







关注公众号,发现CV技术之美
0
写在前面
对比学习已被广泛应用于训练基于Transformer的视觉语言模型的视频文本对齐和多模态表示学习等任务。在本文中,作者提出了一种新的token感知级联对比学习(TACo)算法,该算法利用两种技术改进了以往对比学习的缺点。
第一个是通过考虑单词的句法类别(比如:名词、动词、介词)来计算的token感知的对比损失 。这是由于作者观察到,对于视频-文本对,文本中的内容词(如名词和动词)比功能词(如介词,冠词)更容易与视频中的视觉内容对齐。其次,采用级联采样方法生成一组hard negative实例,以有效的进行多模态融合层的损失估计 。
为了验证TACo的有效性,在实验中,作者微调了一组下游任务的预训练模型,包括文本视频检索(YouCook2、MSR-VTT和ActivityNet)、视频动作定位(CrossTask)、视频动作分割(COIN)。
结果表明,与以往的方法相比,本文的模型在不同的实验设置中取得了一致的改进,在YouCook2、MSR-VTT和ActivityNet的三个公共文本视频检索基准数据集上达到了新的SOTA性能。
1
论文和代码地址

TACo: Token-aware Cascade Contrastive Learning for Video-Text Alignment
论文地址:https://arxiv.org/abs/2108.09980
代码地址:未开源
2
Motivation
在视觉语言(VL)研究的背景下,将语言与视频对齐是一个具有挑战性的主题,因为它需要模型来理解视频中呈现的内容、动态和因果关系。受BERT在自然语言处理中的成功启发,研究人员们对将基于Transformer的多模态模型应用于视频文本对齐和表示学习。
这些模型通常使用对比学习,对大量有噪声视频文本对进行预训练,然后再用zero-shot或者finetune的方式使之适用于各种下游任务中,比如text-video retrieval、video action segmentation、video question answering等等。
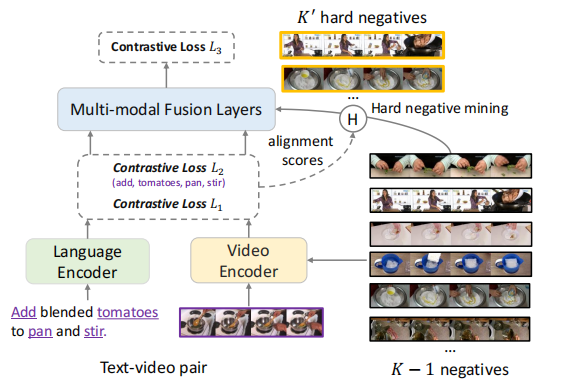
在本文中,作者提出了一种新的对比学习形式,token感知级联对比学习(TACo),以改进大规模预训练和下游特定任务的视频文本对齐。相比于传统的对比学习,TACo主要有两点不同:
第一个是通过考虑单词的句法类来计算的token感知的对比损失 。这是因为给定一个视频及其相应的文本,内容词,如名词和动词,比功能词更有可能与视频中的视觉内容对齐。传统的对比学习通常是在聚合视频和文本中所有帧和所有单词后计算损失(如上图中的损失L1或L3)。
相比之下,token感知的对比损失只使用一个子集计算,这些单词的语法类属于预定义集(例如,名词和动词),这迫使单个单词与视频对齐(即文中的L2损失),比如上图中的施加了特殊注意力的单词就是“add”, “tomatos”,“pan” ,“stir”。
第二种技术是级联采样方法 ,更加有效的训练多模态融合层。考虑一个batch的K个视频文本对。对于每一个视频-文本对,理想的情况是,使用剩余的K−1负视频或文本来计算多模态融合后的对比损失。
然而,考虑到对比损失与多模态融合层耦合时,考虑到其高复杂度 ,计算对比损失的成本就会变得很大,其中L是视觉和文本token的总数。解决这一问题的一种方法是使用随机抽样 来选择一小部分负对。
在本文中,作者提出了一种级联采样方法,而不是随机抽样,如图右上方所示(在训练过程中有效地选择一小组非常negative的样本)。它利用了在多模态融合层之前在L1和L2中计算的视频文本对齐分数,更有效地学习多模态融合层,并且没有任何额外的开销。
3
方法
3.1. Framework
如上图所示,TACo的模型结构如上图所示,由三部分组成:
Video encoding module
视频编码模块 ,由一系列参数为 的Self-Attention层组成,在这里,输入的视频特征已经使用一些预训练的模型提取,如2D CNN(ResNet)或3D CNN(I3D,S3D)。
给定输入的视频embedding,视频编码器从一个线性层开始,将embedding投影到与自注意层相同的维度d上,一个视频特征就可以表示为 ,其中特征数m取决于采样帧率的选择和视频特征提取器。
Language encoding module
语言编码模块 ,作者使用预训练的tokenizer和BERT来将输入文本进行token化并提取特征。给定一个句子,首先分别在开头和结尾附加一个“[CLS]”和“[SEP]”。提取特征之后,可以获得一个长度为n的文本特征的序列 。
在这里,作者确保了视频编码器的输出特征维度与语言编码器的输出特征维度相同。在训练过程中,更新语言编码器中的参数 ,以适应特定域的文本。
Multi-modal fusion module
多模态融合模块 也是由具有可学习参数 的自注意层组成。它将视频特征
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2196
2196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









