










摘要:本文研究了在样本数量较少的情况下图像变化检测的问题。图像变化检测任务的一个主要障碍是缺乏覆盖各种场景的大型注释数据集。在不充分的数据集上训练的变化检测模型的泛化能力较差。为了解决较差的泛化问题,我们提出使用简单的图像处理方法来生成合成但信息丰富的数据集,并设计了一个基于目标检测的早期融合网络,该网络可以优于孪生神经网络。我们的关键见解是,合成数据使训练模型对各种场景具有良好的泛化能力。我们使用六个不同的测试集,将合成数据训练的模型与从具有挑战性的数据集CDNet捕获的真实数据进行比较。结果表明,与不足的真实数据相比,合成数据具有足够的信息量,可以实现更高的泛化能力。此外,实验表明,利用几个(通常是几十个)样本对合成数据上训练的模型进行微调可以取得很好的效果。
1介绍
本文解决了基于两个图像(即参考图像和测试图像)的变化检测问题,如图1所示。通过对比不同时间拍摄的图像来识别一个区域的变化,称为图像变化检测[1],具有实际意义和很大的研究价值。例如,与正常情况下的参考图像相比,它可以检测和发现图像中的异常。如果输入是来自视频的一系列帧,则该算法可以对连续的两帧不断应用,以检测运动物体。

变化探测的历史始于遥感的出现。如今,它在视频分析中得到了广泛的应用,并成为高级场景理解的敲门砖。大多数传统的方法是基于图像差分和逐像素比较。为了提高算法的精度和效率,提出了特征点提取和图像配准等改进方案。但直到语义分割的应用才将变化检测的研究提升到一个新的水平,这标志着从基于像素的方法到基于对象的方法的快速转变。近年来的研究证实,基于目标的变化检测(OBCD)优于基于像素的变化检测(PBCD),特别是当使用高空间分辨率图像[4],[5]时。
然而,OBCD的性能与分类算法[6]的性能和精度密切相关,而当前分割算法的性能高度依赖于指定任务[7]。大多数基于分割的变化检测方法都过于“具体”,因为它们往往专注于特定的场景(如道路、校园)。将过拟合模型应用于新任务或数据集是非常昂贵的。
鉴于神经网络的普及,捕获和标注训练图像已成为一个主要问题。缺乏这种难以获取的图像可能会成为网络性能的严重瓶颈。有许多可用的数据集包含一些常见的场景和类别,但这些数据集不可能扩展到所有可能的场景或类别。收集大量的注释是具有较强泛化能力的变更检测的主要障碍。
考虑到这些现有方法的缺陷和不足,我们有动力通过使用自动注释的合成数据集和少量手动注释的样本来解决变更检测问题。与其他往往依赖于图像分割和分类技术的变化检测方法相比,我们的方法从目标检测[8]、孪生神经网络[9]和迁移学习[10]中获得灵感。更重要的是,我们使用数字图像处理方法提供了一个通用的合成数据集,以解决识别精度与可用注释较少之间的冲突问题。
将每个变化作为图像对中的一个目标,提出了一种新的方法,将变化检测问题作为一个目标检测任务来解决。考虑到模型接受两张图像作为输入,并且任务是通过其本质来比较图像对,我们提出了两种不同的网络架构:使用早期融合的6通道CNN战略和孪生网络。
近年来,随着计算机图形学和数字图像处理技术的进步,利用合成渲染的场景或对象已经成为突破标注障碍的突破口。大量这样的合成数据集是先进的,如GTAV [11], Sim4CV [12], VIPER[13]等。针对特定任务设计的通用图像合成技术,如车辆和行人检测[14]、[15]、城市场景语义分割[16]或手势识别[17],已经进行了广泛的研究。
然而,据我们所知,仍然很少有合成数据集可用于图像变化检测任务。针对现实数据不足、特征信息丰富的问题,提出了一种简单有效的数据合成方法,用于变化检测。为了模拟图像之间的变化和差异,我们在背景图像上随机粘贴图像,形成新的图像。因此,我们粘贴的图像可以看作是新图片和原始背景图片之间的“变化”。尽管这种合成方法看起来很粗糙,但它节省了图像的获取和人工标注的工作量,这是相当繁琐和费力的。
另一个棘手的问题是如何确保所粘贴的图像与背景图片相匹配。令人鼓舞的是,目标检测方法更关心基于局部区域的特征进行检测,而不是全局场景布局[18]。这意味着我们唯一应该关心的是粘贴图像与背景的融合,而不是由粘贴图像引起的图像语义的变化。换句话说,我们关心的不是合成图像的真实感,而是我们期望神经网络学习的局部特征。
尽管如此,合成数据并不意味着与真实世界的数据完全等价,因为很难模拟真实世界场景中的可变细节。尽管生成合成数据很方便,但仅在这些数据上训练的模型很难推广到现实世界的场景。这是因为图像中的微小变化(例如,阴影、照明、对比度和噪声)对检测有很强的干扰。“变化”很难定义,因为在特定任务中标记的“变化”(如阴影)可能会在另一个场景或任务中消失。考虑到“变化”的变量定义很大程度上取决于特定的任务,我们使用一小部分手动标记的数据来改进模型。以合成数据为源域,新任务为目标域,利用目标域的少量样本对模型进行细化,学习“变化”的定义。结果表明,经过微调的模型显示出相当显著的改进。
综上所述,本文的主要贡献如下:
•经过多次试验,我们提出了一种有效的方法来生成信息丰富的合成数据。在各种情况下,在合成数据上训练的模型优于在不足的真实世界数据上训练的模型。此外,为了应对微小变化的问题,使用一小部分真实数据来改进模型是可行的。
•针对作为目标的图像之间的“变化”,提出了一种基于目标检测的早期融合网络。并提出了一种以两幅图像为输入的连体网络。实验表明,与siamese网络相比,早期融合网络可以从合成数据中获取更多的信息,并产生更好的检测性能。
•为了促进图像变化检测领域的研究,我们还提供了9个人工标注的数据集,详细内容见第IV -B节。
2相关工作
识别图像之间的差异区域是实现许多常见任务的最基本步骤之一。例如,它能够检查书籍封面的摄影图像和数字设计是否相同或不同,或者监控公共基础设施以检查是否有侵犯。
如前一节所述,差异可能是对象的插入或删除,也可能是场景[21]中特定对象或事件的转换。发现和定位不同之处的一种直接方法是在一对图像之间进行逐像素比较。该方法利用图像配准、图像噪声抑制等技术,可以消除噪声和微小变化[6]的影响。然而,当面对强烈的噪声或显著的变化[20]时,它往往不能获得预期的结果。
近年来,由于卷积神经网络具有良好的拟合和泛化能力,将其应用于变化检测任务的趋势越来越大。此外,引入孪生网络是一个有吸引力的选择。由于其独特的双串联输入和相似性测量,siamese网络能够比较不同背景下的图像,特别是在变化检测领域。Zhan等人提出了一种基于siamese网络的基于权值对比损失的航空光学图像变化检测方法。Zhang等人[23]使用连体CNN来检测城市环境中的地形变化。
近年来,已经出现了相当多的变化检测的基准数据集,其中视频监控和遥感应用最为普遍。2012年,Goyette等人推出了changedetection.net (CDnet)基准,这是一个专门用于评估变化和运动方法的视频数据集。在2014年,Wang等人扩展了数据集,并为2014年IEEE变化检测研讨会评估了多达14种变化检测方法。
3提出网络
为了检测图像对之间的差异,我们将“变化”视为一个对象。然后可以执行检测任务描述为
![]()
其中image pair (Itest, Iref)作为输入X, Y包含图像中“变化”的位置。这里,我们利用基于cnn的网络作为变换函数F。我们提出了两种基于目标检测的编码器-解码器网络架构:CUNet-EF和CUNet-Diff。这两种体系结构如图2所示。
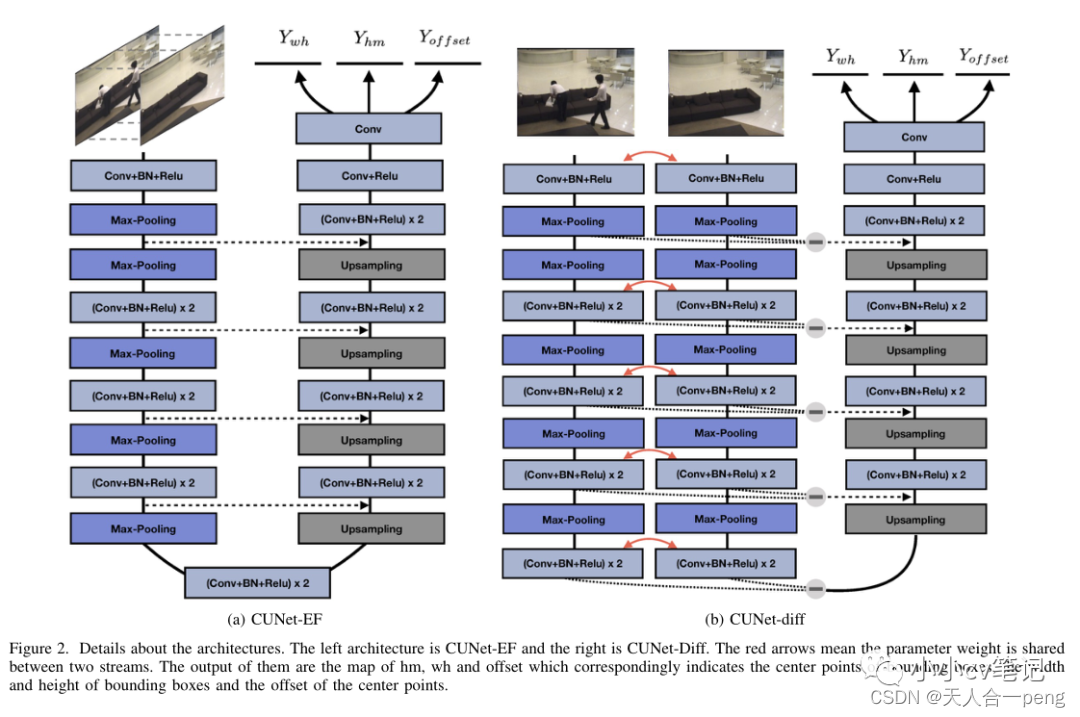
A. EF和Diff
为了检测差异,网络的输入是一个图像对。因此,我们需要改变传统的以cnn为基础的网络来适应它。采用早期融合(EF)和Siamese- Diff (Diff)两种调整方案。EF意味着我们将图像对堆叠起来,并将其直接用作网络的输入。而对于Diff,像传统的Siamese网络一样,两个具有相同架构和权重的流作为编码层,融合操作直到解码部分才完成。在这里,我们通过取编码器输出之间差的绝对值来融合它们,而不是堆叠它们。[26]表明,两种方案在图像分割领域的性能大致相同。我们想探究它们在目标检测领域的性能,结果如表三所示。
B.编码器和解码器
我们网络的主干网是一个基本的编解码器架构U-Net[27],它通过下采样、上采样路径和跳过连接充分利用了位置信息和上下文信息。但是,在分割任务中通常采用这种编码器-解码器结构,其最终输出大小通常与解码部分的输出大小相同,以充分利用特征信息。因此,我们做了一些改变,使其可以用于目标检测。遵循[28]的思想,使用与解码部分大小相同的基于映射的检测输出。
网络的输入分辨率为512 × 512,预卷积后,输入U-Net的是大小为128×128的特征表示,而不是原始图像。经过编码器和解码器的处理后,进行多次卷积运算得到最终输出,包括三个映射Yhm, Ywh和Yoffset集合。这三张图的大小都是128 × 128, 128 × 128地图的一个元素可以被看作是512 × 512图像的相应区域。Yhm∈[0,1]128×128×1的元素表示该区域是否存在“变化”的中心点。Ywh∈R128×128×2推导出每个中心点的边界框的宽度和高度。由于从512降采样到128,整数除法会导致中心点位置的精度下降。因此,Yoffset集合是需要预测原图像中心点的偏移量。图3显示了一个直接的描述。
c .损失
图像对的损失函数由Lhm, Lwh和Loffset集合组成。对于中心点的目标函数,我们使用焦损[29]的变体,根据[28]。使用高斯函数生成地面真中心点映射Ghm∈[0,1]128×128×1,即将真点赋值为1,将真点周围的点按高斯函数赋值递减。
其中,p表示原输入中心点的位置,⌊p4⌋是映射到Ghm的地真值位置。
我们的方法和[28]的主要区别在于,我们只关心一个对象的“变化”,所以一些复杂的处理是不必要的,被丢弃了。Lhm的公式是
其中,N为图像对(I1,I2)中中心点的个数,α和β为赋值为2和4的超参数。这意味着预测点离中心点的距离越远,惩罚就越严重。
对于Lwh和Loffset集合,我们只考虑真实的中心点,使用L1-loss对它们进行回归。
式中Gp wh表示中心点p的宽度和高度的基本真值。
总的损失是
经过多次实验,本课题取平衡参数λwh = 0.1和λoffset = 1。
4数据集生成
由于现有的图像变化检测数据集泛化性能差,并且收集和标记数据成本高且耗时长,因此我们提出了一种简单而有效的数据集生成方法。此外,我们还提供了来自不同来源的9个真实数据集来评估合成数据的泛化能力。
A.关于合成数据的详细信息
在这里,我们将详细介绍如何生成合成数据。生成带有“change”的图像对的过程可以概括为以下步骤。首先,我们选择一个背景图像和一些需要粘贴的合成“变化”。我们尝试了三种不同的“改变”,常规裁剪改变,实例改变和不规则裁剪改变。图4显示了它们的示例。第二种方法是随机选择粘贴位置。值得注意的是,我们并不关心合成图像对的真实感,而是关心粘贴部分与背景的融合以及如何产生更多的局部特征。因此,为了使其更具信息性和自然性,施加了一些限制。下一节将详细叙述该过程,第五节-第二节将讨论合成数据性能的实验
1)关于“变化”的详细信息:对于常规裁剪更改,我们剪切和粘贴的图像来自同一数据集,以确保图像质量。此外,我们发现“变化”规模的多样性是显著的。如果检测器之前没有学习到这样的信息,它很难预测一个大的“变化”的边界框。因此,我们使用“基于锚框”的方法来获取更多的空间信息。
[30]中提出的锚框是一组预定义的具有一定高度和宽度的边界框,用于捕获特定对象的比例和长宽比。在数据生成视图中,我们利用它来保持“变化”的长宽比和面积的多样性。经过多次实验,我们采用的纵横比为1:1、1:2、1:3、1:5、1:7,以50%的概率旋转90◦来扭转宽度或高度的主导特征,对应的生成数比例约为3:3:3:2:2。对于面积,我们定义S为图像中“变化”面积的比例,其中Ssmall表示范围[0.005,0.05],Smedium表示范围[0.05,0.25],Slarge表示[0.25,0.5]。它们的对应比例约为4:2:1。
此外,让“变化”看起来更自然。在某些情况下,我们从一个图像中裁剪一个多边形而不是矩形,并将其粘贴到目标图像中。这种“变化”被称为不规则裁剪变化。制作它的基本思路是绕椭圆走一圈,每次采取随机的角度步骤,每一步在随机的半径处放置一个点。我们使用三个参数,n,不规则性和尖形来控制多边形的形状。这里n控制多边形的边数;不规则性控制着点在椭圆周围的角度是否均匀分布,而尖尖性控制着点与椭圆之间的差异。图5显示了一个示例。经过多次试验,确定n为10,尖峰性在0 ~ 0.15之间随机选取,不规则性在0.4 ~ 0.7之间随机选取。
对于实例变化,采用实例分割方法提取实例。值得注意的是,实例与背景图像来自相同的数据集。我们认为这种方法已经保证了“变化”的多样性,不需要使用“基于锚框”的方法。
2)限制:对所有的“变化”应用旋转,以丰富局部特征信息。不同旋转角度的“变化”可以反映不同的特征信息。
此外,边缘模糊的应用,使融合更自然。为了平滑背景边缘和“变化”之间的剧烈变化,我们对边缘应用高斯模糊。在我们的实验中,如果该值过高,模糊效果很明显,但结果并不令人满意。所以最后,这个值在0.8到1.1之间随机选择,使得边缘模糊效果不那么容易被眼睛观察到,但从像素值的角度来看,确实使边缘更加自然。
此外,为了提高鲁棒性,图像对中存在一定的噪声是必要的。因此,将高斯噪声和颜色变化随机施加到图像对中的一个图像上,以产生干扰。图6显示了一个生成带有限制的不规则裁剪更改的图像对的过程示例
B.关于真实世界数据集的细节
如前所述,真实世界的数据集很少包含这样的对象。但是一些视频的帧和可靠的公共数据集可以被视为包含“变化”的图像对。CDNet[25]是一个具有挑战性的数据集,用于语义变化检测任务,包括各种条件下的监控视频帧。CCTV - battles[31]是一个新颖且具有挑战性的数据集,包含1000个真实战斗视频。SPID[32]是为使用监控图像或视频进行行人检测研究工作而收集的数据集。其中一些视频或图像被采样并人工标记,以适应目标检测领域的图像变化检测。此外,我们还从视频网站BiliBili上收集了一些关于宠物的监控视频。此外,一个来自中国电力公司的数据集,该数据集希望通过发现温度的“变化”来检测异常情况设备,真实数据集的详细信息如表1所示。
5实验与结果
在本节中,我们将基于性能评估两种网络架构,并验证合成数据的有效性。我们进行了两组实验。在第一个实验中,我们希望找到生成具有最佳泛化能力的合成数据的最佳方法。在第二组实验中,我们想探讨“变化”的不同定义是否是一个重大障碍,以及利用少数样本是否可以克服它。
A.实现细节
1)生成:生成时,以COCO[33]数据集作为图像源。从COCO中选择一张图像作为主图像,并将最多5个“更改”对象粘贴到其上以形成图像对。每个裁剪更改都是从COCO图像中随机裁剪的。对于Instance Change,它是从一个实例集中随机选择的,该实例集是通过对COCO进行实例分割产生的。
2)训练:采用随机翻转、随机缩放、裁剪、颜色抖动等数据增强方法提高性能。我们使用Adam对该任务进行优化,初始学习率为1e−4。所有的网络都是在单个GTX 2080 Ti上计算的。
3)评价:为了衡量模型的性能,我们在所有实验中都采用IOU为0.5的平均精度(AP)。
B.实验和结果的细节
1)合成数据的性能和网络架构:为了探索哪些有限制的“改变对象”可以生成优秀的合成数据,我们尝试了不同的组合策略,并生成了8个不同的数据集。它们都可以作为训练数据集。此外,利用一个由Skating, BusStation和Sofa组成的真实世界数据集来表示不足的真实世界数据,以便与合成数据集进行性能比较。具体情况见表二。并以Road, Office, Factory, Fight, Pets, SJ-SPID 6个真实数据集作为测试集验证性能。训练时,batch size为32,epoch为240,每80 epoch学习率下降10倍。
结果见表三。由于合成数据集不能在所有测试集上都取得最好的结果,我们使用欧几里得距离来衡量合成数据集的泛化能力。可表述为:
其中,X表示由训练数据集训练的网络的测试结果组成的集合,Xbest表示由每个测试集中的最佳测试结果组成的集合。
结果表明,真实世界数据不足不能克服不同“变化”任务之间的差距,在集上表现不佳,而所有具有模仿特征信息的合成数据集都优于它。
在综合数据集的比较中,Instance Change是最差的。这是因为在实例分割的过程中不可避免地会有损失,而且提取出来的一些实例的外观并不令人满意。此外,不同对象的混合可能会导致改进。此外,研究结果还表明,不同的体系结构对合成数据有不同的偏好。CUNet-Diff在Exp.6上表现最好,而CUNet-EF在Exp.7上表现最好。对比两种网络架构,虽然在[26]中,两种网络架构在变化检测的图像语义分割领域匹配良好,但在目标检测领域,结果表明CUNet-EF更适合该任务。
因此,我们认为CUNet-EF比CUNet-Diff更好,“带旋转和边距模糊的裁剪变化”和“带旋转和边距模糊的不规则裁剪变化”(即Exp.7)的混合是生成数据的最佳方式。
虽然结果表明,与不足的真实数据相比,合成数据有了很大的改善,并且具有很好的泛化能力,但SJ-SPID、Fight和Pets的最佳结果并不理想。我们认为导致它的是“变化”。它的意思是,不同场景关注的“变化”是不同的。对于图像对的变化,在某些情况下,它被考虑在内,但在其他情况下,它被视为噪音。我们相信场景中的一些示例包含“更改”的定义,并利用它们可以进行改进。接下来用这些样本进行的实验证明了这一点。
2)利用少量样本:为了证明在不同场景下对“变化”的不同定义成为有前景的泛化能力的重大障碍,在三个性能较差的数据集Fight, SJSPID和Pets上设计了少量样本的微调和混合实验。对于微调,从真实数据集中抽取10%的数据作为少量样本,以微调Exp.7中的预训练模型。而对于混合,10%的数据与使用Exp.7方法生成的合成数据混合,我们在其上训练模型。为了与它们进行比较,我们也在这三个样本上从头开始训练模型。选择CUNet-EF网络是因为其性能更好。图7显示了不同模型的检测结果示例。很明显,没有微调的模型混淆了“什么是变化”和“不同变化之间的边界是什么”。它检测到的边界框对报告噪音(如阴影)很敏感,在这种情况下,我们不认为这是“变化”。而对于从头开始训练的模型,由于缺乏对“变化”大小的了解,它检测到的边界框不能覆盖正确的对象,甚至不能识别它们。对于混合数据模型和微调模型,两种方法都利用了少量样本中包含的隐式信息,并在一定程度上了解了任务的重点。
其中AP0.5如表4所示。可以看出,这几个样本不能提供足够的特征信息,使得从头训练的模型性能不佳。然而,当它们与合成数据结合使用时,我们可以得到令人满意的结果。与混合方法相比,微调方法具有更好的鲁棒性。
本文提出了一种混合“旋转和边缘模糊的规则裁剪变化”和“旋转和边缘模糊的不规则裁剪变化”的技术,用于合成基于目标检测的图像变化检测训练图像对。并提出了一种早期融合网络来解决这一问题。结果表明,在合成数据上训练的模型在多个测试集上具有较强的鲁棒性,而在不足的真实数据上训练的模型则无法与之相比。此外,少量样本实验表明,“变化”的不同定义是提高泛化能力的一个困难障碍,利用少量样本对合成数据上训练的模型进行微调可以克服这一障碍,并有很大的改进。从实用的角度来看,我们的技术可以有效地解决训练数据不足的问题。此外,还提供了9个人工标注的数据集,供未来研究使用。
DRÆM -用于表面异常检测的判别重建特征训练 (qq.com)
DRÆM -用于表面异常检测的判别重建特征训练

DRÆM是基于重构的经典异常检测检测论文,也是异常检测领域经常对比的方法,DRÆM由一个重建子网络和一个鉴别子网络组成,重构子网络训练重构具有语义上合理的无异常内容,重构方法的基本原理是网路无法重构异常区域,同时,判别子网络学习重构异常特征,并根据重构和原始外观生成准确的异常分割图。
论文题目:
DRÆM – A discriminatively trained reconstruction embedding for surface anomaly detection
摘要
视觉表面异常检测的目的是检测图像局部明显偏离正常外观的区域。最近的表异常检测方法依赖于生成模型来准确重建正常区域,但在异常上失败。这些方法仅在无异常的图像上进行训练,并且通常需要手工制作的后处理步骤来定位异常,这阻碍了优化特征提取以获得最大的检测能力。除了重建方法外,我们将表异常检测主要视为一个判别问题,并提出了一个判别训练的重建异常嵌入模型(DRÆM)。该方法学习异常图像的联合表示及其无异常重建,同时学习正常和异常示例之间的决策边界。该方法可以直接定位异常,而不需要对网络输出进行额外复杂的后处理,并且可以使用简单和一般的异常模拟进行训练。在具有挑战性的MVTec异常检测数据集上,DRÆM在很大程度上优于当前最先进的无监督方法,甚至在广泛使用的DAGM表面缺陷检测数据集上提供接近全监督方法的检测性能,同时在定位精度上大大优于它们。
1. 介绍
表面异常检测解决了偏离正常外观的图像区域的定位问题(图1)。一个密切相关的一般异常检测问题将异常视为与非异常训练集图像显著不同的整个图像。相比之下,在表面异常检测问题中,异常只占图像像素的一小部分,并且通常接近训练集分布。这是一项特别具有挑战性的任务,在质量控制和表面缺陷定位应用中很常见。

在实践中,异常的外观可能会有很大的变化,并且在质量控制等应用程序中,存在异常的图像是罕见的,并且手动注释可能会花费过多的时间。这导致训练集高度不平衡,通常只包含无异常的图像。因此,最近在设计健壮的地表异常检测方法上投入了大量的努力,这些方法最好只需要很少的人工注释监督。
重建方法,如Autoencoders和gan,已经被广泛探索,因为它们可以学习强大的重建子空间,仅使用无异常图像。利用训练中未观察到的异常区域重建能力差的特点,通过对输入图像与其重建图像之间的差值进行阈值分割来检测异常。然而,确定与正常外观没有本质差异的异常存在仍然具有挑战性,因为这些异常通常被很好地重建,如图2左上角所示。然而,确定与正常外观没有本质差异的异常存在仍然具有挑战性,因为这些异常通常被很好地重建,如图2左上角所示。
因此,最近的改进考虑了从通用网络和专门用于无异常图像的网络中提取的深度特征之间的差异。判别也可以表示为深度子空间中非异常纹理密集聚类的偏差,因为形成这样一个紧凑的子空间可以防止异常被映射到接近无异常样本的位置。生成方法的一个常见缺点是它们只从无异常数据中学习模型,并且没有明确优化判别异常检测,因为在训练时没有可用的正例(即异常)。合成异常可以用来训练判别分割方法,但这会导致对合成外观的过度拟合,并导致学习到的决策边界难以泛化到真实异常(图2,右上)。我们假设,通过在关节、重构和原始外观以及重构子空间上训练一个判别模型,可以大大减少过拟合。这样,模型就不会过度拟合合成的外观,而是学习原始和重建的异常外观之间的局部外观条件距离函数,它可以很好地推广到实际异常的范围内(见图2,底部)。
为了验证我们的假设,作为我们的主要贡献,我们提出了一个新的深层表异常检测网络,该网络以端到端的方式对综合生成的just-out- distribution模式进行判别性训练,这些模式不必忠实地表示目标域异常。该网络由重建子网络和判别子网络组成(图3)。重建子网络被训练学习无异常重建,而判别子网络学习原始图像和重建图像联合外观的判别模型,生成高保真的逐像素异常检测图(图1)。与学习代理生成任务的相关方法相比,所提出的模型是判别性训练的,但不要求合成异常外观与测试时的异常紧密匹配,并且在很大程度上优于最近的、更复杂的、最先进的方法。
2. 相关工作
许多表异常检测方法侧重于图像重建,基于图像重建误差检测异常。自编码器通常用于图像重建。然后,图像的异常分数基于图像重建质量,或者在对抗性训练的自编码器的情况下,基于鉴别器输出。在[24,23]中,训练GAN[13]生成符合训练分布的图像。在[23]中,另外训练了一个编码器网络,该编码器网络找到输入图像的潜在表示,当被预训练的生成器用作输入时,将重建损失最小化。然后根据重建质量和鉴别器输出得出异常评分。在[29]中,训练插值自编码器来学习分布内样本的密集表示空间。然后,异常评分基于鉴别器,训练以估计输入-输入和输入-输出联合分布之间的距离,然而,地表异常检测方法仍然是生成的,因为鉴别器评估重建质量。
除了常用的图像空间重建方法外,还可以使用预训练网络特征的重建方法进行表异常检测。异常检测是基于一个假设,即预训练网络的特征不会被另一个只在无异常图像上训练的网络忠实地重建。或者表异常检测是识别高斯拟合的显著偏差预训练网络的无异常特征。这需要无异常视觉特征的单峰分布,这在不同的数据集上是有问题的。[16]提出了一类基于变分自编码器梯度的注意力图作为输出异常图。然而,该方法对接近正态样本分布的细微异常很敏感。
近年来,基于patch的一类分类方法被考虑用于表异常检测。这些都是基于一类方法,这些方法试图通过假设无异常数据的单峰分布来估计无异常数据周围的决策边界,该决策边界将其与异常样本分开。这一假设在表异常资料中经常被违背。
3. DRÆM
本文提出的判别联合重构异常嵌入方法(DRÆM)由重构子网络和判别子网络组成(见图3)。重构子网络经过训练,可以隐式检测和重构语义上合理的无异常内容的异常,同时保持输入图像的非异常区域不变。同时,判别子网络学习一种联合重构-异常嵌入,并将重构后的图像和原始图像拼接在一起,生成精确的异常分割图,异常训练样例是通过在无异常图像上模拟异常的概念上简单的过程创建的。这种异常生成方法提供了任意数量的异常样本和像素完美的异常分割图,可以在没有真实异常样本的情况下用于训练所提出的方法。
3.1. 重建子网络
重构子网络被表述为一个编码器-解码器架构,该架构将输入图像的局部模式转换为更接近正态样本分布的模式。训练网络从模拟器获得的人为损坏的图像Ia中重建原始图像I(参见3.3节)。
l2损失通常用于基于重建的异常检测方法,然而,这假定相邻像素之间是独立的,因此,在[5,31]中还使用了基于patch的SSIM损失:
其中H和W分别为图像I的高度和宽度,Np等于i中的像素个数,Ir为网络输出的重构图像。
SSIM(I, Ir)(I, j)为I和Ir patch的SSIM值,以图像坐标(I, j)为中心,因此重建损失为:
其中λ是一个损失平衡超参数。注意,从下游判别网络(第3.2节)获得额外的训练信号,该网络通过检测重建差异来进行异常定位。
3.2. 判别子网络
鉴别子网采用类似U-Net的架构。子网络输入Ic被定义为重构子网络输出Ir和输入图像I的通道级联。由于重构子网络的正态恢复特性,I和Ir的联合外观在异常图像中有显著差异,为异常分割提供了必要的信息。在基于重建的异常检测方法中,使用相似度函数(如SSIM)将原始图像与其重建图像进行比较,从而获得异常图,然而,表面异常检测特定的相似度度量很难手工制作,而判别子网络则自动学习合适的距离度量。该网络输出一个与i大小相同的异常评分图Mo。在判别子网络输出上应用Focal Loss (Lseg),以提高对硬样本精确分割的鲁棒性。
同时考虑两个子网络的分割目标和重构目标,训练中使用的总损失DRÆM为
其中,Ma和M分别为真值和输出异常分割掩码。
3.3. 模拟异常生成
DRÆM不需要模拟真实地反映目标域的真实异常外观,而是生成刚出分布的外观,从而可以学习适当的距离函数,通过偏离正态来识别异常。所建议的异常模拟器遵循此范例。
由Perlin噪声发生器生成噪声图像,以捕获各种异常形状(图4,P),并通过随机均匀采样的阈值(图4,Ma)进行二值化,得到异常图Ma。从与输入图像分布无关的异常源图像数据集中采样异常纹理源图像A(图4,A)。然后,受RandAugment的启发,通过一个集合应用随机增强采样从集合中采样的3个随机增强函数:{posterize, sharpening, solarize, equalize,亮度变化,颜色变化,自动对比度}。增强的纹理图像A被异常映射Ma掩盖,并与I混合,以创建刚出分布的异常,从而有助于收紧训练网络中的决策边界。因此,增广训练图像Ia定义为
其中Ma是Ma的逆⊙是元素的乘法运算,β是混合中的不透明度参数。该参数从一个区间均匀采样,即β∈[0.1,1.0]。随机混合和增强可以从单个纹理生成不同的异常图像(参见图5)。
因此,上述模拟器生成包含原始无异常图像I、包含模拟异常Ia的增强图像和像素完美异常掩码Ma的训练样本三胞胎。
3.4. 表面异常定位与检测
判别子网络的输出是一个像素级的异常检测掩码Mo,可以直接解释为图像级的异常评分估计,即图像中是否存在异常。
首先,采用均值滤波卷积层对Mo进行平滑处理,聚合局部异常响应信息;最终的图像级异常分数η由平滑异常分数图的最大值计算得到:
其中FSF ×sf是大小为sf ×sf的平均滤波器,并且*是卷积算子。在初步研究中,我们训练了一个用于图像级异常分类的分类网络,但没有观察到比直接评分估计方法有改进(5)。
4. 实验
对DRÆM进行了广泛的评估,并与最近的无监督表面异常检测和定位技术进行了比较。此外,通过消融研究评估了所提出方法的各个组成部分和模拟异常训练的有效性。最后,通过将DRÆM与最先进的弱监督和完全监督表面缺陷检测方法进行比较,将结果置于更广阔的视野中。
4.1. 与无监督方法的比较
DRÆM在最近具有挑战性的MVTec异常检测数据集上进行了评估,该数据集已被建立为评估无监督地表异常检测方法的标准基准数据集。我们评估了DRÆM在表异常检测和定位方面的任务。MVTec数据集包含15个对象类,具有不同的异常集,可以对地表异常检测方法进行一般评估。MVTec数据集的异常示例如图8所示。为了进行评估,使用了异常检测中的标准度量AUROC。图像级AUROC用于异常检测,基于像素的AUROC用于评估异常定位。然而,AUROC在地表异常检测设置中不能很好地反映定位精度,因为只有一小部分像素是异常的。原因是假阳性率由先验的非常高的非异常像素数量所主导,因此尽管有假阳性检测,假阳性率仍保持在较低水平。因此,我们另外报告了像素平均精度度量(AP),它更适合高度不平衡的类别,特别是表面异常检测,其中精度起着重要作用。
在我们的实验中,网络在MVTec异常检测数据集上进行了700次epoch的训练。学习率设为10−4,400次和600次后乘以0.1。在训练过程中,使用(−45,45)度范围内的图像旋转作为对无异常图像的数据增强方法,以减轻由于相对较小的无异常训练集大小而导致的过拟合。使用可描述纹理数据集作为异常源数据集。
图8给出了一些获得的定性示例。可以观察到,获得的异常掩模非常详细,与给定的真值标签相似,精度很高。因此,DRÆM在所有MVTec类别中实现了最先进的定量结果,用于面异常检测和定位。
表异常检测 表1将DRÆM与最近的图像级地表异常检测方法进行了定量比较。DRÆM显著优于所有最近的地表异常检测方法,在15个类别中有9个类别的AUROC最高,在其他类别中也取得了类似的结果。它比之前最先进的方法高出2.5个百分点。某些类的性能下降可以用接近正态图像分布的特别困难的异常来解释,物体的某一部分的缺失尤其难以检测。缺少对象特征的区域通常包含其他常见特征。这使得这些异常很难与无异常区域区分开来。图6中可以看到一个例子,其中一些晶体管引线被切断了。真实度标志着断铅应该是异常的区域。DRÆM只检测到切割引线的一小部分区域的异常特征,因为背景特征在训练期间是常见的。
异常定位 表2将DRÆM与像素级异常检测的最新技术进行了比较。DRÆM在AUROC得分方面取得了与以前最好的方法相当的结果,在AP方面超过了最先进的13.4个百分点。在15个类别中,有11个类别的AP成绩较好,与其他类别的水平相当。与目前最先进的方法Uninformed Students和PaDim的定性比较如图7所示。DRÆM在异常分割精度上取得了显著的提高。
详细的检查表明,一些检测误差可归因于不准确的真值标签上的模糊异常。图6中显示了一个例子,其中真实值覆盖了药丸的整个表面,但只有黄色点是异常的。DRÆM生成了一个异常地图,它正确地定位了黄点,但与地面真相面具的差异
4.2. 消融实验
DRÆM设计选择通过实验组进行分析,评估(i)方法架构,(ii)异常外观模式的选择和(iii)低扰动示例生成。结果在表3中按灰色阴影进行视觉分组。
体系结构 通过将重建子网络DRÆM从管道中移除并单独训练判别子网络,评估重建子网络对下游地面异常检测性能的影响。实验结果如表3所示。请注意,与完整的DRÆM架构相比,性能有所降低(表3,实验DRÆM)。性能下降是由于判别子网络对模拟异常的过拟合,不能忠实地表示真实异常。
其次,通过评估重建子网络作为基于自编码器的表面异常检测器,分析了重建子网络单独的判别能力。利用SSIM函数将子网的重构图像输出与输入图像进行对比,生成异常图。该方法的实验结果如表3,Recon.-AE。-AE优于最近基于自编码器的地表异常检测方法AESSIM(结果见表2)。这表明模拟异常训练在基于自编码器的训练中引入了额外的信息,但从与DRÆM的性能差距来看,SSIM相似函数可能不是提取异常信息的最佳方法。
事实上,使用最近提出的相似度函数MSGMS提高了性能,但与使用整个DRÆM架构相比,结果仍然明显差,这表明为了获得最佳结果,重构和判别部分都是必需的。
为了进一步强调DRÆM主干的贡献,我们将其完全替换为最新的有监督的判别异常检测网络,并使用模拟的异常重新训练(表3,Bo + zi + c等)。性能大幅下降,这进一步支持了学习异常偏离正常程度的能力,而不是异常或正常的外观。
异常外观模式 在异常模拟器中使用ImageNet[12]作为纹理源对DRÆM进行重新训练,以研究异常生成数据集(表3中的DRÆMImageN et)的影响。结果与使用小得多的DTD数据集相当。图9显示了在不同异常源数据集大小下的性能。结果表明,增强和不透明度随机化在允许少量纹理图像(少于10张)的情况下大大提高了性能。作为极端情况,异常纹理是生成为随机采样颜色的均匀区域(DRÆMcolor)。请注意,DRÆMcolor仍然获得了最先进的结果,进一步表明DRÆM不需要模拟与真实异常密切匹配。
用矩形区域噪声发生器代替柏林噪声发生器,评价了异常形状发生器的影响。因此,异常掩码是通过对异常区域的多个矩形区域进行采样来生成的(表3中的DRÆMrect)。对矩形异常进行训练只会导致性能略有下降,这表明模拟的异常形状不必是真实的,也可以很好地推广到现实世界的异常。异常外观消融实验中产生的异常示例如图10所示。
低扰动的例子 异常源图像增强和不透明度随机化负责收紧无异常训练分布周围的决策边界。表3报告了DRÆM变体训练的结果(i)没有图像增强和不透明度随机化(DRÆMno aug), (ii)只使用图像增强(DRÆMimg aug)和(iii)只使用不透明度随机化(DRÆMβ)。虽然DRÆMno aug和DRÆM之间存在明显的定位性能差距,但在训练中使用不透明度随机化可以显著缩小这一差距,即使没有图像数据增强。
4.3. 与监督方法的比较
监督方法需要在训练时进行异常注释,并且不能在MVTec上进行评估。因此,我们将DRÆM与包含10个纹理对象类的DAGM数据集上的监督方法进行比较小的异常在视觉上与背景非常相似,这使得数据集对无监督方法特别具有挑战性。
DRÆM仅在使用与先前实验相同的参数的无异常训练样本上进行训练。在该数据集上使用标准评估协议-挑战在于分类图像是否包含异常;定位精度不测量,因为异常只是粗略标记。
表4显示,最好的全监督方法几乎可以完美地对异常图像进行分类,而RIAD和US等最先进的无监督方法则难以在高度纹理化的区域上识别细微的异常。DRÆM显著优于这些方法,甚至大大优于弱监督的CADN,其分类性能接近最好的全监督方法,这是一个显著的结果。
此外,DRÆM在该数据集的异常定位精度方面优于所有监督方法。由于训练图像只是粗略地标注了近似覆盖表面缺陷和包含背景的椭圆,因此监督方法在测试图像中也会产生不准确的定位。相反,DRÆM根本不使用标签,因此生成更精确的异常图,如图11所示。
5. 结论
提出了一种判别式端到端可训练表面异常检测与定位方法DRÆM。DRÆM在表面异常检测任务上比MVTec数据集上的现有技术高出2.5 AUROC点,在定位任务上高出13.5 AP点。在DAGM数据集上,DRÆM提供了接近完全监督方法的异常图像分类精度,而在定位精度上优于它们。这是一个显著的结果,因为DRÆM并不是针对真实的异常进行训练的。事实上,详细的分析表明,我们通过重建子网络学习联合重建-异常嵌入的范式比标准方法显著改善了结果,并且通过学习简单模拟中重建的偏差程度可以很好地估计准确的决策边界,而不是学习正态或真实异常外观。

















 2485
2485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









