










XCiT学习笔记
XCiT: Cross-Covariance Image Transformers
Abstract
在自然语言处理取得巨大成功后,transformers最近在计算机视觉方面显示出了很大的前景。transformers底层的自注意力操作产生了所有令牌(即文字或图像块)之间的全局交互,并允许在卷积的局部交互之外对图像数据进行灵活建模。然而,这种灵活性在时间和内存方面具有二次复杂性,阻碍了对长序列和高分辨率图像的应用。我们提出了一种“transposed”版本的自注意力,它跨特征通道而不是令牌进行操作,其中交互基于键和查询之间的互协方差矩阵。由此产生的 cross-covariance attention(XCA)在令牌数量上具有线性复杂度,并允许高效处理高分辨率图像。我们的互协方差图像变换器(XCiT)基于XCA构建,将传统变换器的精度与卷积架构的可扩展性结合在一起。我们通过报告在多个视觉基准上的出色结果来验证XCiT的有效性和通用性,包括在ImageNet-1k上的(自监督)图像分类、在COCO上的对象检测和实例分割以及在ADE20k上的语义分割。 代码公开在:https://github.com/facebookresearch/xcit
1 Introduction
Transformers架构[69]在语音和自然语言处理(NLP)方面实现了定量和定性突破。最近,Dosovitskiy等人[22]将transformers建立为学习视觉表示的可行架构,报告图像分类的竞争结果,同时依赖大规模预训练。Touvron等人[65]表明,当使用广泛的数据增强和改进的训练方案在ImageNet-1k上训练变压器时,与强卷积基线(如效率网[58])相比,精度/吞吐量相当或更好。对于其他视觉任务,包括图像检索[23]、目标检测和语义分割[44、71、81、83]以及视频理解[2、7、24],已经取得了很好的结果。
transformers的一个主要缺点是核心自注意力操作的时间和内存复杂性,随着输入令牌的数量或计算机视觉中类似的补丁数量的增加而二次增加。对于w×h图像,这转化为 O ( w 2 h 2 ) O(w^2h^2) O(w2h2)的复杂性,这对于涉及高分辨率图像的大多数任务来说是禁止的,例如对象检测和分割。已经提出了各种策略来缓解这种复杂性,例如使用近似形式的自注意力[44,81],或逐步减少特征图采样的金字塔结构[71]。然而,现有的解决方案没有一个是完全令人满意的,因为它们要么以复杂性换取准确性,要么其复杂性对于处理超大图像来说仍然过高。
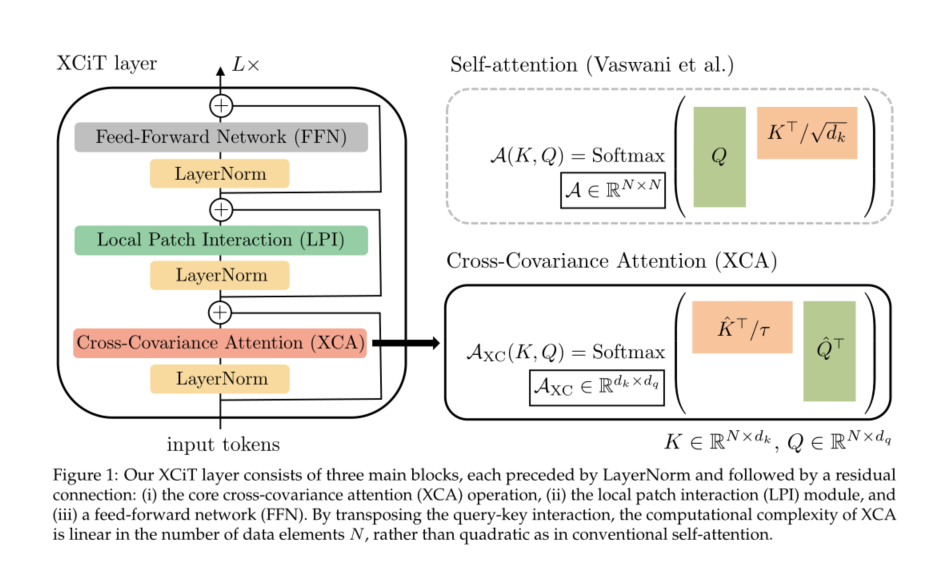
我们将Vaswani等人[69]最初引入的自注意力替换为“转置”注意力,我们将其表示为“cross-covariance attention”(XCA)。互协方差注意通过特征之间的自注意来替代令牌之间的显式完全成对交互,其中注意图是从令牌特征的键和查询投影上计算的互协方差矩阵导出的。重要的是,XCA在面片数量上具有线性复杂性。为了构造互协方差图像变换器(XCiT),我们将XCA与局部面片交互模块相结合,这些模块依赖于变换器中常用的有效深度卷积和点前馈网络,见图1。XCA可以被视为动态1×1卷积的一种形式,该卷积将所有令牌与相同的数据相关权重矩阵相乘。我们发现,我们的XCA层的性能可以通过将其应用于信道块而不是直接将所有信道混合在一起来进一步提高。XCA的这种“块对角”形状进一步降低了计算复杂度,块数中的因子呈线性。
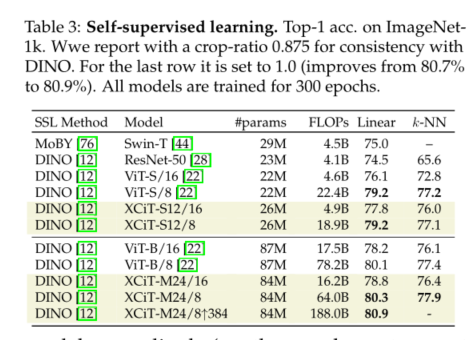
鉴于其令牌数量的线性复杂性**,XCiT可以有效地处理每个维度上超过1000个像素的图像**。值得注意的是,我们的实验表明,XCiT不会影响精度,并且在类似的设置下获得了与DeiT[65]和CaiT[68]相似的结果。此外,对于密集预测任务,如目标检测和图像分割,我们的模型优于流行的ResNet[28]主干以及最近基于transformer的模型[44、71、81]。最后,我们还成功地将XCiT应用于使用DINO[12]的自监督特征学习,并证明了与基于DeiT的主干[65]相比性能有所提高。
总的来说,我们的贡献总结如下:
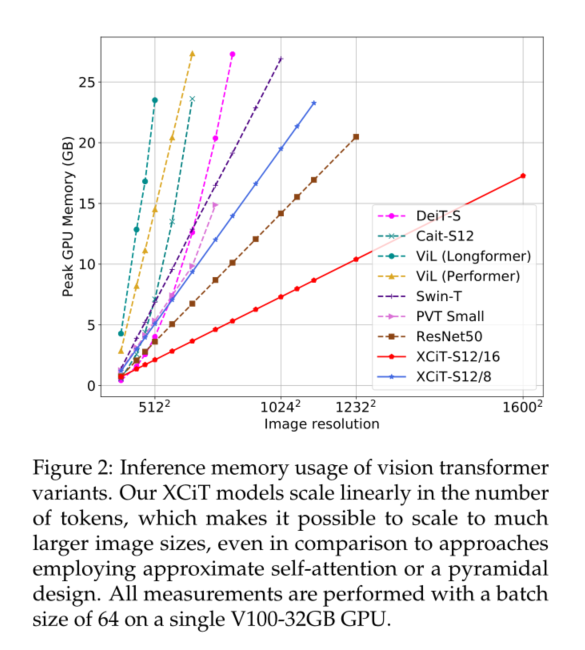
1)我们引入了交叉协方差注意力(XCA),它提供了传统自注意力的“转置”替代方案,通过通道而不是令牌参与。其复杂性在令牌数量上是线性的,允许高效处理高分辨率图像,见图2。
2)XCA关注固定数量的通道,与令牌数量无关。因此,我们的模型对测试时图像分辨率的变化更具鲁棒性,因此更适合处理可变尺寸的图像。
3)对于图像分类,我们证明,对于使用简单柱状结构的多个模型尺寸,我们的模型与最先进的视觉变换器相当,即,我们在各层之间保持分辨率恒定。特别是,我们的XCiT-L24模型在ImageNet上实现了86.0%的top-1精度,优于参数数量相当的CaiT-M24[68]和NFNet-F2[10]。
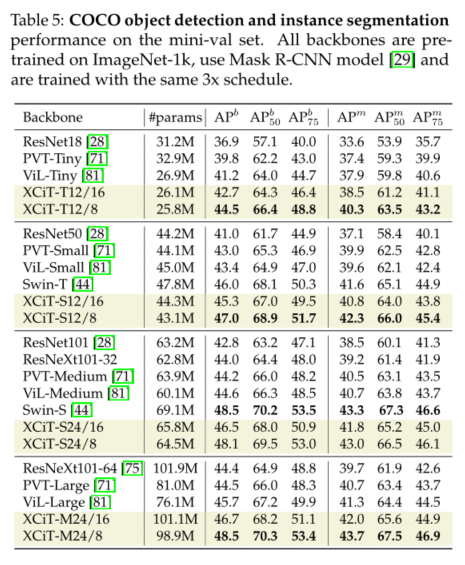
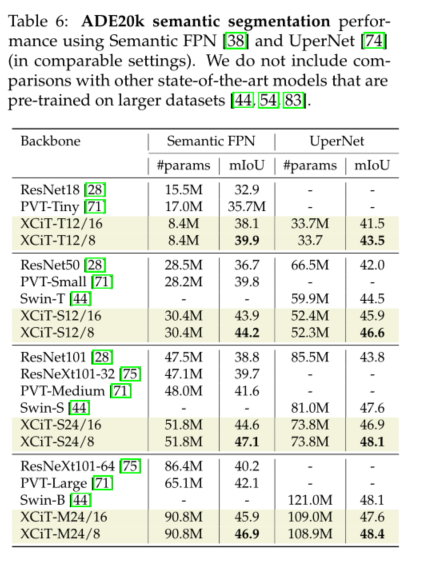
4)对于具有高分辨率图像的密集预测任务,我们的模型优于ResNet和基于多变压器的主干。在COCO基准上,我们分别实现了48.5%和43.7%的目标检测和实例分割。此外,我们在ADE20k基准上报告了48.4%的mIoU用于语义分割,在所有可比模型尺寸上都优于最先进的Swin Transformer[44]主干。
5)最后,我们的XCiT模型在自监督学习设置中非常有效,使用DINO[12]在ImageNet-1k上实现了80.9%的top-1精度。
2 Related work
Deep vision transformers.
由于不稳定和优化问题,训练深度视觉变换器可能具有挑战性。Touvron等人[68]使用分层比例(LayerScale)成功地训练了多达48层的模型,该比例衡量了各层剩余块的贡献,并改进了优化。此外,作者引入了类注意层,将面片特征的学习与分类的特征聚合阶段解耦。
Spatial structure in vision transformers.
袁等人[79]提出将软分割应用于具有重叠面片的面片投影,该面片在模型层上重复应用,逐步减少面片数量。韩等人[27]介绍了用于片内结构的变换器模块2,利用像素级信息并与片间变换器集成以获得更高的表示能力。d’Ascoli等人[19]将自注意力块的初始化视为卷积算子,并证明这种初始化提高了低数据状态下视觉变换器的性能。Graham等人[26]介绍了LeViT,它采用了一种多级架构,与流行的卷积架构类似,具有逐渐降低的特征分辨率,允许模型具有较高的推理速度,同时保持强大的性能。此外,作者采用了基于卷积的模块来提取面片描述符。袁等人[78]通过将线性面片投影替换为卷积层和最大池,以及修改每个变换层中的前馈网络以合并深度卷积,提高了视觉变换器的性能和收敛速度。
Efficient attention
为了解决自注意力在输入令牌数量上的二次复杂性,文献中提出了许多有效的自注意力方法。这些包括将自注意力的范围限制在局部窗口[48,50]、跨步模式[14]、轴向模式[30]或跨层自适应计算[57]。其他方法提供了自注意力矩阵的近似值,可以通过标记维度上的投影[70]或通过softmax注意力核的因子分解[15、37、56、77]来实现,这避免了注意力矩阵的显式计算。虽然概念上不同,我们的XCA执行类似的计算,但对内核的选择不敏感。同样,Lee Thorp等人[41]通过用非参数化傅立叶变换代替自注意力来实现更快的训练。其他有效的注意力方法依赖于局部注意力并添加少量全局令牌,因此仅通过跳转全局令牌来允许所有令牌之间的交互[1、5、34、80]。
Transformers for high-resolution images.
一些作品采用视觉变换器来完成图像分类以外的高分辨率图像任务,如目标检测和图像分割。王等人[71]设计了一个具有金字塔结构的模型,并通过逐渐降低键和值的空间分辨率来解决复杂性。类似地,对于视频识别,Fan等人[24]利用池来降低跨时空维度的分辨率,以允许有效计算注意力矩阵。Zhang等人[81]采用全局令牌和局部注意来降低模型复杂度,而Liu等人[44]提供了一种利用移动窗口进行局部注意的有效方法。此外,Zheng等人[83]和Ranftl等人[54]研究了二次自注意力操作的语义分割和单目深度估计等问题。
Data-dependent layers
我们的XCiT层可以被视为一个“动态”1×1卷积,它将所有令牌特征与相同的数据相关权重矩阵相乘,该矩阵由键和查询互协方差矩阵导出。在卷积网络的背景下,动态滤波器网络[9]探索了一个相关的想法,即使用滤波器生成子网络来基于先前层中的特征生成卷积滤波器。**Squeeze-and-Excitation网络[32]在卷积结构中使用数据相关的1×1卷积。空间平均池特征被馈送到2层MLP,该MLP产生每通道缩放参数。**在精神上更接近我们的工作,Lambda layers提出了一种确保ResNet模型中全局交互的方法[4]。他们的“基于内容的lambda函数”计算的项与我们的互协方差注意类似,但在应用softmax和’2归一化方面有所不同。此外,Lambda层还包括特定的基于位置的Lambda函数,LambdaNetworks基于resnet,而XCiT遵循ViT架构。最近还发现,与数据无关的自注意力类似物是视觉任务卷积层和自注意力层的有效替代物[21、46、63、67]。这些方法将注意力图中的条目视为可学习的参数,而不是从查询和键中动态导出注意力图,但其复杂性在令牌数量上仍然是二次的。赵等人[82]考虑了计算机视觉中的替代注意形式。
3 Method
在本节中,我们首先回顾了自我注意机制,以及Gram矩阵和协方差矩阵之间的联系,这激发了我们的工作。然后,我们提出了交叉协方差注意操作(XCA)——该操作沿着特征维度而不是传统变换器中的令牌维度进行操作——并将其与局部面片交互和前馈层相结合来构建交叉协方差图像变换器(XCiT)。请参见图1以获取概述
3.1 Background
Token self-attention.
Vaswani等人[69]介绍的自注意力作用于输入矩阵 X ∈ R N × d X∈ R^{N×d} X∈RN×d,其中N是令牌数,每个令牌的维数为d。输入X使用权重矩阵 W q ∈ R d × d q , W k ∈ R d × d k 和 W v ∈ R d × d v W_q∈ R^{d×d_q},W_k∈ R^{d×d_k}和W_v∈ R^{d×d_v} Wq∈Rd×dq,Wk∈Rd×dk和Wv∈Rd×dv线性投影到查询、键和值,使得 Q = X W q , K = X W k , V = X W v Q=XW_q,K=XW_k,V=XW_v Q=XWq,K=XWk,V=XWv,其中 d q = d k d_q=d_k dq=dk。键和值用于计算注意力图 A ( K , Q ) = S o f t m a x ( Q K > / √ d k ) A(K,Q)=Softmax(QK>/√d_k) A(K,Q)=Softmax(QK>/√dk),并且自注意力操作的输出被定义为V中N个令牌特征的加权和,其权重对应于注意力映射: A t t e n t i o n ( Q , K , V ) = A ( K , Q ) V Attention(Q,K,V)=A(K,Q)V Attention(Q,K,V)=A(K,Q)V。由于所有N个元素之间的成对交互,自注意力的计算复杂度在N中呈二次缩放。
Relationship between Gram and covariance matrices
为了激发我们的交叉协方差注意操作,我们回忆了Gram和协方差矩阵之间的关系。非正规d×d协方差矩阵在 C = X T X C=X^TX C=XTX时获得。N×N Gram矩阵包含所有成对内积: G = X X T G=XX^T G=XXT。Gram和协方差矩阵的特征谱的非零部分是等价的,并且可以相互计算C和G的特征向量。如果V是G的特征向量,则C的特征向量由U=XV给出。为了最小化计算成本,可以根据另一个矩阵的分解来获得Gram矩阵或协方差矩阵的特征分解,这取决于两个矩阵中哪一个最小。
我们利用Gram和协方差矩阵之间的这种强大联系来考虑是否有可能避免计算N×N注意矩阵的二次成本,该注意矩阵是从N×N Gram矩阵 Q K T = X W q W k T X T QK^T=XW_qW_k^{T}X^{T} QKT=XWqWkTXT的模拟计算出来的。下面我们考虑如何使用dk×dq互协方差矩阵, K T Q = W k T X T X W q K^TQ=W_k^{T}X^TXW_q KTQ=WkTXTXWq,该矩阵可以在线性时间内以元素数N计算,以定义注意机制。
3.2 Cross-covariance attention
我们提出了一种基于互协方差的自注意力函数,该函数沿特征维度运行,而不是像令牌自注意力那样沿令牌维度运行。使用上述查询、键和值的定义,交叉协方差注意力函数定义为:
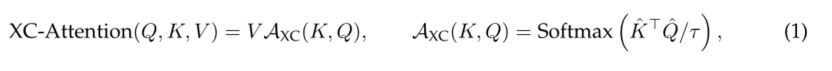
其中,每个输出令牌嵌入是其对应令牌嵌入在V中的dv特征的凸组合。注意力权重A基于互协方差矩阵计算。
L2-Normalization and temperature scaling.
除了在互协方差矩阵上构建注意力操作外,我们还对令牌自注意力进行了第二次修改。我们通过"L2-正则化”来限制查询矩阵和键矩阵的大小,使得归一化矩阵 Q ^ \hat{Q} Q^和 K ^ \hat{K} K^的长度N的每一列都有单位范数,并且d×d互协方差矩阵 K ^ ⊤ Q ^ \hat{K}^{\top} \hat{Q} K^⊤Q^中的每个元素都在范围内[−1, 1]. 我们观察到,控制范数可以显著增强训练的稳定性,尤其是在使用可变数量的令牌进行训练时。然而,限制规范会降低代表性通过移除自由度的操作的力量。因此,我们引入了一个可学习的温度参数τ,该参数在Softmax之前缩放内积,允许注意力权重的分布更清晰或更均匀。
Block-diagonal cross-covariance attention.
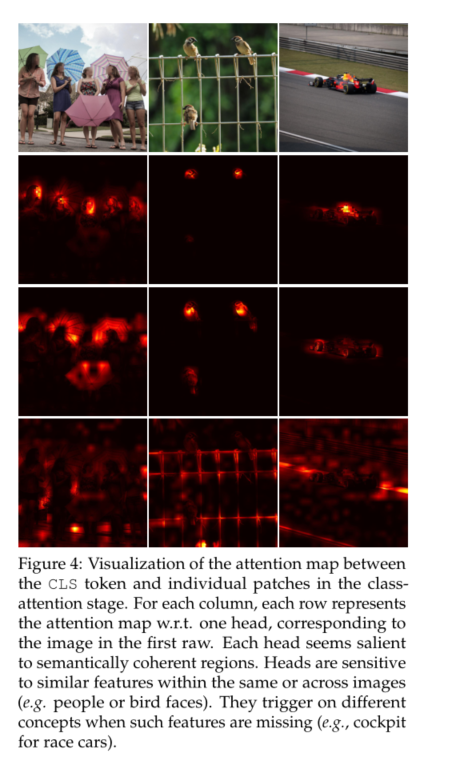
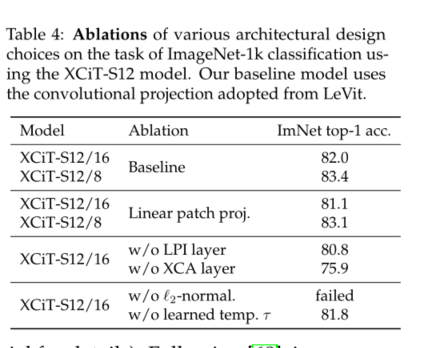
我们不允许所有特征相互作用,而是将它们分成h组,或“头”,以类似于多头标记自我注意力的方式。我们在每个头部分别应用互协方差注意,其中对于每个头部,我们学习单独的权重矩阵,将X投影到查询、键和值,并在张量 W q ∈ R h × d × d q , W k ∈ R h × d × d k 和 W v ∈ R h × d × d v W_q∈ R^{h×d×d_q},W_k∈ R^{h×d×d_k}和W_v∈R^{h×d×d_v} Wq∈Rh×d×dq,Wk∈Rh×d×dk和Wv∈Rh×d×dv中收集相应的权重矩阵,其中我们设置 d k = d q = d v = d / h d_k=d_q=d_v=d/h dk=dq=dv=d/h。在头部内限制注意力有两个优点:(i)用注意力权重聚合值的复杂性降低了一个因子h;(ii)更重要的是,我们根据经验观察到,块对角版本更容易优化,并且通常改进结果的原因。这一观察结果与 Group Normalization[73]的观察结果一致,Group Normalization根据通道组的统计数据分别对通道组进行归一化,与将所有通道合并到单个组中的 Layer Normalization[3]相比,对计算机视觉任务取得了良好的结果。图4显示,每个头部学习关注图像的语义连贯部分,同时灵活地根据图像内容更改其关注的特征类型。
Complexity analysis.
通常的h头标记自注意力的时间复杂度为 O ( N 2 D ) O(N^2D) O(N2D),空间复杂度为 O ( h N 2 + N d ) O(hN^ 2+Nd) O(hN2+Nd)。由于二次复杂度,将令牌自注意力扩展到具有大量令牌的图像是有问题的。我们的交叉协方差注意克服了这个缺点,因为它的计算成本 O ( N d 2 / h ) O(Nd^2/h) O(Nd2/h)与令牌的数量成线性比例,以及 O ( d 2 / h + N d ) O(d^2/h+Nd) O(d2/h+Nd)的内存复杂度。因此,我们的模型可以更好地扩展到令牌数N较大、特征维数d相对较小的情况,这是典型的情况,尤其是在将特征拆分为h个头时。
3.3 Cross-covariance image transformers
为了构造互协方差图像变换器(XCiT),我们采用了柱状结构,该结构在各层之间保持相同的空间分辨率,类似于[22、65、68]。我们将交叉协方差注意(XCA)块与以下附加模块相结合,每个模块前面都有一个LayerNorm[3]。请参见图1以获取概述。由于在本节中,我们专门为计算机视觉任务设计了模型,因此令牌对应于此上下文中的图像补丁。
Local patch interaction.
在XCA块中,补丁之间的通信仅通过共享统计信息隐式进行。为了实现跨补丁的显式通信,我们在每个XCA块之后添加了一个简单的局部补丁交互(LPI)块。**LPI由两个深度方向的3×3卷积层组成,其间具有批量归一化和GELU非线性。**由于其深度结构,LPI块在参数方面的开销可以忽略不计,在推理期间的吞吐量和内存使用方面的开销非常有限。
Feed-forward network.
正如在变压器模型中常见的那样,我们添加了一个逐点前馈网络(FFN),该网络具有一个带有4d隐藏单元的隐藏层。虽然特征之间的交互限制在XCA块中的组内,并且LPI块中不发生特征交互,但FFN允许所有特征之间的交互。
Global aggregation with class attention
在训练我们的图像分类模型时,我们利用了Touvron等人[68]提出的类注意层。这些层通过CLS令牌和补丁嵌入之间的单向注意写入CLS令牌来聚合最后一个XCiT层的补丁嵌入。分类注意力也适用于每个头,即特征组。
Handling images of varying resolution.
与令牌自注意力中涉及的注意力图不同,在我们的例子中,协方差块大小固定,与输入图像分辨率无关。softmax总是在相同数量的元素上运行,这可以解释为什么我们的模型在处理不同分辨率的图像时表现更好(见图3)。在XCiT中**,我们包括带有输入令牌的加法正弦位置编码[69]**。我们从2d面片坐标以64维生成它们,然后线性投影到变压器工作维。这种选择与学习的位置编码的使用正交,如ViT[22]。然而,它更灵活,因为在更改图像大小时不需要插值或微调网络。

Model configurations.
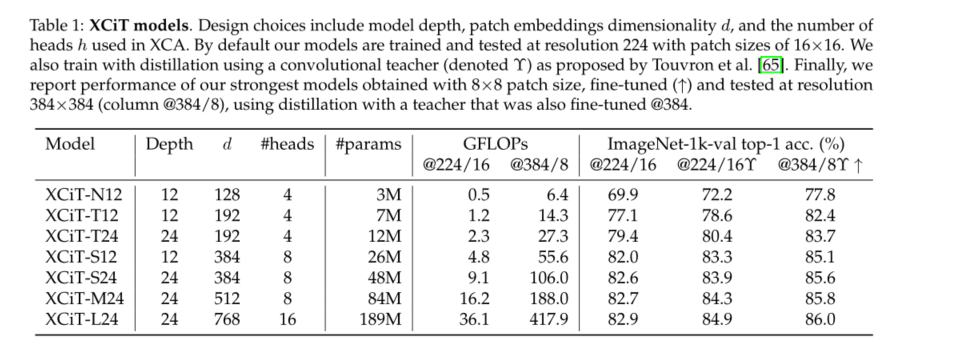
在表1中,我们列出了我们在实验中使用的模型的不同变体,模型宽度和深度有不同的选择。对于面片编码层,除非另有说明,否则我们采用Graham等人[26]使用的卷积面片投影层替代方案。我们还试验了[22]中所述的线性贴片投影,见表4中的消融。我们的默认面片大小为16×16,与其他视觉转换器模型一样,包括ViT[22]、DeiT[65]和CaiT[68]。我们还对较小的8×8面片进行了实验,观察到这种面片可以提高性能[12]。注意,这对于XCiT是有效的,因为其复杂度与面片数成线性比例,而ViT、DeiT和CaiT则成二次比例
4 Experimental evaluation
5 Conclusion
我们提出了一种在特征维度上操作的令牌自注意力的替代方法,消除了对二次注意力映射进行昂贵计算的需要。我们建立了以互协方差注意为核心的XCiT模型,并证明了我们的模型在各种计算机视觉任务中的有效性和通用性。特别是,它表现出与最先进的transformer模型相当的强大图像分类性能,同时对图像分辨率的变化也具有与ConvNet类似的鲁棒性。XCiT是密集预测任务的有效主干,在对象检测、实例和语义分割方面具有优异的性能。最后,我们证明了XCiT可以成为自监督学习的强大支柱,以更少的计算量匹配最先进的结果。XCiT是一种通用架构,可以很容易地部署在其他研究领域,在这些领域中,自我注意力已显示出成功。

















 9137
9137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









