在利用CBAM可解释性主要使用的是通道注意力模块定量化分析不同变量相对重要性,故对通道注意力模块着重解释(图7)。将尺寸为H×W×C(纬向格点数×经向格点数×变量数)的特征F分别经过全局最大池化(Global max pooling)和全局平均池化(Global average pooling)两种不同的池化方式,从而获得两个1×1×C的通道特征,接着,再将它们分别送入一个两层的神经网络(多层感知机),第一层神经元个数为C/r(r为减少率),激活函数为Relu,第二层神经元个数为C,这个两层的神经网络是共享的。通过 Sigmoid 激活函数可以获得需要的通道注意力图MC。
代码
直接封装成函数,直接调用CBAM就ok
class basic_conv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0):
super(basic_conv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding),
nn.BatchNorm2d(out_planes)
)
def forward(self, x):
x = self.conv(x)
return x
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.size(0), -1)
class ChannelGate(nn.Module):
def __init__(self, gate_channels, reduction=16, pool_types=['avg', 'max']):
super(ChannelGate, self).__init__()
self.gate_channels = gate_channels
self.mlp = nn.Sequential(
Flatten(),
nn.Linear(gate_channels, gate_channels // reduction),
nn.ReLU(),
nn.Linear(gate_channels // reduction, gate_channels)
)
self.pool_types = pool_types
def forward(self, x):
channel_att_sum = None
for pool_type in self.pool_types:
if pool_type == 'avg':
avg_pool = F.avg_pool2d(x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp(avg_pool)
elif pool_type == 'max':
max_pool = F.max_pool2d(x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_att_raw = self.mlp(max_pool)
if channel_att_sum is None:
channel_att_sum = channel_att_raw
else:
channel_att_sum = channel_att_sum + channel_att_raw
scale = F.sigmoid(channel_att_sum).unsqueeze(2).unsqueeze(3).expand_as(x)
return x * scale
class ChannelPool(nn.Module):
def forward(self, x):
return torch.cat((torch.max(x, 1)[0].unsqueeze(1), torch.mean(x, 1).unsqueeze(1)), dim=1)
class SpatialGate(nn.Module):
def __init__(self):
super(SpatialGate, self).__init__()
kernel_size = 7
self.compress = ChannelPool()
self.spatial = basic_conv(2, 1, kernel_size, stride=1, padding=(kernel_size - 1) // 2)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.spatial(x_compress)
scale = F.sigmoid(x_out) # broadcasting
return x * scale
class CBAM(nn.Module):
def __init__(self, gate_channels, reduction=16, pool_types=['avg', 'max'], no_spatial=False):
super(CBAM, self).__init__()
self.ChannelGate = ChannelGate(gate_channels, reduction, pool_types)
self.no_spatial = no_spatial
if not no_spatial:
self.SpatialGate = SpatialGate()
def forward(self, x):
x_out = self.ChannelGate(x)
if not self.no_spatial:
x_out = self.SpatialGate(x_out)
return x_out















 1248
1248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









