







一、过拟合的原因
- 主要原因是训练数据中存在噪音或者训练数据太少,或训练集和测试集特征分布不一致
- 根本的原因则是特征维度(或参数)过多,导致模型完美拟合训练集,对新数据的预测结果较差
二、如何解决过拟合
- simpler model structure:减小模型复杂度(缩小宽度和减小深度)
- data augmentation:随机drop和shuffle、同义词替换、回译、文档裁剪......
- regularization:L0范数是指向量中非0的元素的个数,L1范数是指向量中各个元素绝对值之和,也叫“稀疏规则算子”(Lasso regularization)但常用的为L1?因为L0范数很难优化求解(NP难问题),二是L1范数是L0范数的最优凸近似,而且它比L0范数要容易优化求解。(筛掉稀疏的特征)

- dropout:
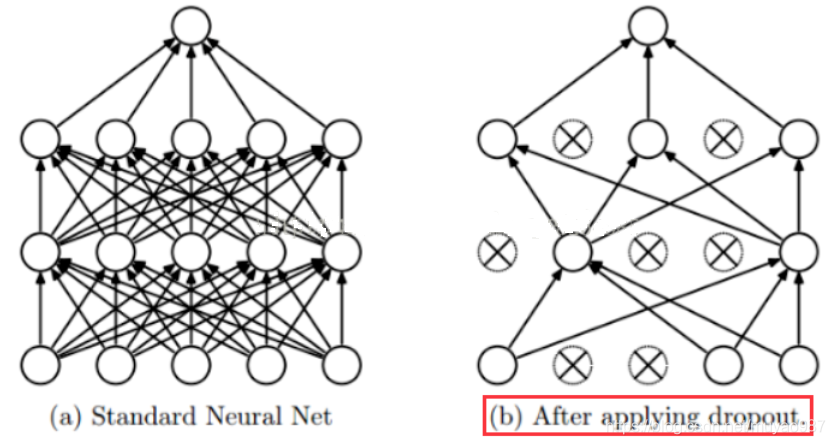
- early stopping:在模型对训练数据集迭代收敛之前停止迭代(连续10次Epoch(或者更多次)没达到最佳accuracy时,则可以认为accuracy不再提高了。此时便可以停止迭代了(Early Stopping)。这种策略也称为“No-improvement-in-n”,n即Epoch的次数,可以根据实际情况取,如10、20、30……)
- ensemble:Bagging通过平均多个模型的结果,来降低模型的方差。Boosting减小偏差。
- 重新清洗数据:检查数据一致性,处理无效值和缺失值等。
【参考资料】

















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









