






关注公众号,发现CV技术之美
本篇分享 CVPR 2025 论文,俞益洲教授团队提出新型语义分割框架SegMAN,在三大语义分割基准(ADE20K,Cityscapes, COCO-Stuff-164k)测试中展现出了卓越的性能。代码已开源!

论文连接:https://arxiv.org/pdf/2412.11890(预印版)
代码连接:https://github.com/yunxiangfu2001/SegMAN
摘要
香港大学计算和数据科学学院俞益洲教授(https://i.cs.hku.hk/~yzyu/index.html)及其研究团队提出新型语义分割框架SegMAN,包含全球首个融合动态状态空间模型(Mamba)与局部自注意力的通用视觉主干网络(SegMAN Encoder)及基于Mamba的多尺度解码器(SegMAN Decoder)。
主干网络创新
SegMAN Encoder首次在视觉主干网络中实现Mamba全局建模能力与局部自注意力机制的融合,该模型通过线性复杂度Mamba捕获长程依赖和滑动窗口局部自注意力保持像素级细节精度,在ImageNet-1k 上显著超越现有的Mamba与Transformer 模型。
解码器创新
SegMAN Decoder核心为基于Mamba的多尺度信息增强模块(MMSCopE),该模块采用卷积来提取多分辨率区域的语义信息,然后通过空间扫描机制实现跨尺度的全局语义传播。
整体架构
结合了主干网络与解码器,提出一种新的语义分割模型SegMAN,在三大语义分割基准(ADE20K,Cityscapes, COCO-Stuff-164k)测试中展现出了卓越的性能。
动机
在计算机视觉领域,语义分割任务要求为图像中的每个像素赋予类别标签,是自动驾驶、医学影像分析、智能安防等应用的核心技术。然而,这一任务面临三大关键挑战:全局上下文建模(理解整体场景)、局部细节编码(精确识别边界与细微特征)以及多尺度特征提取(适应不同尺寸的目标)。
现有方法往往顾此失彼---全局建模能力强的模型可能丢失细节,而关注细节的模型又难以覆盖全局。针对这一瓶颈, SegMAN创新性地构建了编码-解码协同框架,高效的整合全局上下文建模、局部细节表征与多尺度动态融合三大核心机制。
方法
SegMAN Encoder构建了4阶段金字塔结构,创新性地将邻域注意力(Natten)与二维选择性动态状态空间模型扫描(SS2D)融合为一个即插即用的LASS混合模块。该模块通过级联式架构实现:Natten采用滑动窗口机制捕捉不同邻域内的细粒度特征,SS2D通过四向扫描路径建模全局长程依赖,二者通过残差连接实现局部-全局特征的动态融合。LASS模块突破传统Transformer的二次方复杂度限制,通过Natten的局部窗口约束与SS2D的状态空间压缩策略,在保持线性计算复杂度的同时,实现多尺度特征的协同优化。
SegMAN Decoder设计基于状态空间模型的MMSCopE模块,该模块可以无缝插入到任何金字塔网络,并且通过像素重组技术将原始特征()、 降采样特征()和 降采样特征()沿通道维度拼接提取多分辨率区域的语义信息,随后利用SS2D的单次空间扫描机制实现跨尺度的全局语义传播,然后将多尺度特征注入编码器各阶段输出(),最终经双层MLP生成像素级预测。
SegMAN通过编码-解码协同优化,在全局建模、局部感知与多尺度融合三个关键维度实现突破,为实时高精度语义分割任务提供了新的技术路径。 SegMAN的整体架构如图1所示:
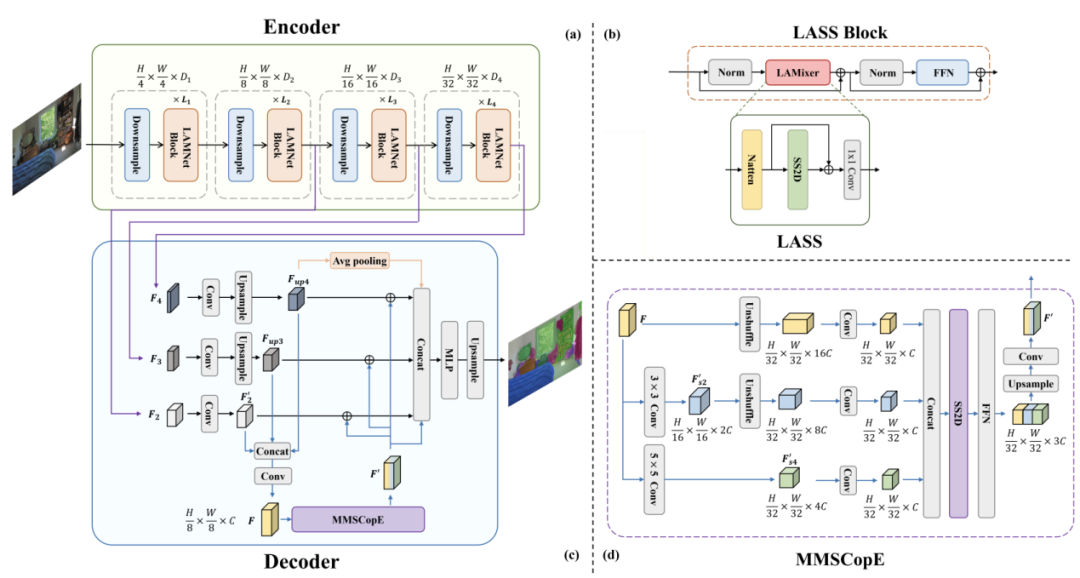
实验结果
图像分类性能
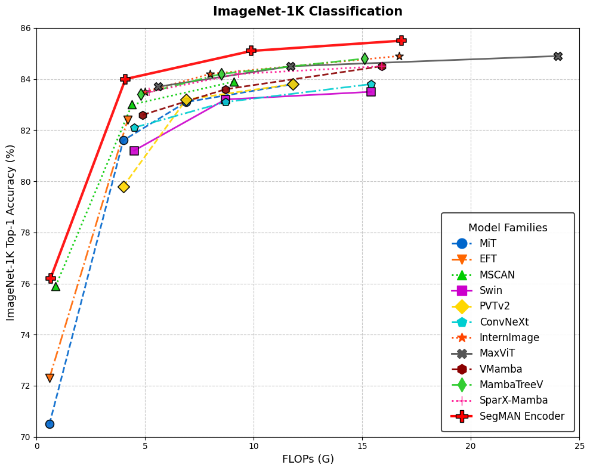
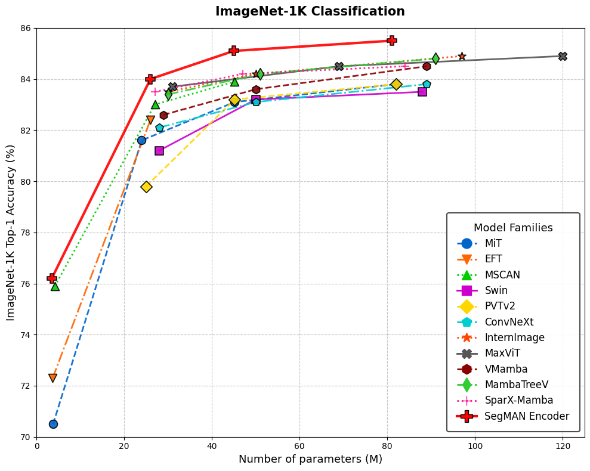
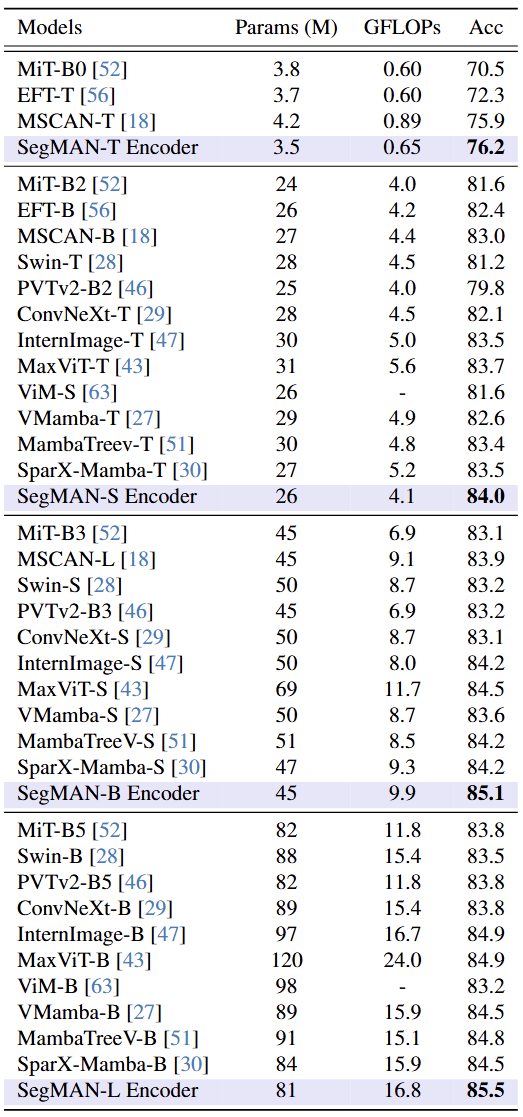
SegMAN Encoder在图像分类基准数据集 ImageNet-1K 上表现出了卓越的性能,相较于现有方法,在公平比较里展现出更高的准确率。如图2和表1所示,SegMAN Encoder 在不同尺寸的模型上都具有更高的准确率。SegMAN-B Encoder(45M)以大约一半的参数量就超越了VMamba-B, ConvNeXt-B, InterImage-B等模型的准确率。
语义分割性能
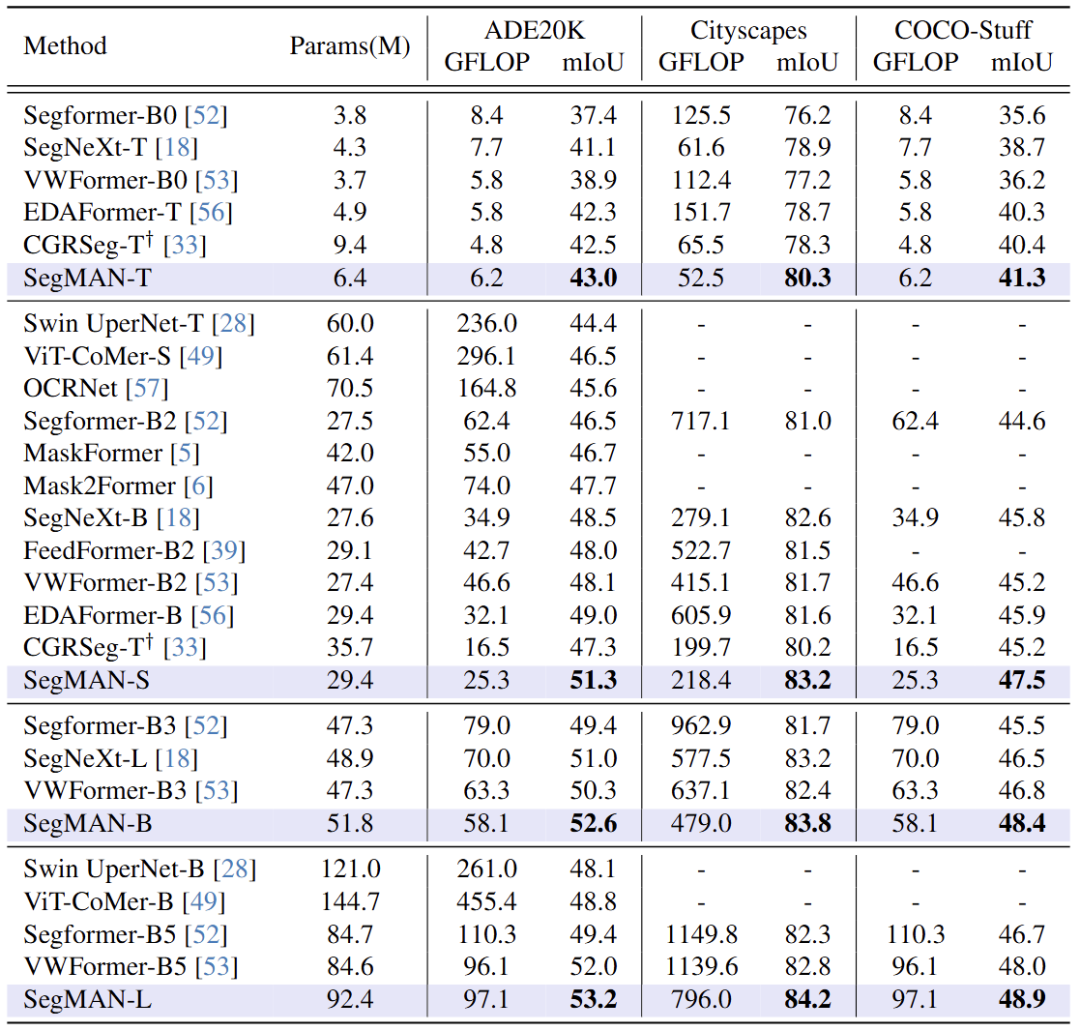
计算效率
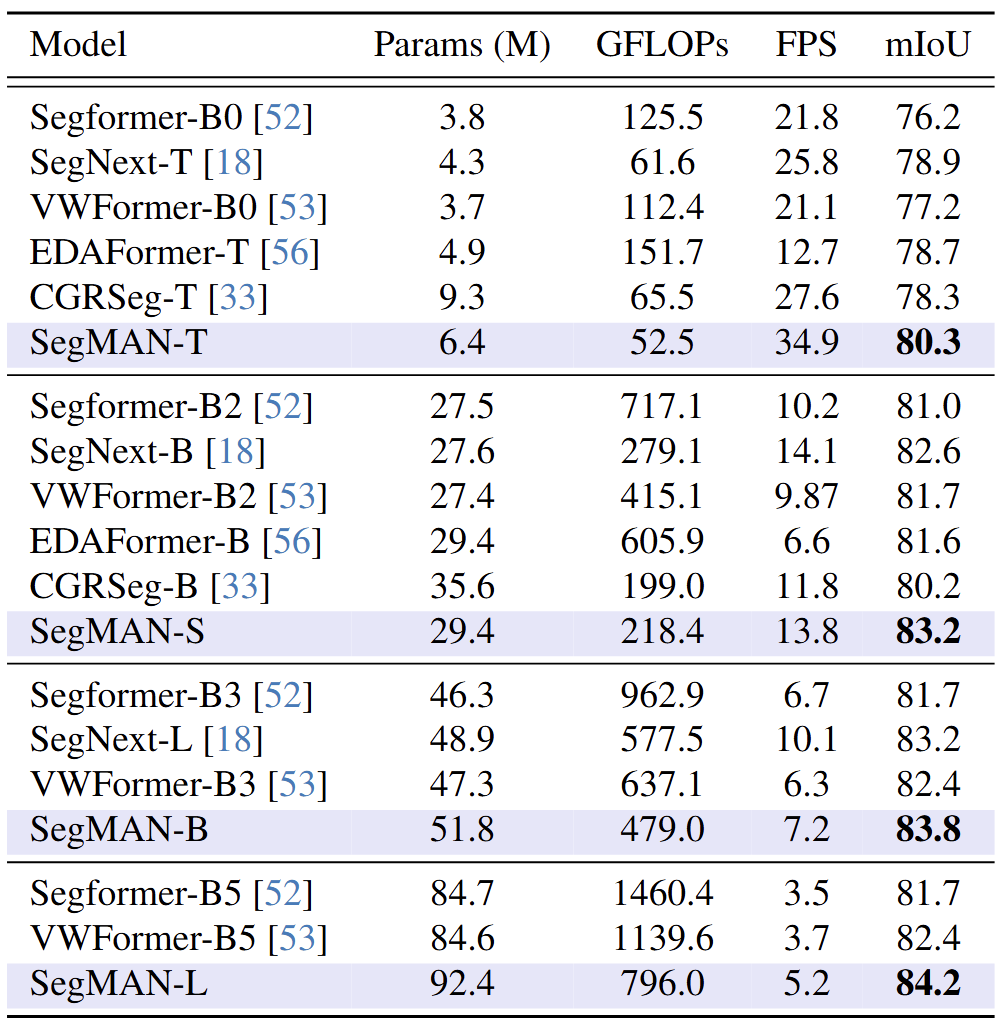
在Cityscapes数据集(2048×1024分辨率)的推理速度测试中,使用NVIDIA L40S GPU并以批次大小2运行128个步骤,SegMAN-T的平均帧率(FPS)显著优于对比模型。如表3所示,SegMAN-T在FPS约为EDAFormer-T三倍的同时,mIoU指标提升1.6%,体现了模型在计算效率与语义分割性能之间的优越tradeoff。
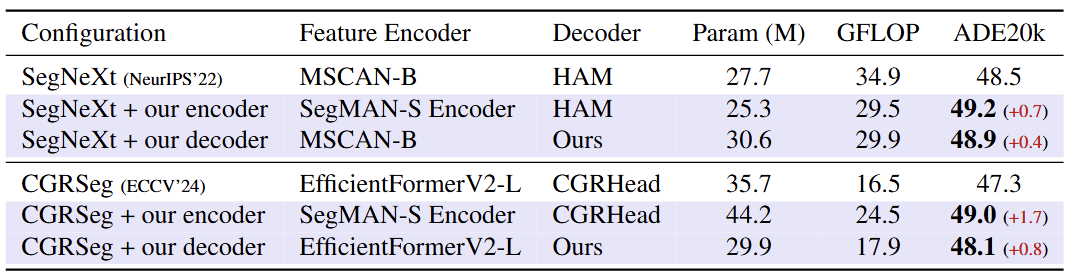
通用性实验
如表4所示,当将SegMAN Encoder与Decoder模块集成到现有最新方法中时,二者均能有效提升模型性能。
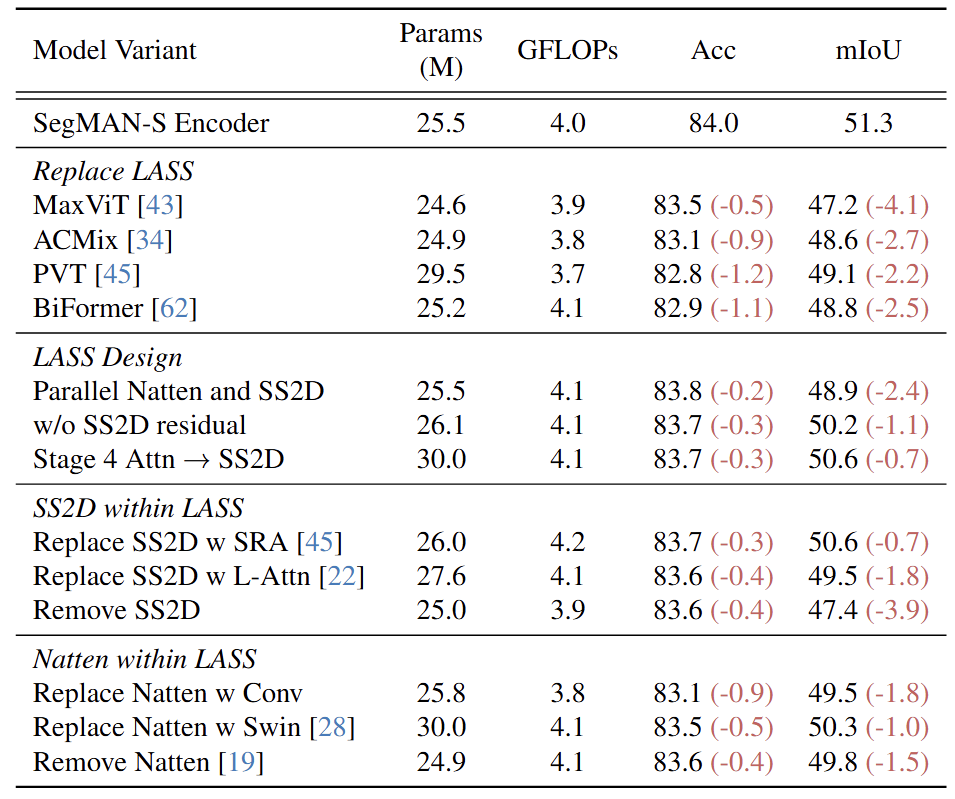
消融实验
研究团队在ImageNet-1K与ADE20K数据集上系统性验证编码器架构设计。核心模块LASS采用Natten与SS2D的级联结构,通过SS2D残差连接实现局部-全局特征融合,并在第四阶段以全局注意力替代SS2D以增强高层语义建模。架构验证通过三组消融实验展开:
混合器架构对比:将LASS替换为MaxViT、ACMix等主流结构时,LASS在分类与分割任务中均表现出最优性能。其优势源于Natten对局部细节的精准捕捉与SS2D对全局关联的高效建模形成的双向互补效应。
组件连接方式分析:实验表明,SS2D与Natten的级联结构配合残差连接具备必要性。若改用并行架构或移除残差连接,分类准确率与分割mIoU分别下降0.9%和1.8%。
核心算子有效性:替换SS2D为空间缩减注意力(SRA)或线性注意力时,性能出现0.3%-1.8%的显著下滑;将Natten替换为卷积或移位窗口注意力则导致0.5%-1.8%的精度损失,验证原始组件组合的不可替代性。
详细数据支持如表5所示。
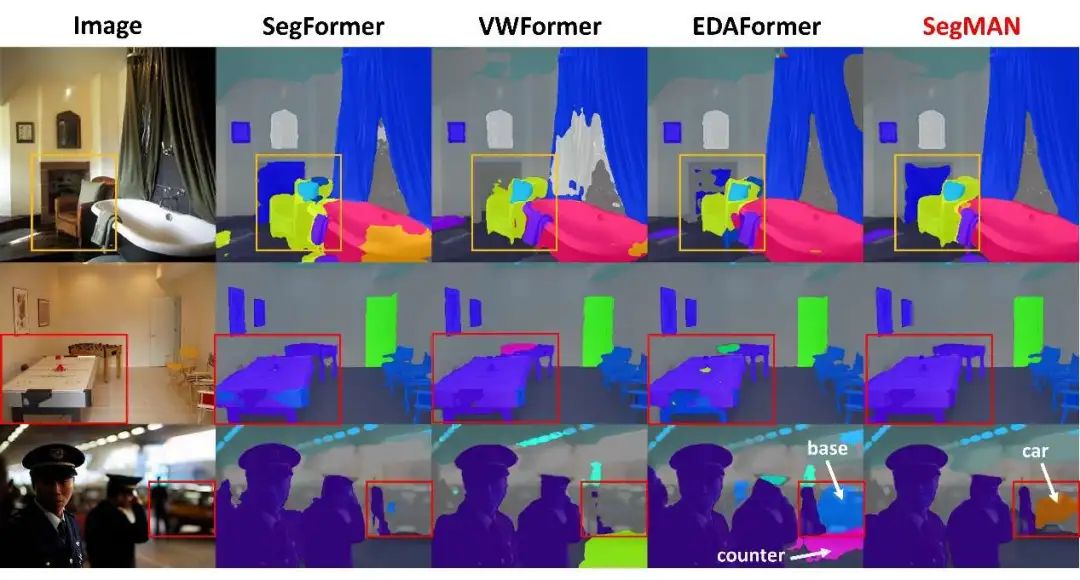
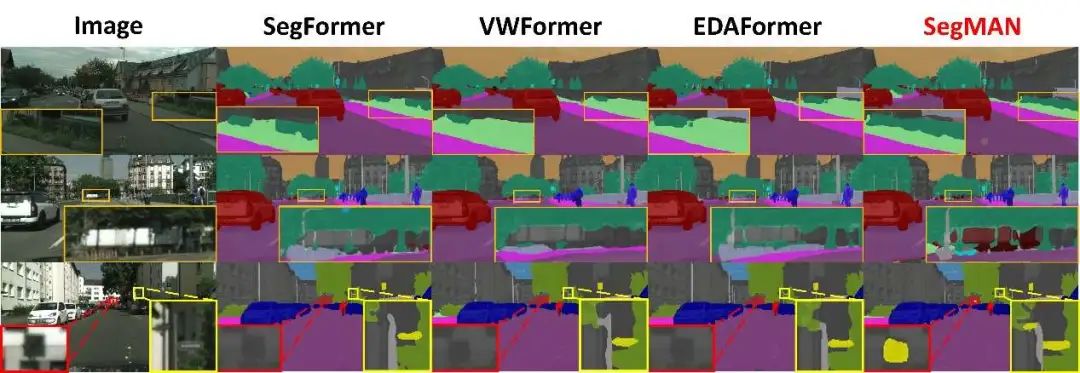
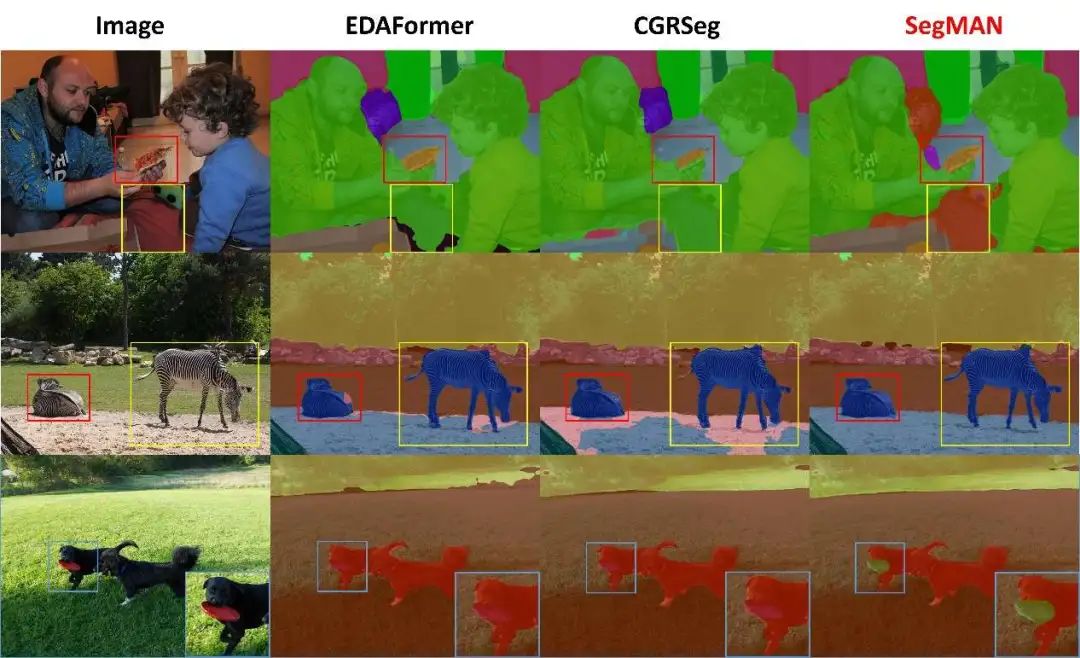
可视化
图3、4、5分别对比了ADE20K、Cityscapes及COCO-Stuff-164K数据集上不同方法的分割效果。如图所示,相较于现有方法,SegMAN生成的分割边界更精准,且能细致捕捉场景中的复杂细节(如微小物体等),在结果完整性与真实感上实现显著提升。
最新 AI 进展报道
请联系:amos@52cv.net

END
欢迎加入「语义分割」交流群👇备注:seg


















 3231
3231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









