






一、背景
Local Outlier Factor(LOF)是基于密度的经典算法(Breuning et. al. 2000), 文章发表于SIGMOD 2000, 到目前已经有 3000+ 的引用。
在 LOF 之前的异常检测算法大多是基于统计方法的,或者是借用了一些聚类算法用于异常点的识别(比如 DBSCAN,OPTICS)。这些方法都有一些不完美的地方:
- 基于统计的方法:通常需要假设数据服从特定的概率分布,这个假设往往是不成立的。
- 聚类方法:通常只能给出 0/1 的判断(即:是不是异常点),不能量化每个数据点的异常程度。
相比较而言,基于密度的LOF算法要更简单、直观。它不需要对数据的分布做太多要求,还能量化每个数据点的异常程度(outlierness)。
下面开始正式介绍LOF算法。
二、LOF 算法
首先,基于密度的离群点检测方法有一个基本假设:非离群点对象周围的密度与其邻域周围的密度类似,而离群点对象周围的密度显著不同于其邻域周围的密度。
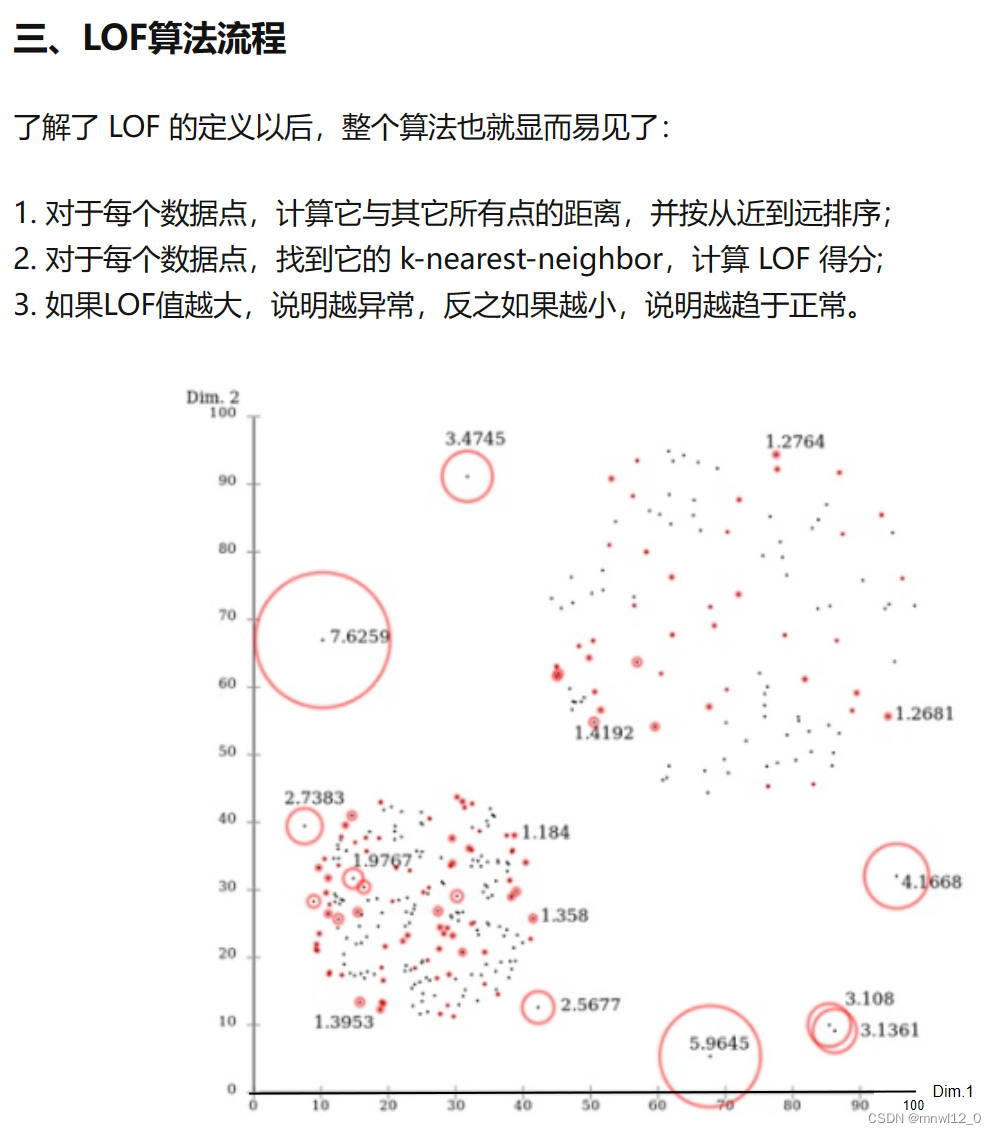
什么意思呢?看下面图片感受下。

集群 C1 包含了 400 多个点,集群 C2 包含 100 个点。C1 和 C2 都是一类集群点,区别是 C1 位置比较集中,或者说密度比较大。而像 o1、o2点均为异常点,因为基于我们的假设,这两个点周围的密度显著不同于周围点的密度。
LOF 就是基于密度来判断异常点的,通过给每个数据点都分配一个依赖于邻域密度的离群因子LOF,进而判断该数据点是否为离群点。 如果LOF>=1 ,则该点为离群点,如果LOF≈1 ,则该点为正常数据点。
那什么是LOF呢?
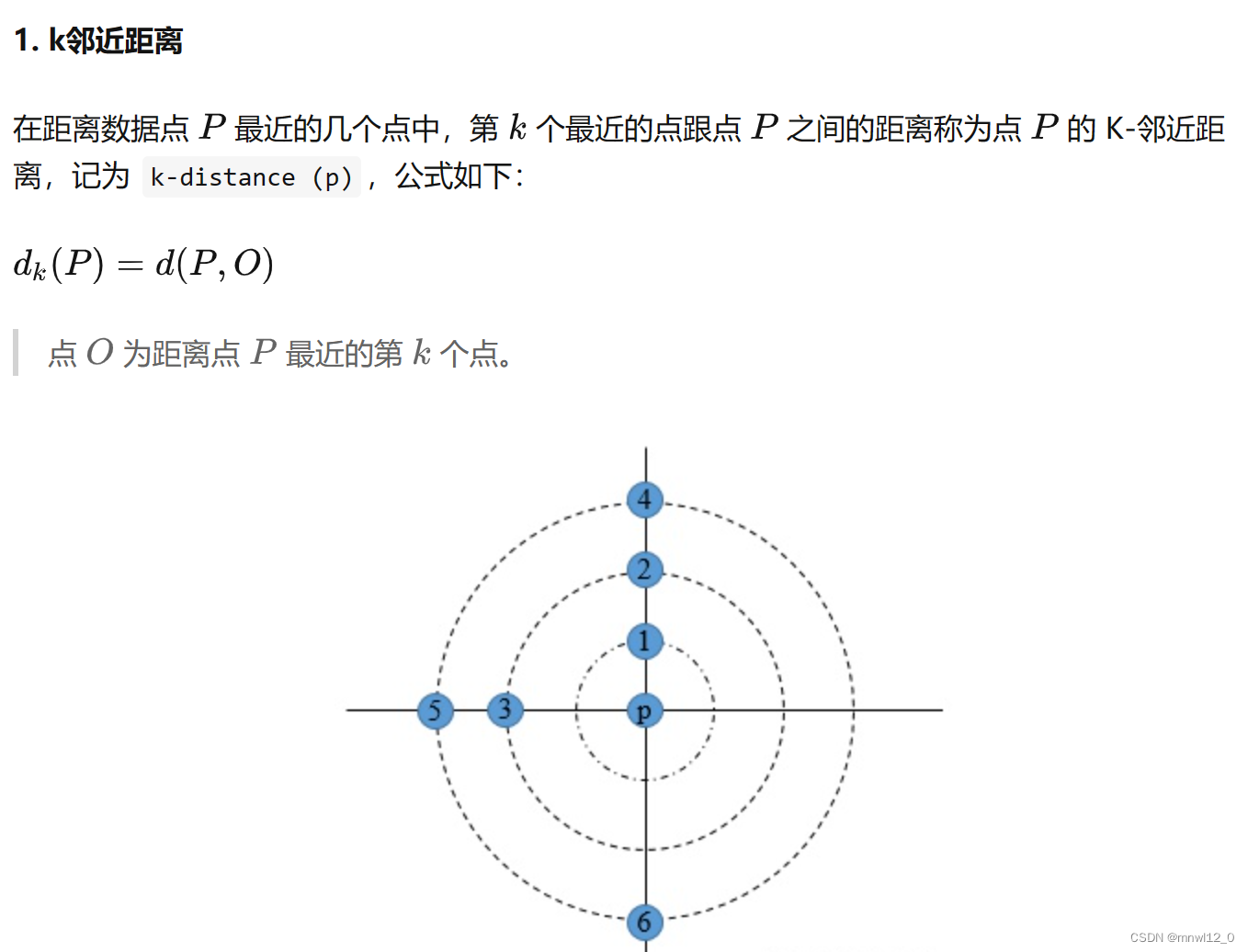
了解LOF前,必须先知道一下3个基本概念,因为LOF是基于这几个概念而来的。



四、LOF优缺点
优点
LOF 的一个优点是它同时考虑了数据集的局部和全局属性。异常值不是按绝对值确定的,而是相对于它们的邻域点密度确定的。当数据集中存在不同密度的不同集群时,LOF表现良好,比较适用于中等高维的数据集。
缺点
LOF算法中关于局部可达密度的定义其实暗含了一个假设,即:不存在大于等于 k 个重复的点。
当这样的重复点存在的时候,这些点的平均可达距离为零,局部可达密度就变为无穷大,会给计算带来一些麻烦。在实际应用时,为了避免这样的情况出现,可以把 k-distance 改为 k-distinct-distance,不考虑重复的情况。或者,还可以考虑给可达距离都加一个很小的值,避免可达距离等于零。
另外,LOF 算法需要计算数据点两两之间的距离,造成整个算法时间复杂度为 O(n2) 。为了提高算法效率,后续有算法尝试改进。FastLOF (Goldstein,2012)先将整个数据随机的分成多个子集,然后在每个子集里计算 LOF 值。对于那些 LOF 异常得分小于等于 1 的,从数据集里剔除,剩下的在下一轮寻找更合适的 nearest-neighbor,并更新 LOF 值。
五、Python 实现 LOF
有两个库可以计算LOF,分别是PyOD和Sklearn,下面分别介绍。
使用pyod自带的方法生成200个训练样本和100个测试样本的数据集。正态样本由多元高斯分布生成,异常样本是使用均匀分布生成的。
训练和测试数据集都有 5 个特征,10% 的行被标记为异常。并且在数据中添加了一些随机噪声,让完美分离正常点和异常点变得稍微困难一些。
from pyod.utils.data import generate_data
import numpy as np
X_train, y_train, X_test, y_test = \
generate_data(n_train=200,
n_test=100,
n_features=5,
contamination=0.1,
random_state=3)
X_train = X_train * np.random.uniform(0, 1, size=X_train.shape)
X_test = X_test * np.random.uniform(0,1, size=X_test.shape)PyOD
下面将训练数据拟合了 LOF 模型并将其应用于合成测试数据。
在 PyOD 中,有两个关键方法:decision_function 和 predict。
- decision_function:返回每一行的异常分数
- predict:返回一个由 0 和 1 组成的数组,指示每一行被预测为正常 (0) 还是异常值 (1)
from pyod.models.lof import LOF clf_name = 'LOF' clf = LOF() clf.fit(X_train) test_scores = clf.decision_function(X_test) roc = round(roc_auc_score(y_test, test_scores), ndigits=4) prn = round(precision_n_scores(y_test, test_scores), ndigits=4) print(f'{clf_name} ROC:{roc}, precision @ rank n:{prn}') >> LOF ROC:0.9656, precision @ rank n:0.8
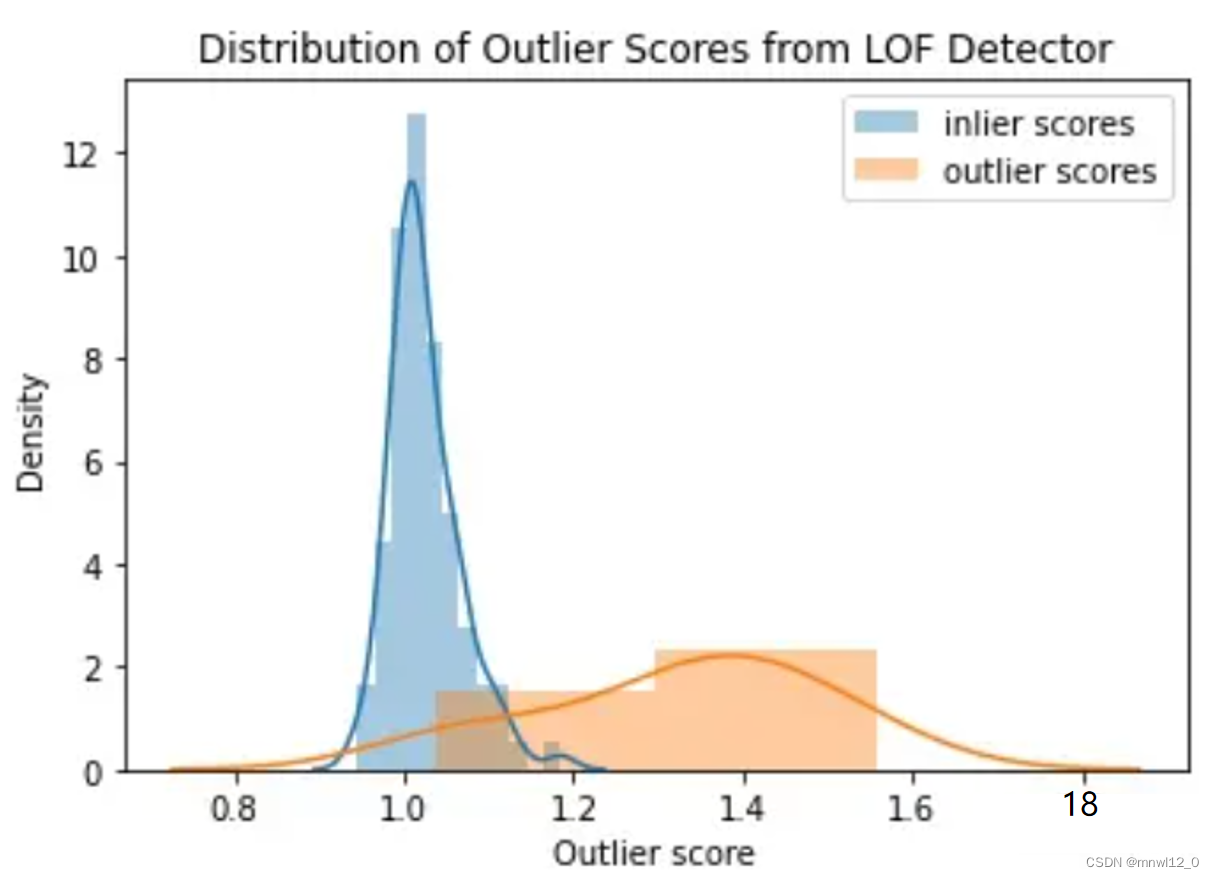
可以通过 LOF 模型方法查看 LOF 分数的分布。在下图中看到正常数据(蓝色)的分数聚集在 1.0 左右。离群数据点(橙色)的得分均大于 1.0,一般高于正常数据。

















 1675
1675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









