







Transformer 于 2017 年问世。已经有很多文章解释了它的工作原理,但我经常发现它们要么过于深入数学,要么过于浅显。
我花在谷歌搜索(或 chatGPT)上的时间和阅读的时间一样多,这不是理解一个主题的最佳方法。这让我写了这篇文章,我试图解释 Transformer 最具革命性的方面,同时保持简洁明了,任何人都可以阅读。
本文假设您对机器学习原理有一般性的了解。

Transformer 背后的理念引领我们进入生成式人工智能时代
Transformers 代表了序列传导模型的一种新架构。序列模型是一种将输入序列转换为输出序列的模型。该输入序列可以是各种数据类型,例如字符、单词、标记、字节、数字、音素(语音识别),也可以是多模态¹。
在 Transformer 出现之前,序列模型主要基于循环神经网络 (RNN)、长短期记忆 (LSTM)、门控循环单元 (GRU) 和卷积神经网络 (CNN)。它们通常包含某种形式的注意力机制,用于解释序列中各个位置的项目所提供的上下文。
先前模型的缺点
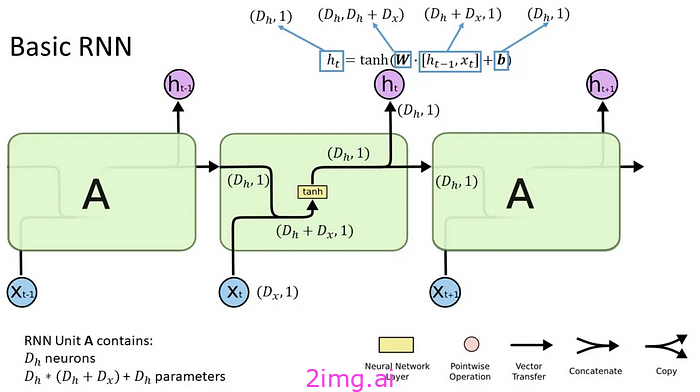
- RNN :该模型按顺序处理数据,因此从上一次计算中学习到的任何内容都会在下一次计算中得到考虑²。然而,其顺序性会导致一些问题:该模型难以解释较长序列的长期依赖性(称为消失或爆炸梯度),并且阻止输入序列的并行处理,因为您无法同时对输入的不同块进行训练(批处理),因为您会丢失先前块的上下文。这使得训练的计算成本更高。
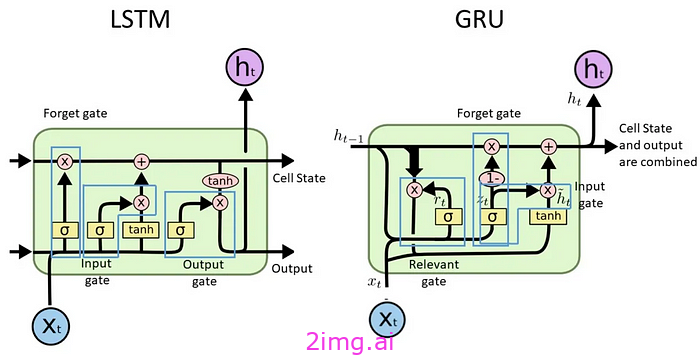
- LSTM 和 GRU:利用门控机制</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 947
947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











