









博客内容将首发在微信公众号"跟我一起读论文啦啦",上面会定期分享机器学习、深度学习、数据挖掘、自然语言处理等高质量论文,欢迎关注!
本次总结和分享一篇大佬推荐看的论文improving multi-task deep neural networks via knowledge distillation for natural language understanding, 论文链接MT-DNN-KD
动机和创新点
- 集成学习的方法对提高模型的泛化能力在众多自然语言理解任务上已经得到了验证
- 但是想集成多个深度神经网络模型非常困难,时间上非常耗时,线上部署困难,计算资源上要求巨大,很难应用到线上,如果想集成多个不同版本的BERT这种非常复杂的模型,更是非常困难。
- 知识蒸馏(knowledge distillation)是有hinton在2015提出,可以在保证模型在表现效果上不降低或者很小降低的前提下,将一个集成的,复杂的,笨重的模型转换成一个轻量级,易应用的模型,使其适合在线上部署。
- 论文中将知识蒸馏(knowledge distillation)应用到multi—task场景中,对于每个任务,将训练好的集成模型的结果(对于分类任务就是各类上的一个分布)作为一个soft-target,用来辅助单一的简单模型的训练学习,学习好的简单模型具有线上预测耗时短,易部署,泛化能力强的效果。 非常适用线上部署。
- 在multi-task中的shared-layer使用预训练好的bert参数
MT-DNN

其中上图中的shared layers就是BERT中的pretrain部分,一模一样,不多做说明。论文中是用别人已经预训练好的bert模型来初始化shared layers的参数。
Task-Specific Output Layers: 针对不同的任务,做不同的处理,例如分类任务:
p
r
(
x
∣
X
)
=
s
o
f
t
m
a
x
(
W
t
∗
x
)
p_r(x|X)=softmax(W_t*x)
pr(x∣X)=softmax(Wt∗x)
上式中的
W
t
W_t
Wt就是不同任务输出层的参数矩阵。注意刚开始时任务输出层的参数是随机初始化的,也就是各个任务的
W
t
W_t
Wt随机初始化。
对于这一部分,我的理解是,相当于不同的任务,在bert上放置多个不同形状的softmax层,使其可以同时适用于不同的任务。
对于分类任务,其损失函数为常见的cross-entropy:
−
∑
c
1
(
X
,
c
)
l
o
g
(
p
r
(
c
∣
x
)
)
-\sum_c1(X,c)log(p_r(c|x))
−c∑1(X,c)log(pr(c∣x))
上式中的
1
(
X
,
c
)
1(X,c)
1(X,c) 表示二分类的指示器,如果预测出的类别是c则为1,反之为0。

对于每个任务的算法过程如上图所示。
- 注意 D 1 , D 2 , D 3 , . . . , D T D_1,D_2,D_3, ...,D_T D1,D2,D3,...,DT 表示不同任务的数据集
- 在3,4,5步骤中,不同的任务以不同的目标函数,但是都以SGD训练,其中更新的参数包括shared layers和对应任务的output layer参数。
论文中说,利用多个不同任务的带标签样本,使用这种多任务学习的方式fine-tune MT-DNN,使其可以应用到任何任务上,其shared layers所学习到text-representation比起bert更universal。
记以上面这种模型叫MT-DNN(multi-task deep neural net)。
Knowledge Distillation
上面讲的是,对不同的任务训练出不同的单一模型,虽然bert模型已经很复杂了,但是对于每个任务,如果能训练一堆不同版本的bert(超参数不同的),其得出的集成结果(回归取平均,分类取最多的等)肯定更好,但是对于如此复杂的集成模型,如何在线上使用变的非常困难,这时我们可以用知识蒸馏方法。
拿分类任务来说,我们以MT-DNN训练一系列不同的分类模型作为集成模型(teacher),在对于某个样本,我们可以得到这些模型将样本预测为c类的概率,然后取平均,如下:
Q
=
a
v
g
(
[
Q
1
,
Q
2
,
Q
3
,
.
.
,
Q
K
]
)
Q=avg([Q^1 ,Q^2,Q^3,..,Q^K])
Q=avg([Q1,Q2,Q3,..,QK])
其中
Q
K
Q^K
QK 表示第k个模型将样本预测为c类的概率。
那么在对分类任务,训练一个简单模型(student)时,修改其损失函数为:
−
∑
c
Q
(
c
∣
X
)
l
o
g
(
p
r
(
c
∣
x
)
)
-\sum_cQ(c|X)log(p_r(c|x))
−c∑Q(c∣X)log(pr(c∣x))
这里的 Q ( c ∣ X ) Q(c|X) Q(c∣X) 表示多个模型将样本 X X X预测为 c c c 类的平均概率。这么做的目的就是希望我们的简单模型能学习到集成模型(teacher)的概率分布(soft-target)。
这样简单模型(student)就能结合hard correct target(正确label c)和soft-target去训练学习。
简单模型利用soft-target是提高其泛化能力的一个关键。 我们希望利用sotf-target能使得一个简单、易部署的模型能达到集成模型的泛化能力。
记上面这种经过集成模型(teacher)的teach的Student模型为 MT-DNN-KD
实验分析
论文中举了9个不同的自然语言理解任务。但是只在 M N L I , Q Q P , R T E , Q N L I MNLI, QQP, RTE, QNLI MNLI,QQP,RTE,QNLI 四个任务上训练了集成模型,其中每个集成模型室友表现最好的3个不同版本(dropout参数不同等)的bert组成。其他五个任务并没有集成模型(teacher)。
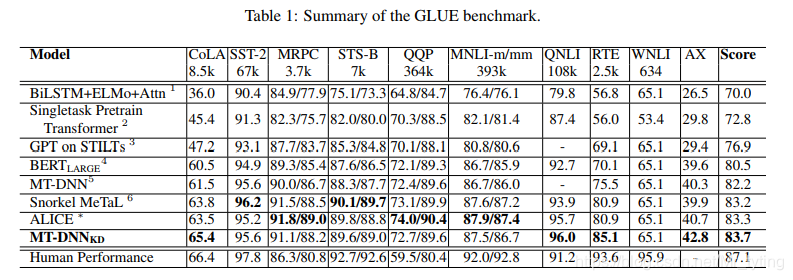
可以看出MT-DNN-KD在平均Score上表现最好,并且几乎在每一个任务上表现大幅领先原始的MT-DNN。
值得注意的是,在一些没有teacher模型的任务上,MT-DNN-KD的表现也超越了原始的MT-DNN模型,我们认为,知识蒸馏方法起到了关键的作用。

上图中MT-DNN-enemble表示集成模型,MT-DNN-KD表示经过集成模型teach的简单模型,我们可以看出在多数任务上,MT-DNN-KD表现大幅超越原始的MT-DNN,并且接近MT-DNN-enemble,这就说明我们的做法是有效的。
总结
- 针对不同的任务,仍需训练多个不同的模型作为集成模型,其结果作为soft-target来teach简单模型训练学习,在线上时,只需用这个简单模型即可达到或者接近集成模型的效果,达到耗时短,易部署,泛化能力强的效果。
- 本论文理论创新不是很足,其关键部分均是前人已有的成果,只是拿到multi-task这个场景中使用,并且效果还行。














 1753
1753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









