






本文分享论文『Structured Two-stream Attention Network for Video Question Answering』,由电子科大(申恒涛团队)&京东AI(梅涛团队)提出用于视频问答的结构化双流注意网络,性能SOTA!优于基于双视频表示的方法!
详细信息如下:

论文链接:https://arxiv.org/abs/2206.01017
01
摘要
到目前为止,视觉问答(即图像问答和视频问答)仍然是视觉和语言理解的重要工作,尤其是视频问答。与图像QA主要关注于理解图像区域级细节与相应问题之间的关联相比,视频QA需要一个模型来共同推理视频的空间和长期时间结构以及文本,以提供准确的答案。
在本文中,作者专门解决了视频QA问题,提出了一个结构化双流注意力网络,即STA,以回答关于给定视频内容的自由形式或开放式的自然语言问题。首先,作者利用结构化片段组件推断出视频中丰富的长时间结构,并对文本特征进行编码。然后,本文的结构化双流注意分量同时定位重要的视觉实例,减少背景视频的影响,聚焦于相关的文本。最后,结构化双流融合组件融合了不同的查询片段和视频感知上下文表示,并推断出答案。
在大规模视频QA数据集TGIF-QA上的实验表明,本文提出的方法显著优于最佳对应方法(即视频输入有一个表示),对于 Action, Trans., TrameQA ,Count任务分别有13.0%、13.5%、11.0%和0.3的提升。TrameQA和Count任务。它在 Action, Trans., TrameQA 任务方面也优于最佳模型(即有两种表示)4.1%、4.7%和5.1%。
02
Motivation
最近,涉及视觉和语言的任务引起了人们极大的兴趣,包括Captioning和VQA任务。Captioning的任务是生成图像或视频的自然语言描述。另一方面,视觉问答(VQA)(即图像问答和视频问答)旨在为给定图像/视频的问题提供正确答案。它被认为是评估机器智能的重要图灵测试。VQA问题在各种应用中起着重要作用,包括人机交互,游客指导。然而,这是一项具有挑战性的任务,因为需要理解语言和视觉内容,以考虑必要的常识和语义知识,并最终进行推理以获得正确答案。
图像问答(Image QA)旨在正确回答有关图像的问题,最近取得了很大的进展。大多数现有的图像QA方法都使用注意力机制,可分为两种主要类型:视觉注意力和问题注意力。前者的注意力集中在最相关的区域,通过探索它们的关系来正确回答问题,这涉及到“where to look”。后者关注视觉信息问题中的特定词语,即“what words to listen to”。一些作品共同进行了视觉注意力和问题注意力。
相比之下,视频QA比图像QA更具挑战性,因为视频同时包含外观和运动信息。视频QA面临的主要挑战有三个方面:首先,需要考虑长时间的时间结构,而不丢失重要信息;其次,需要最小化视频背景的影响来定位相应的视频实例;第三,分段信息和文本信息需要很好地融合。因此,需要更复杂的视频理解技术来理解帧级视觉信息和视频过程中的时间连贯性。视频QA模型还需要对视频和文本的空间和长期时间结构进行推理,以推断出准确的答案。
视频QA也采用了注意力机制,包括时空注意力和共同记忆注意力。时间注意力学习视频中要关注的帧,这些帧被捕获为整个视频特征。在共同记忆注意力机制中,外观注意力模型从空间特征中提取有用信息,运动注意力模型从光流特征中提取有用线索。它将关注的空间和时间特征连接起来,以预测最终结果。
作者观察到,回答视频QA中的一些问题需要关注许多帧,这些帧同等重要(例如,人走了多少次?)。仅使用当前的注意机制,整个视频级特征可能会忽略重要的帧级信息。基于这一观察,作者引入了一种新的结构,即结构化片段,该结构将视频特征划分为N个片段,然后将每个片段作为共享注意模型的输入。因此,可以从多个片段中获得许多重要帧。为了更好地连接和融合来自视频片段和问题的信息,作者提出了一种结构化双流注意网络(STA)来学习高级表示。具体来说本文的模型有两个层次的解码器,其中第一阶段解码器利用结构化片段推断丰富的长距离时间结构,第二阶段编码器通过结构化双流注意同时定位动作实例并避免背景视频的影响。
本文的STA模型在大规模数据集TGIF-QA数据集上实现了最先进的性能。综上所述,本文的主要贡献包括:1)提出了一种新的架构,即结构化双流注意网络(STA),通过共同关注视频和文本的空间和长距离时间信息,为视频QA任务提供准确的答案。2) 结构化片段组件捕获了视频中丰富的长距离时间结构,而结构化双流注意组件可以同时定位动作实例并避免背景视频的影响。3) 实验结果表明,本文提出的方法在动作、Trans.和FrameQA方面明显优于现有的方法。值得注意的是,作者仅使用一种类型的视觉特征来表示视频。
03
方法
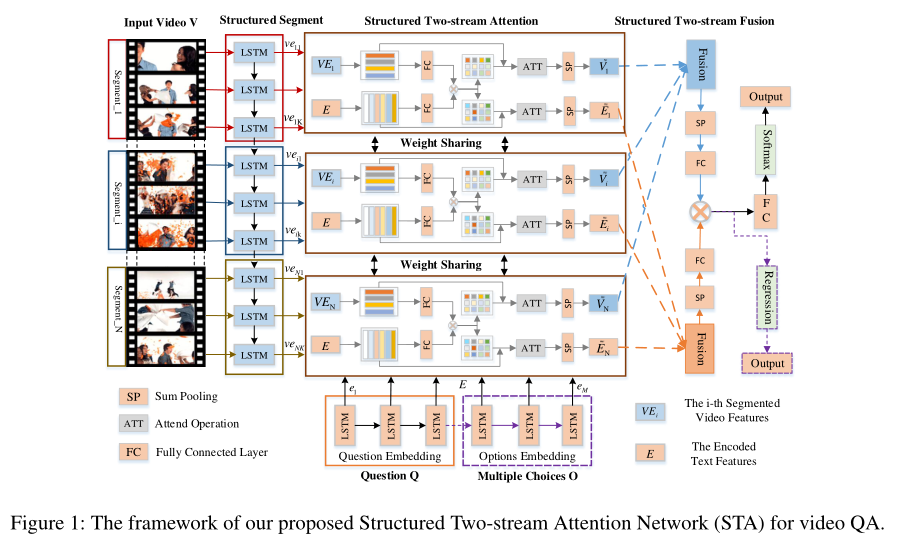
本文的目标是有效地提取视频的空间和长距离时间结构,然后改进视频和文本表示的融合,以提供准确的答案。主要挑战有三个方面:(1)在不丢失重要信息的情况下合并长程时间结构;(2)最小化视频背景的影响,定位相应的视频实例;(3)分段信息与文本信息的充分融合。
本文提出的框架如上图所示。形式上,输入是视频V、问题Q和一组答案选项O。此外,只有多项选择类型的问题需要输入O,如上图中紫色虚线框所示。具体地说,本文的框架由多个专注于获取视频的长期时间信息的结构化片段和一个反复融合语言和视频视觉特征的结构化的双流注意力组成,其上是一个基于结构化双流融合的答案预测模块,该模块融合多模态片段表示来预测答案。下面将详细介绍上述三个主要组成部分。
Structured Segment Video Feature Extraction
基于之前的工作,作者使用在ImageNet 2012分类数据集上预训练的Resnet-152来提取视频帧外观特征。对于每个视频帧,获得2048-D特征向量,该特征向量从pool5层提取,并表示该帧的全局信息。因此,输入视频可以表示为:
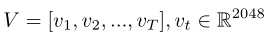
其中T是视频的长度。
对于序列数据流的编码,递归神经网络(RNN)得到了广泛而成功的应用,尤其是在机器翻译研究中。在本文中,作者使用长-短期记忆(LSTM)网络对视频特征进行进一步编码,以提取有用的线索。对于每一步,例如第t步,LSTM单元采用第t帧特征和之前的隐藏状态作为输入,输出第t个隐藏状态,其中尺寸D设置为512。
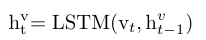
Structured Segment
之前的工作,如TGIF-QA,采用双层LSTM对视频特征进行编码,然后将双层LSTM的最后两个隐藏状态串联起来,以表示整个视频级别的信息。这会造成丢失重要框架级信息的风险。为了解决这个问题,作者引入了一种新的结构,即结构化片段,它首先利用一层LSTM获得T个隐藏状态(),然后将T个隐藏状态划分为N个段()。在此阶段之后,视频可以表示为,并且第i段表示为:
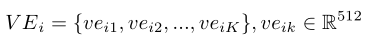
其中是第i段中第k帧的隐藏状态,K是每个段的隐藏状态总数。每个段的K值相同。
Text Encoder
对于视频QA任务,有两种类型的问题:开放式问题和多项选择题。对于第一种类型,本文的框架只将问题作为文本输入,而对于第二种类型,本文的框架将问题和答案选项都作为文本输入。最终文本特征表示为。
Question Encoding
一个由M个单词组成的问题首先被转换成一个序列,其中是表示位置m处单词的one-hot向量。接下来,作者使用在Common Crawl数据集上预训练的单词嵌入GloVe,对每个单词进行处理,以获得固定的单词向量。GloVe之后,第m个单词表示为。接下来,作者在单词嵌入的顶部使用一层LSTM来建模单词之间的时间交互。LSTM以嵌入向量作为输入,最后得到一个用于答案预测过程的问题特征E。因此,问题编码过程可以定义如下:
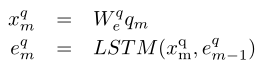
其中,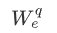 是嵌入矩阵。所有LSTM隐藏状态的维度设置为D=512。最后,在问题编码器之后,Q表示为
是嵌入矩阵。所有LSTM隐藏状态的维度设置为D=512。最后,在问题编码器之后,Q表示为
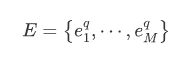
Multi-choice Encoding
对于多项选择任务,输入包括一个问题和一组答案候选。为了处理候选答案,按照上述问题编码过程将选项中的每个单词转换为one-hot向量,然后进一步将其嵌入GloV e。作者认为候选答案是对问题的补充。因此,本文框架的文本输入变为,其中O是答案候选特征,[,]表示concat操作。此外,单层LSTM单元将合并作为输入,以提取文本特征E。将此编码过程表述如下:
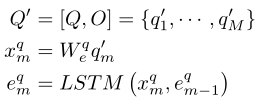
其中M是问题词的长度和所有候选词的长度之和。最后,在多选编码器之后,表示为。
Structured Two-stream Attention Module
结构化双流注意层(见上图),它连接和融合来自视频片段和文本的信息。该注意力层由N个双流(即文本和视频特征)注意力组成,所有注意力模型共享参数。对于第i个双流注意模型,它将第i个分段视频编码特征和文本特征作为输入,学习它们之间的交互,以更新和。这里用
402 Payment Required
和 表示第i个双流注意力的输入。与之前只是将视频帧特征与文本问题特征concat起来,形成一个新的答案预测特征的视频QA方法不同,本文的双流注意机制从两个方向计算注意力:从视频到问题以及从问题到视频。两个注意力得分都是根据共享affinity matrix 计算的,该矩阵由以下公式计算: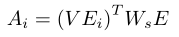
其中,是可学习的权重矩阵。为了便于计算,作者用两个单独的线性投影替换:
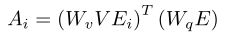
其中和是线性函数参数。本质上,对其两个输入和E之间的相似性进行编码。通过,可以计算注意力,然后关注两个方向上的两个流特征。
1st-stream: Visual Attention
视觉注意力向量表示video shot中要关注的帧或与每个问题词最相关的帧。给定,注意力向量由以下函数计算:
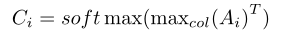
其中,表示上的按列最大操作。在逐列max操作之后,作者使用softmax操作对值进行归一化,以生成注意力向量。具体而言,。接下来,执行以下操作以获取attended之后视频特征:
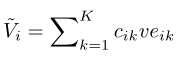
其中,包含整个问题的关注视觉向量。
2nd-stream: Text Attention
文本注意力向量表示关注哪个问题词。给定,作者用softmax对进行逐行标准化,得到每个视频帧条件下问题词的注意力图。形式上,注意力向量由以下函数计算:
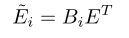
其中。通过生成的注意力图,作者利用它来关注问题词,以生成更具代表性的问题特征。形式上,由以下函数计算:
其中。最后,进行列式求和,以获得最终的。因此,生成的包含整个视频片段的关注问题词向量。
Structured Two-stream Fusion
在计算attended之后的特征表示和之后,其中和,首先分别对它们进行融合:
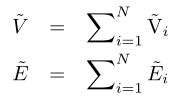
然后是sum pooling,将有人attened的视频向量和attended的问题向量汇集并组合在一起,以产生用于答案预测的H。
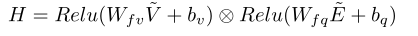
其中,和是参数;和是偏差项;是元素乘法,Relu是激活函数。
Answer Decoder Moduler
输出层(即答案解码器)是特定于应用程序的。本文的框架允许根据任务类型轻松地交换输出层,而结构的其余部分保持完全相同。基于之前的工作,作者处理了四项任务(即:Count,Action,State Trans.,和FrameQA)作为三种不同类型的解码器:多选、开放式数字和开放式单词。
Multiple Choice
对于TGIF-QA数据集,State Trans.和Action任务属于多项选择类别QA。为了解决这两项任务,作者对上述最终输出H应用线性回归函数,并得出每个答案选项的实值分数。
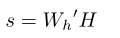
其中,是权重参数。作者将和分别定义为从正和负答案中得出的实值分数。为了训练模型,作者将对比较的hinge loss 最小化。
Open-ended Numbers
对于TGIF-QA数据集,计数任务需要一个模型来计算动作的重复次数,答案从0到10不等。对于这项任务,作者定义了一个线性回归函数,该函数将预测输出H作为输入,并生成一个从0到10的整数值答案。输出分数定义为:
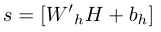
其中[.]表示舍入,为模型参数,为偏差。为了训练模型,作者采用了实际值和预测值之间的均方误差(MSE)损失。
Open-ended Words
与图像QA的任务类似,作者将视频FrameQA视为一个多类分类问题,其中每个类对应一个不同的答案(即,一个字典单词、一种对象、颜色、数字或位置)。对于视频QA,作者使用softmax分类器来推断最终答案。概率最高的选项被视为最终答案。此输出定义为:
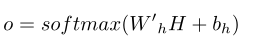
其中,是权重参数,是偏差。通过最小化交叉熵损失对模型进行优化。
在本文中,模型处理四项任务。对于每个任务,分别使用上述相应的答案解码器和损失函数对每个模型进行训练。最后,对每个模型分别进行评估。
04
实验
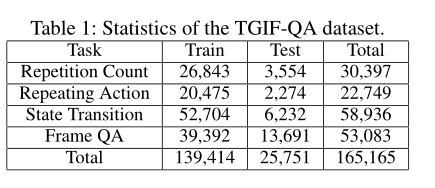
上表展示了本文使用的TGIF-QA数据集的统计信息。
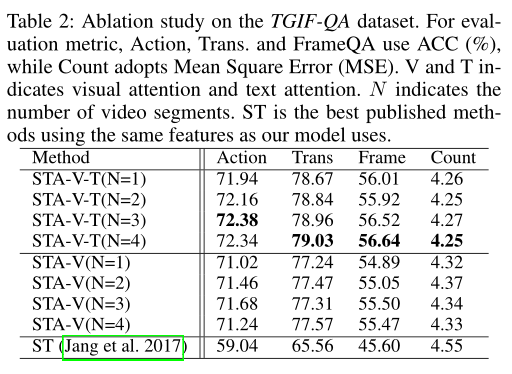
上表的第一块表示了N的影响,N是结构化段的数量。从第一个模块中,可以发现N=4在一定程度上提高了所有四个任务的性能。一个可能的原因是,将视频分割为多个片段以进行注意力有可能定位最相关的帧,从而学习长距离结构。然而,随着N的增加,性能的改善很小,原因可能是GIF视频的性质,这些视频分割良好,精心策划,平均长度为47帧。因此,结构化分割的优势没有得到充分利用。
此外,从表中可以看出,在相同的N设置下,STA-V-T的性能优于STA-V。这项消融研究显示了本文的文本注意力的有益效果。

为了理解本文的注意力机制的效果,作者在上图中展示了一些例子。第一行展示了三个正面的例子,其中两个模型可以提供正确答案。第二行显示了其他示例。更具体地说,第一个和第三个例子表明,STA-V-T正确回答了问题,而STA-V失败了。中间的例子表明,有时STA-V可以提供正确的答案。
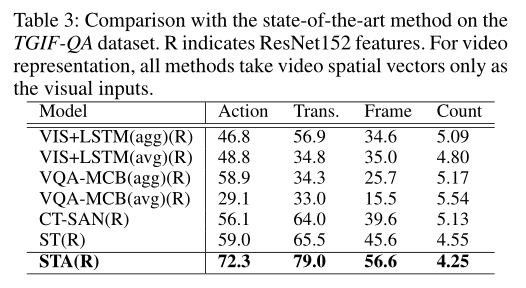
本文的方法STA利用单一特征来表示视频。因此,在本节中,作者首先将本文的方法与现有方法进行比较,现有方法仅将ResNet152帧特征作为视觉输入来进行答案预测。实验结果如上表所示,可以看出,本文的方法比SOTA的ST(R)在Action、Trans和FrameQA上分别高出13.3%、13.5%和11.0%。对于Count,STA将错误分数减少到4.25。
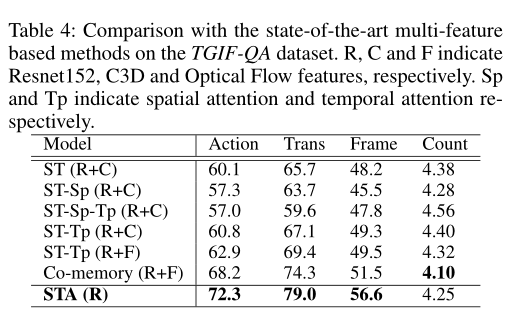
此外,作者将本文的方法STA与基于多特征的方法进行了比较,结果如上表所示。从这些结果可以看出,Co-memory(R+F)优于ST的所有变体,并且在计数任务上取得了最好的性能。与Co-memory(R+F)相比,本文的STA模型仅将ResNet152特征作为输入。
对于Action,Trans. 和FrameQA任务,它的性能显著优于Comemory(R+F),并且产生的最佳性能分别达到72.3%、79.0%和56.6%。即使在计数任务中,本文的STA也取得了第二好的可比结果。
05
总结
在这项工作中,作者提出了一种用于视频问答的新型结构化双流注意网络(STA)。作者首先利用结构化片段组件推断视频中丰富的长程时间结构,并将问题编码为特征。然后,作者利用双流注意力机制来同时定位与问题相关的视觉实例,避免背景视频或无关文本的影响,而不是简单地将视频和问题特征concat起来回答问题。最后,结构化双流融合组件结合了查询和视频感知上下文表示的不同部分,并推断出不同类型问题的答案。在TGIFQA数据集的综合评估表明,本文的STA模型显著优于现有方法。
参考资料
[1]https://arxiv.org/abs/2206.01017

END
加入「视频问答」交流群👇备注:VQA
















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









