









博客内容将首发在微信公众号"跟我一起读论文啦啦",上面会定期分享机器学习、深度学习、数据挖掘、自然语言处理等高质量论文,欢迎关注!

本次要总结和分享的论文是GPT2,参考的实现代码model。本论文方法是在openAI-GPT的基础上进行了一些微小的修改得到的,从模型的角度来讲,只是大幅增大了模型规模,去掉了fine-tune过程,无论是在预训练和预测阶段都是完全的无监督,这点就很不可思议,但是的确做到了,而且效果还不错。网上对这篇论文的讲解非常多,这里本人就讲下自己浅薄的见解。
动机和创新点
- 传统机器学习任务只是拿某一特定领域内的数据,做有监督的训练,这样训练得到的模型对数据分布比较敏感,泛化能力较弱。
- 多任务学习是一种可以提高模型泛化能力的途径,但是在NLP领域内,多任务学习还是处于比较初期的阶段。当前的机器学习方法可以通过学习大量的样本来提高模型的泛化能力,由此多任务学习同样可以通过海量的数据样本来提高泛化能力,但是这是不可持续的,因为很难继续扩大数据集的创建和目标的设计,以达到使用现有技术(with current techniques)来强制我们的方式(brute force our way there)所需的程度(the degree that may be required)。
- 在当前NLP领域内,比较流行 (无监督的pre_train + 有监督的fine-tune) 的方法。在下游任务中,该方法仍然需要做有监督的fine-tune。
- 本论文中提出了去掉有监督的 fine-tune阶段,仅仅用预训练后的语言模型,直接将其应用到下游任务中(模型参数不做任何变化),论文中展示和强调了语言模型的潜力,并且在多个NLP任务中取得了较好的效果。
- 与GPT论文中的模型相比,GPT2模型几乎没有变化,但是模型的参数达到了15亿,模型预训练使用的样本类型更加多样化,更加干净,也更大,达到40G。
- 总而言之,读这篇论文要有想象力,要记住没有fine-tune过程!!!至于这种完全的无监督如何应用到摘要生成,机器翻译等NLG任务上,处理技巧上更需要想象力。
Approach
标准的语言模型:
p
(
x
)
=
∏
i
=
1
n
p
(
s
n
∣
s
1
,
s
2
,
.
.
.
,
s
n
−
1
)
p(x) = \prod_{i=1}^n p(s_n| s_1,s_2,...,s_{n-1})
p(x)=i=1∏np(sn∣s1,s2,...,sn−1)
对于单一任务的语言模型:
p
(
o
u
t
p
u
t
∣
i
n
p
u
t
)
p(output|input)
p(output∣input)
因为我们希望一个足够泛化的模型应该可以在多个不同任务上能表现良好,甚至对于相同的输入,针对不同的任务能得到不同的输出,也即是:
p
(
o
u
t
p
u
t
∣
i
n
p
u
t
,
t
a
s
k
)
p(output|input, task)
p(output∣input,task)
实际上,有监督学习的目标和无监督学习的目标是一致的,只不过有监督仅在序列的子集(而无监督是要生成整个序列)上进行评估,因此无监督目标的全局最小值也是有监督目标的全局最小值。论文中讲到,初步的实验证明,只要语言模型足够大,是可以进行多任务学习的,但是学习速度比有监督可要慢得多。
训练数据
在这部分,论文讲了一大堆数据的重要性,例如数据量、数据多样性、数据质量等等对模型的影响。而本论文旨在尽可能地构建和利用足够大且多样化的数据集,以便模型能应用到尽可能多的不同NLP任务上。
因为本论文所提方法是完全无监督的,所以不需要特别的去收集带标签的数据,可以直接在互联网中采集数据。论文中是这样采集的:
- 使用 Reddit 上 >3 karma 的外链作为数据源,WebText,这样自动的保证了数据质量,因为Reddit 数据五花八门,来自各个领域,所以认为这样可以做多任务学习。
- 从所收集到得WebText中去除了 wiki 数据,因为wiki数据是许多数据的来源,可能会使得训练集和测试集出现重复,导致有作弊嫌疑。
最终收集到的数据大小有40G,模型将在这40G的数据集上进行预训练。
模型输入
在数据预处理上,论文并没有对句子做分词处理,而是采用字节粒度上的BPE方式,自动的对所有的字节按照其出现的频率进行贪心方式的合并,从而达到了自动的分词效果,并且阻止BPE跨任何字节序列的字符类别的合并,防止避免得到类似于’dog.’、‘dog!’、‘dog?.’ 的词,从而提高了词表空间使用效率。
模型
几乎与GPT1中的模型完全一样,只不过在加了两层layer-normalization,分别放在模型输入后和最后一个self-attention block后。 使用了修改的初始化方案,该方案考虑了具有模型深度的残差路径上的累积。 我们在初始化时将残差层的权重缩放
1
/
n
1/\sqrt{n}
1/n倍,其中N是残差层的数量。 词表大小扩大到50,257。 我们还将上下文大小从512个token增加到1024,并使用更大的batch_size=512。
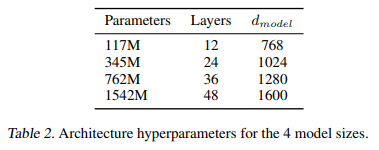
上图中最小的模型,12层的transform block,即最原始的GPT模型
24层的transform block,即BERT模型
48层的transform block,即是论文中GPT2模型,可见GPT2模型在容量上,预训练数据量上都大幅超越以往的模型。
实验分析
一定要注意,无论在任何任务,任何数据集上,论文中的GPT2都是直接进行无监督的预测或生成!!!,没有fine-tune!!!
这里挑几个有意思的任务说下。
阅读理解
- 数据集:采用CoQA问答数据集,直接进行无监督的生成
- 模型输入:document, history of the associated conversation + A
- 解码方式:采用贪心的解码方式,就是每次选择概率最大的词作为生成词。
- 实验结果:在验证集上达到55 F1,超过了3个baseline的结果,但是距离bert的89 F1还是相差较大,考虑到bert在CoQA上进行了有监督的fine-tune,而我们的GPT2则是完全的无监督,这样的效果已经很令人震惊了。
摘要生成
- 数据集:CNN 和 Daily Mail dataset,直接进行无监督的生成
- 模型输入:article + TL;DR ( TL;DR用来引导模型生成摘要)
- 解码方式:每一步解码时,都是从概率最高的top k(论文中选择k=2)中随机抽样,作为当前步生成的token,并且限制生成100个tokens,然后从这100个tokens中选择前三句作为生成的摘要。相对于贪心的解码方式,这种解码能较好地避免生成重复词和能生成更加抽象的摘要。
- 实验结果:
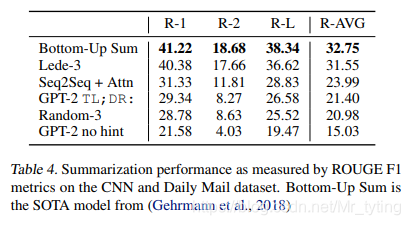
其中Bottom-up Sum是当前在该任务上表现最好的模型,Random-3表示从文章中随机抽三句话作为摘要。由此可以看出GPT2 TL;DR:表现只是比Random-3稍微好一些而言,当把GPT2输入引导TL;DR:去掉以后,各项指标大概降低了6个百分点左右。
机器翻译
- 数据集:WMT-14 EngLish-French 和 WMT-14 French-EngLish,预训练后的模型直接翻译!!
- 模型输入:要翻译的英文句子假设为en2,为了引导模型能翻译出法语,找了一英法句子对 (en1, fr1),将模型输入定为 “en1=fr1 + en2 =”,这样做的目的是希望能学习到输入的类比关系,从而引导模型生成fr2。同样,也有法语到英语的翻译输入。
- 解码方式:贪心的解码方式,以生成的第一句话作为翻译结果。
- 实验结果:在英法翻译的效果上,模型获得了5 BLEU,比双语词典的逐字替换稍差一点。在法硬翻译中,获得了 11.5 BLEU,好于当前一些无监督翻译的baseline模型,但是还是要远差与当前最好无监督模型的33.5 BLEU。尽管如此还是令人震惊,因为模型模型没有看到过法语,却能生成法语!!!!尽管训练集中存在区区10MB法语数据!!! 比先前无监督机器翻译研究中常见的单语法语语料库小约500倍。
个人总结
- 读完后的感觉是不可思议,竟然可以这样完全无监督的做生成任务,看来语言模型的潜力很大。
- 大力出奇迹,语言模型的深度达到48层,预训练数据集达到40G。
- 如果用如此规模的模型在下游任务中做有监督的fine-tune,效果是否会更好?所以等到GPT3的出现?
- 感觉这没点计算资源,都没办法做实验,对硬件的要求越来越高。














 1461
1461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









