







建立模型的流程
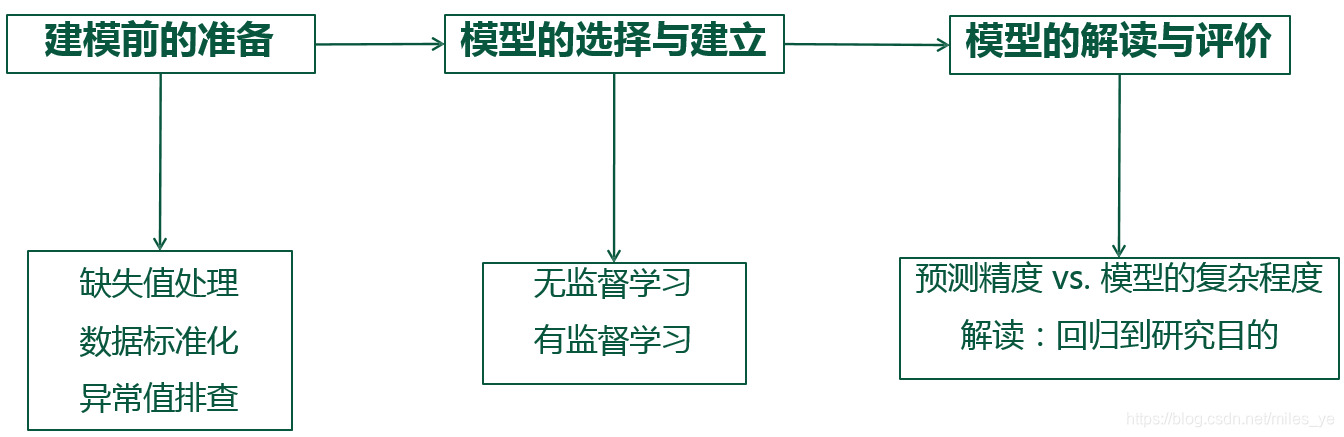
建模前的准备(即数据预处理)
- 缺失值处理
a) 删除之:应用场景缺失值相对于总数据样本而言是非关键少数。
b) 统计量填补:应用的统计量有均值、中位数、回归模型预测值。 - 数据标准化
例如: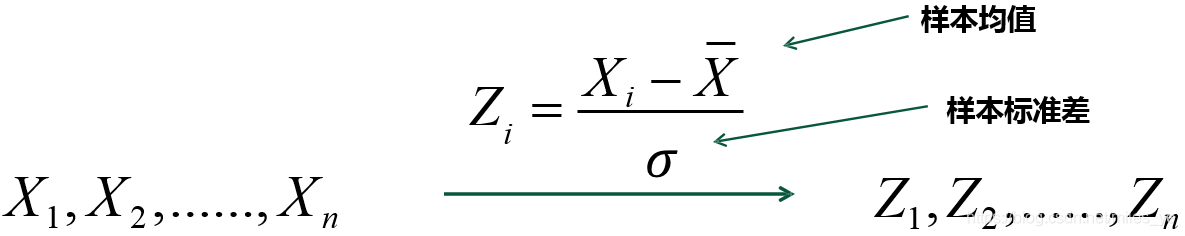
进行数据标准化的主要原因:
a) 统一变量量纲。
b) 同分布变量:标准化后的变量均值为0,标准差(即方差)为1。 - 异常值排查
近似概念:异常值、离群值、极端值。
关键区分是 真实存在(重点分析之) 还是 明显错误(删除或者修正之)。
模型的选择与建立
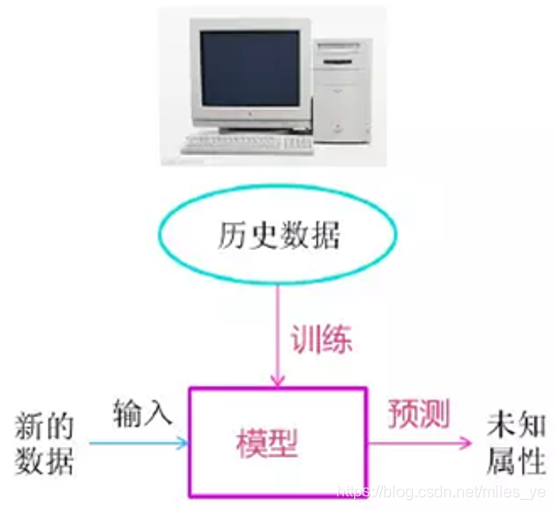
- 有监督学习(简称:监督学习)
也就是上图中作为训练模型用的历史数据中有已知标签y。
监督学习算法:线性回归(Linear Regression)、逻辑回归(Logistic Regression)、神经网络(Articifial Neural Network)、支持向量机(Support Vector Machine)
监督学习中输入变量(即因变量)的类型有:
a) 定量变量:如收入、房价,常用于回归分析中;
b) 定性变量:如:是否放贷、是哪一类垃圾,常用于分类识别中。 - 无监督学习
也就是上图中作为训练模型用的历史数据中没有标签y,y是未知的 或者 是需要推理的。
无监督学习算法:聚类(是许多种算法的统称)、降维(是许多种算法的统称) - 特殊算法
这里的特殊算法是指既不属于有监督学习、也不属于无监督学习的建模,例如:推荐算法
模型评价与解读
-
模型的评价
如上图所示,需要用新的数据对建模效果进行评价,一般有模型的复杂程度 和 预测精度 两个维度进行模型评价。
a) 模型的复杂程度
符合“奥卡姆剃刀”原理,可以用拟合程度进行描述,分为 过拟合(Over Fitting) 和 欠拟合(Under Fitting)。
过拟合表示模型太复杂了,过度地表达了数据中的噪音关系,太过细节了。典型表现为在训练中表现出很好的预测准确性,但是在对新的数据进行预测是表现糟糕。
欠拟合表示模型太弱鸡了,在训练中就已经表现出糟糕的预测效果。
b) 模型的预测精度
对于监督学习,根据预测标签y的类型分为回归和分类两种评价:
对于回归问题的模型预测精度评价常用指标:
平均绝对误差Mean Absolute Error
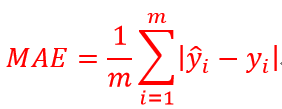
均方根误差Root Mean Square Error
决定系数Coefficient of Determination,即R^2
对于分类问题的模型预测精度评价常用指标:
混淆矩阵(Confusion Matrix)
准确率Accuracy
查准率Precision,即精确率
查全率Recall,即召回率
F1指标
ROC曲线和AUC
其中横坐标是False Positive Rate
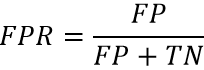
纵坐标是True Positive Rate
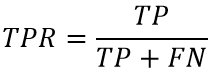















 1042
1042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











