







引言:边缘AI的热潮
随着人工智能技术的不断突破,尤其是在大语言模型(LLM)、计算机视觉、语音识别等领域的广泛应用,越来越多的企业和开发者开始关注“边缘AI”的潜力。传统AI部署依赖云端资源,虽然计算能力强大,但在隐私保护、延迟控制和带宽资源方面存在诸多限制。随着5G和边缘计算技术的发展,将AI模型部署在靠近终端设备的边缘节点成为新趋势。
边缘AI的关键挑战之一,是如何在资源受限的设备上部署和运行大模型,满足实时响应与隐私保护的需求。本文将围绕“大模型是否能在边缘部署”这一核心问题展开分析,探讨轻量化模型的发展、技术路径、典型架构与应用场景,为开发者与企业提供实践参考。
一、边缘AI与大模型的基本认知
什么是边缘AI?
边缘AI是指在靠近数据源的边缘设备(如摄像头、传感器、移动设备、边缘服务器)上,部署人工智能算法实现本地推理、数据处理与决策反馈的技术。相比传统云端AI,它具备低延迟、高实时性、隐私性强等优势。
什么是大模型?
大模型,尤其以GPT、BERT、LLaMA等为代表的预训练模型,具有超强的泛化能力,但也伴随着参数量大、资源需求高、推理耗时长等问题。将这类模型直接部署在边缘设备上几乎不现实,因此轻量化与本地适配成为关键方向。
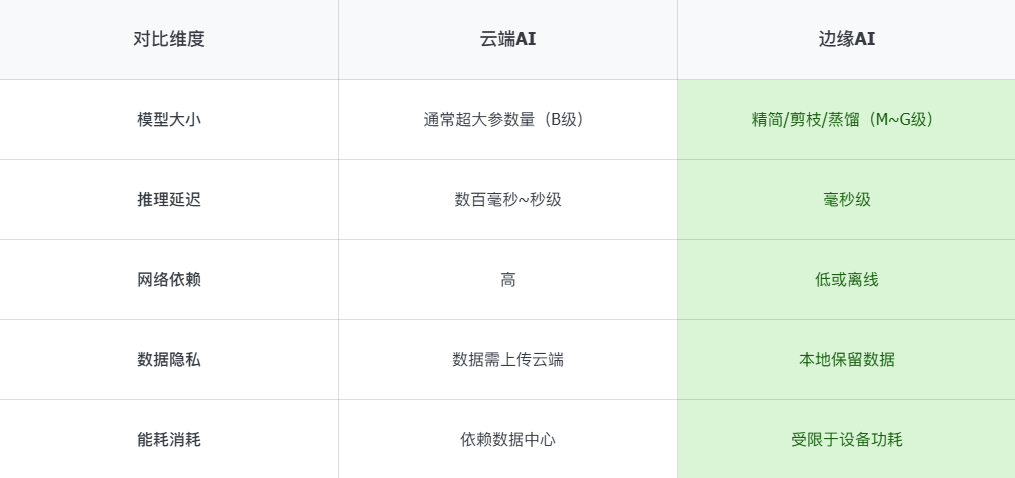
二、大模型边缘部署的技术挑战
尽管边缘AI带来了诸多优势,但要将大模型真正部署到边缘设备,还需解决以下技术难点:
-
算力资源受限:边缘设备的CPU/GPU/NPU性能远低于数据中心,无法承载完整的大模型。
-
存储空间不足:大模型往往包含数百MB至数GB的参数,远超普通嵌入式设备的容量。
-
能耗与功耗敏感:边缘部署需要考虑设备续航与散热,重模型运行会加剧资源消耗。
-
网络带宽限制:实时依赖云端通讯会造成延迟,必须保证一定程度的本地自治推理。
这些问题促使开发者探索大模型“瘦身”策略以及边缘硬件的适配路径。
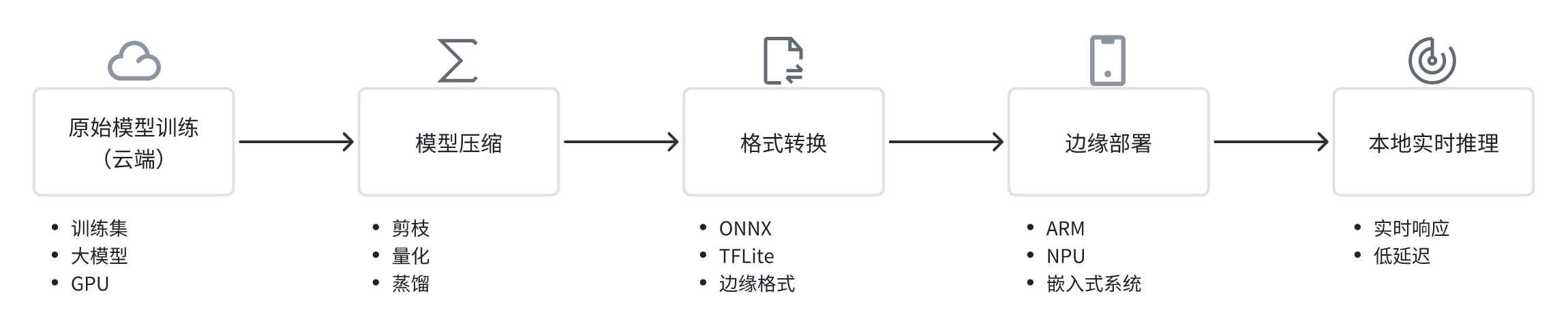
三、轻量化模型与本地推理技术
为推动大模型在边缘落地,当前技术界已发展出多种轻量化与模型压缩方法,包括:
1. 模型剪枝(Pruning)
通过移除不重要的神经元或连接,减少模型参数量与计算复杂度,常用于卷积神经网络(CNN)压缩。
2. 量化(Quantization)
将模型权重从32位浮点数压缩为8位甚至更低精度数据,在硬件支持下大幅提升推理速度、降低能耗。
3. 知识蒸馏(Knowledge Distillation)
利用大模型(教师)指导小模型(学生)学习,从而保留关键能力的同时缩减模型体积。
4. 架构优化(MobileNet、TinyML)
设计本身适配边缘场景的轻量神经网络结构,例如MobileNet、SqueezeNet、EfficientNet等。
这些方法通常结合使用,并辅以边缘硬件平台(如NVIDIA Jetson、Google Coral、华为Atlas 200 DK)的优化支持。
四、边缘AI典型架构解析
典型的边缘AI系统架构如下图所示:
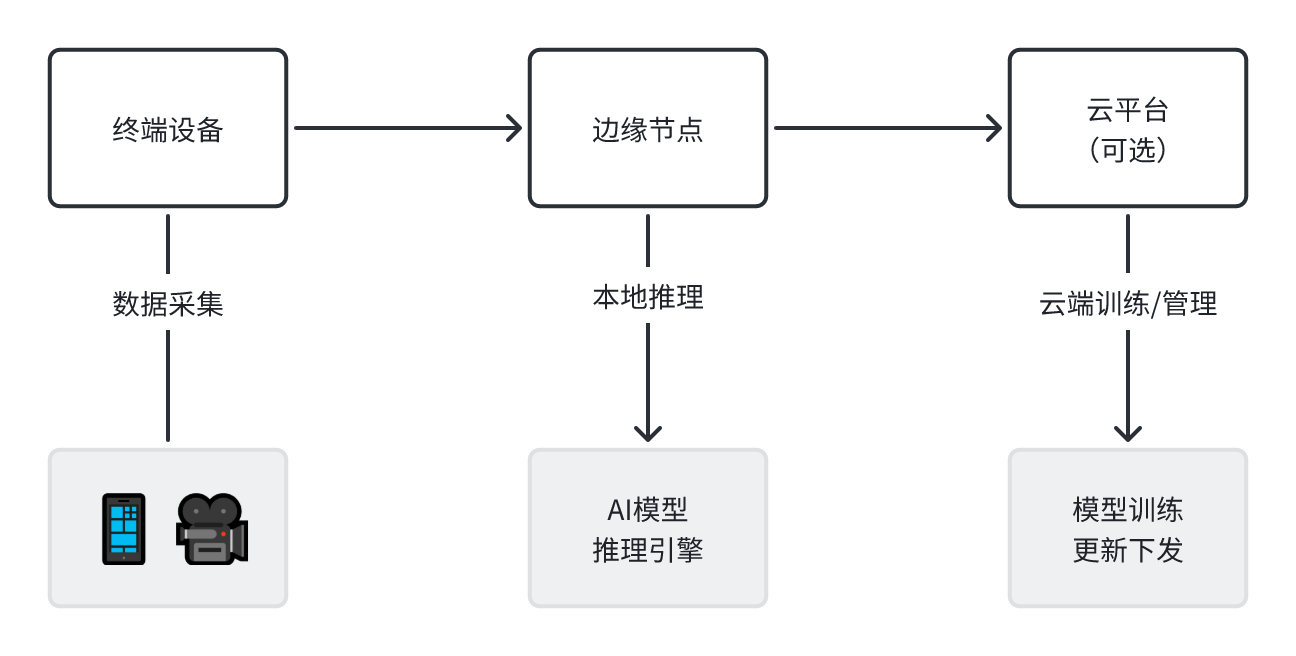
分层协同思路:
-
终端侧负责数据采集与初步处理。
-
边缘侧承担主要推理任务,确保低延迟响应。
-
云端用于模型训练、统一管理与策略调整。
在AI模型更新、策略下发、安全运维等方面,云端仍扮演重要角色,而边缘负责实时反馈和执行。
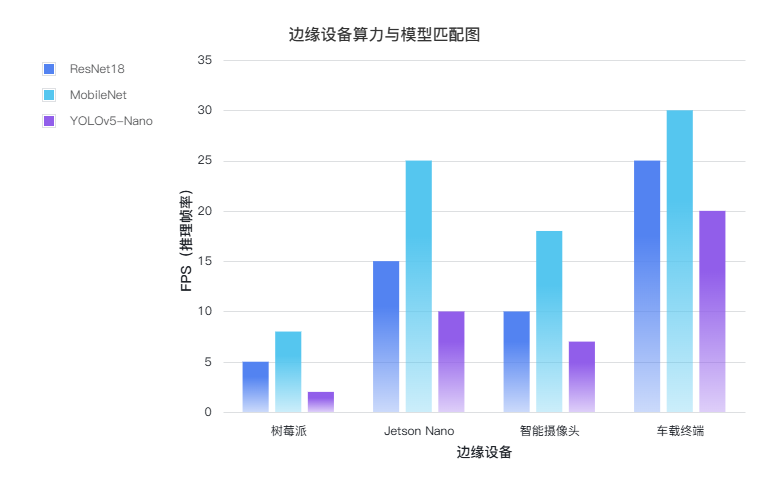
五、行业应用案例解析
智慧交通
-
自动驾驶、红绿灯调控、交通流量分析。
-
利用边缘部署的AI进行图像识别,实现毫秒级响应。
工业制造
-
设备故障预警、视觉检测。
-
本地AI模型可在发生异常时快速断电或停止生产线。
智慧医疗
-
可穿戴设备监测健康、边缘推理预警心律异常。
-
避免敏感数据上云,增强隐私保护。
零售安防
-
顾客行为分析、异常监控。
-
边缘AI可就地完成视频处理与结果判断。
能源与电网
-
远程变电站巡检、边缘图像识别。
-
保证边远地区设施的实时智能化运行。

六、结语:边缘AI的未来展望
随着硬件算力持续提升、模型压缩技术日益成熟,大模型“下沉”到边缘已逐步从理论走向现实。未来,结合5G/6G、边缘AI芯片、本地LLM等新技术,我们有望在手机、车载终端、摄像头中见到更多智能化AI部署。
边缘AI的落地不再是技术挑战本身,而是系统设计、模型选择、硬件匹配与生态协同的综合工程。在智能化时代的下一个十年,边缘与AI的结合将重新定义万物智能的可能边界。
延伸阅读:
《深入云计算安全战场:零信任架构如何在10毫秒内阻断APT攻击》
《laas、PaaS、SaaS是什么?一文看懂云计算的三种服务模式》
《什么是云计算?入门篇》

















 1277
1277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









