






语义分割是计算机视觉中的一项核心任务,随着大规模视觉语言模型(VLM),如 CLIP 的出现,这项技术取得了显著进展。通过整合语言模型,特别是使用 CLIP 进行预训练,可以显著提升语义分割的性能。CLIP 的主要优势在于,它能够在包含丰富视觉和文本内容的多样化数据集上进行训练,从而实现对视觉内容的上下文敏感理解。
在语义分割中,基于 CLIP 的训练方法正在重新定义性能基准,特别凸显了跨模态嵌入的优势。通常的做法是通过像素-文本对齐,将每个像素特征与其对应的地面真实类标签的文本嵌入对齐。然而,这种方法也面临一些挑战。由于计算资源的限制,像素-文本对齐通常在低分辨率的图像特征上进行。此外,CLIP 生成的文本嵌入基于图像-文本匹配,通常包含全局图像级语义信息。当这些文本嵌入与详细的局部像素特征对齐时,可能会出现不匹配问题。
为了应对这些挑战,我们总结了四种新的语言引导的语义分割框架,这些框架有效地解决了像素-文本对齐带来的问题。
论文1 Probabilistic Prompt Learning for Dense Prediction
方法:
本文提出了一种新颖的概率提示学习方法,以在密集预测任务中充分利用视觉语言知识。首先,我们引入了可学习的类无关属性提示,以描述对象类的通用属性。对文本表征进行采样,并利用概率像素-文本匹配损失来指导密集预测任务,从而增强了所提方法的稳定性和泛化能力。在不同的密集预测任务和消融研究中进行的大量实验证明了我们提出的方法的有效性。
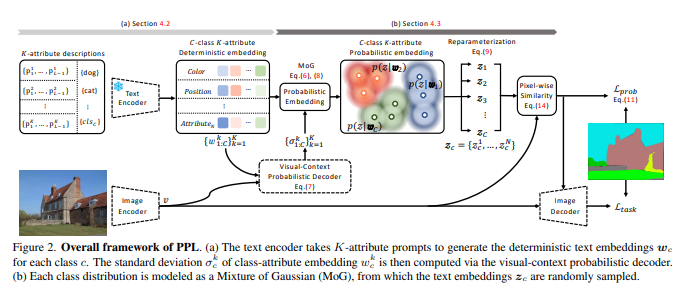
创新点:
(1) 我们提出了一种新颖的 PPL,可以在概率文本嵌入空间中有效地表示对象的类别无关属性。据我们所知,这是利用上下文感知概率提示学习的首次尝试。
(2) 我们引入了一种新的概率像素-文本匹配损失,以减轻不确定性的不利影响.
(3) 我们通过对密集预测任务(包括语义分割、实例分割和对象检测)的大量实验,证明了所提出的概率方法的有效性。
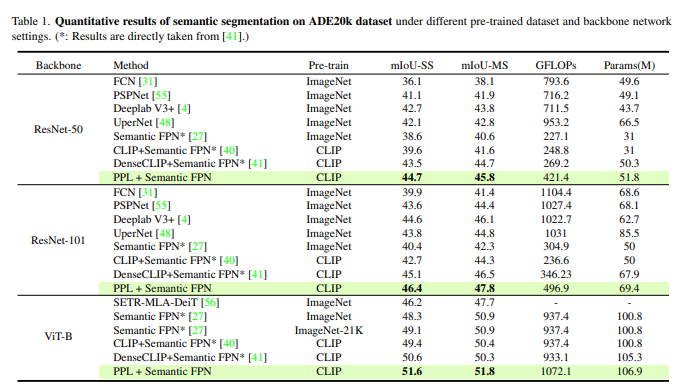
结果:
论文2 DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
方法:
本文通过隐式和显式利用来自 CLIP 的预训练知识,提出了一种新的密集预测框架。具体来说,我们将 CLIP 中的原始图像-文本匹配问题转换为像素-文本匹配问题,并使用像素-文本得分图来指导密集预测模型的学习。通过进一步使用图像中的上下文信息来提示语言模型,我们能够促进我们的模型更好地利用预训练知识。我们的方法与模型无关,可应用于任意密集预测系统和各种预训练视觉骨干,包括 CLIP 模型和 ImageNet 预训练模型。广泛的实验证明了我们的方法在语义分割、对象检测和实例分割任务中的卓越性能。
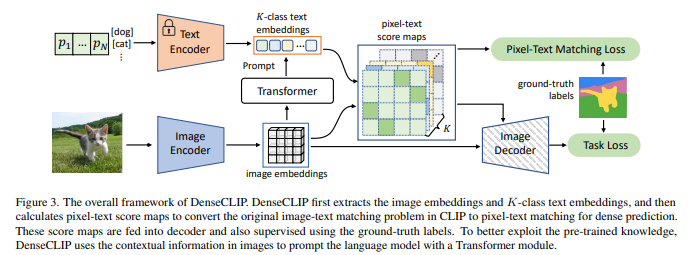
创新点:
(1) 挑战识别:传统的 CLIP 模型在预训练时注重图像和文本的实例级表示,而下游的密集预测任务需要像素级的视觉信息。这种差距导致了直接微调 CLIP 模型时,性能提升受限。
(2) 框架介绍:为了解决这一问题,本文提出了一种新的语言引导密集预测框架 DenseCLIP。该框架通过隐式和显式两种方式充分利用 CLIP 模型的预训练知识,为密集预测任务设计。
(3) 隐式方法:通过直接在下游数据集上微调 CLIP 模型,并对超参数进行调整,DenseCLIP 已经在性能上超越了传统的 ImageNet 预训练模型。
(4) 显式方法:为充分发挥 CLIP 的潜力,本文将原始的图像-文本匹配问题转化为像素-文本匹配问题,并使用像素-文本得分图指导模型的学习。Transformer 模块用于增强模型对上下文信息的捕捉。
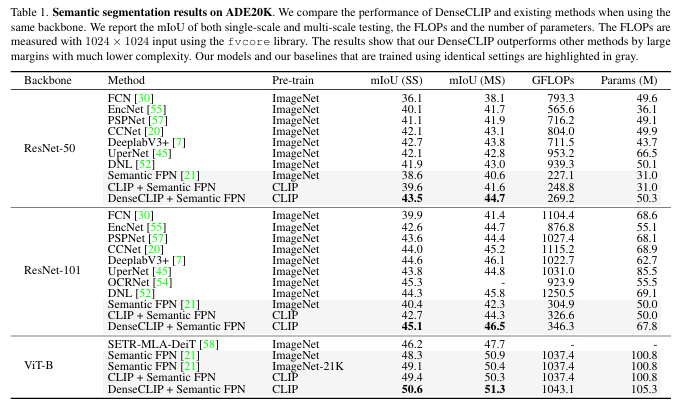
(5) 性能提升:DenseCLIP 框架在 ADE20K 数据集上表现出色,使用 Semantic FPN 框架实现了 mIoU 的显著提升,并且在物体检测和实例分割任务中也有明显的性能改进。
(6) 广泛适用性:DenseCLIP 适用于多种密集预测方法和任务,并且在不同骨干模型上,如 ResNets 和 Swin Transformers,均表现出显著的性能提升,计算开销很小。
结果:
论文3 Learning Transferable Visual Models From Natural Language Supervision
方法:
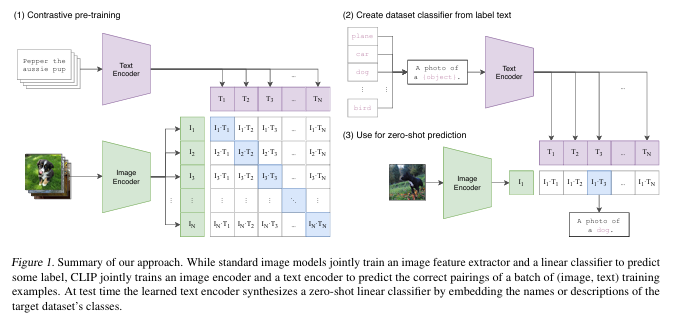
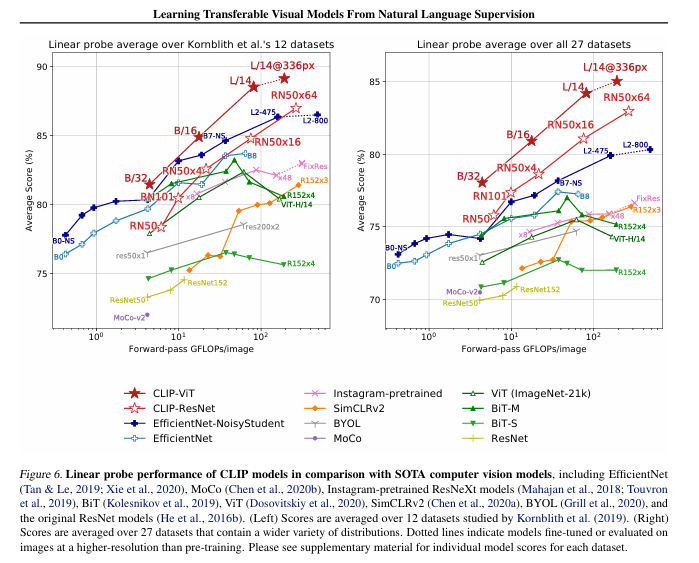
本文证明了一种有效且可扩展的预训练方法,通过预测图像与标题的匹配关系,利用互联网收集的 4 亿对图像和文本数据集,从头开始学习出色的图像表示。在预训练完成后,该模型能够通过自然语言引用或描述视觉概念,实现零样本迁移到不同的下游任务。研究表明,该模型在超过 30 个计算机视觉数据集上表现出色,涵盖 OCR、视频动作识别、地理定位和细粒度对象分类等任务。该模型在大多数任务中能够与完全监督的基线竞争,且无需进行特定数据集的训练。例如,它在 ImageNet 零样本测试中,无需使用 ResNet50 的任何训练样本,即达到了与其相当的准确性。
创新点:
(1) 预训练方法的扩展:借鉴NLP领域中通过大规模文本数据进行预训练的方法,将其应用到计算机视觉领域,尝试通过自然语言监督来训练图像模型。
(2) CLIP模型的提出开发了一种名为CLIP(对比语言图像预训练)的新模型,简化并扩展了之前的ConVIRT模型,从头开始在大规模图像和文本对上进行训练。
(3) 大规模训练的影响,在大规模图像和文本数据集上进行训练,CLIP实现了更高效的学习,能够在更少的计算资源下,超越当前最佳的ImageNet模型。
(4) 多任务能力:CLIP在预训练期间学习了多种任务的执行,包括OCR、地理定位和动作识别,展现了其在不同任务中的广泛应用潜力。
(5) 零样本学习的增强CLIP展示了卓越的零样本学习能力,在不需要特定于数据集的训练数据的情况下,能够在多个任务中与传统的完全监督模型竞争,并且表现出更强的稳健性。
结果:
论文4 ActionCLIP: A New Paradigm for Video Action Recognition
方法:
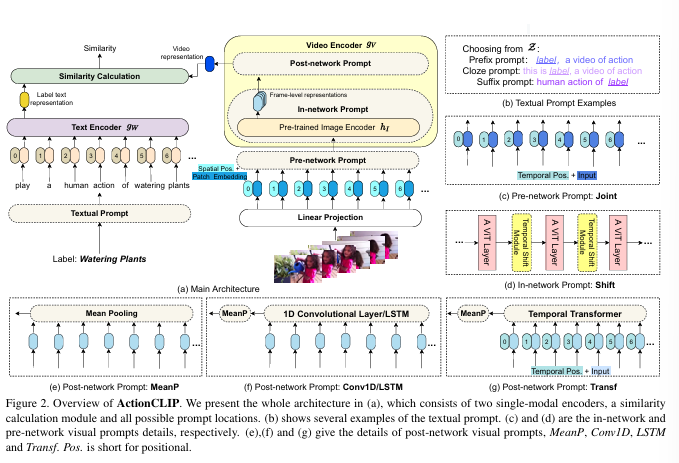
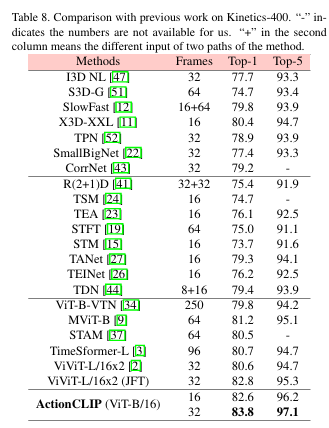
本文提出了一种基于多模态学习框架的动作识别新范式,我们将其称为“预训练、提示和微调”。该范例首先从大量网络图像文本或视频文本数据的预训练中学习强大的表示。然后,它通过即时工程使动作识别任务更像预训练问题。最后,它对目标数据集进行端到端微调以获得强大的性能。我们给出了新范式 ActionCLIP 的实例,它不仅具有优越且灵活的零样本/少样本转移能力,而且在一般动作识别任务上达到了顶级性能,在动力学上达到了 83.8% 的 top-1 准确率。
创新点:
(1) 本文将动作识别任务制定为多模态学习问题,而不是传统的单模态分类任务。它通过更多的语义语言监督加强了表示,并扩大了模型在零样本/少样本情况下的通用性和使用性。
(2) 本文提出了一种新的动作识别范式,我们称之为“预训练、提示和微调”。在这种范式中,我们可以通过设计适当的提示来直接重用强大的大规模网络数据预训练模型,从而显着降低预训练成本。
(3) 全面的实验证明了我们的方法的潜力和有效性,该方法在多个公共基准数据集上始终优于最先进的方法。
结果:

















 1097
1097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









