







CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
今天带来的arXiv上最新发表的3篇AI论文。
Subjects: cs.AI、cs.Cv
1.Revisiting Temporal Modeling for CLIP-based Image-to-Video Knowledge Transferring

标题:重新审视基于CLIP的图像-视频知识转移的时间模型
作者: Ruyang Liu, Jingjia Huang, Ge Li, Jiashi Feng, Xinglong Wu, Thomas H. Li
文章链接:https://arxiv.org/abs/2301.11116v1

摘要:
图像-文本预训练模型,例如CLIP,已经显示出从大规模图像-文本数据对中学习到的令人印象深刻的通用多模式知识,因此它们在改善视频领域的视觉表征学习方面的潜力引起了越来越多的关注。在本文中,基于CLIP模型,我们重新审视了图像到视频知识转移背景下的时间建模,这是扩展图像-文本预训练模型到视频领域的关键点。我们发现,目前的时间建模机制要么是针对高层次的语义主导任务(如检索),要么是针对低层次的视觉模式主导任务(如识别),而不能同时适用于这两种情况。关键的困难在于对时间依赖性进行建模,同时利用CLIP模型中的高层和低层知识。为了解决这个问题,我们提出了空间-时间辅助网络(STAN)--一个简单而有效的时间建模机制,将CLIP模型扩展到不同的视频任务。具体来说,为了实现低层次和高层次的知识转移,STAN采用了一个带有分解的空间-时间模块的分支结构,使多层次的CLIP特征能够被空间-时间背景化。我们在两个有代表性的视频任务上评估我们的方法。视频-文本检索和视频识别。广泛的实验证明了我们的模型在各种数据集上比最先进的方法优越,包括MSR-VTT、DiDeMo、LSMDC、MSVD、Kinetics-400和Something-V2。
代码将在https://github.com/farewellthree/STAN
Image-text pretrained models, e.g., CLIP, have shown impressive general multi-modal knowledge learned from large-scale image-text data pairs, thus attracting increasing attention for their potential to improve visual representation learning in the video domain. In this paper, based on the CLIP model, we revisit temporal modeling in the context of image-to-video knowledge transferring, which is the key point for extending image-text pretrained models to the video domain. We find that current temporal modeling mechanisms are tailored to either high-level semantic-dominant tasks (e.g., retrieval) or low-level visual pattern-dominant tasks (e.g., recognition), and fail to work on the two cases simultaneously. The key difficulty lies in modeling temporal dependency while taking advantage of both high-level and low-level knowledge in CLIP model. To tackle this problem, we present Spatial-Temporal Auxiliary Network (STAN) -- a simple and effective temporal modeling mechanism extending CLIP model to diverse video tasks. Specifically, to realize both low-level and high-level knowledge transferring, STAN adopts a branch structure with decomposed spatial-temporal modules that enable multi-level CLIP features to be spatial-temporally contextualized. We evaluate our method on two representative video tasks: Video-Text Retrieval and Video Recognition. Extensive experiments demonstrate the superiority of our model over the state-of-the-art methods on various datasets, including MSR-VTT, DiDeMo, LSMDC, MSVD, Kinetics-400, and Something-Something-V2. Codes will be available at https://github.com/farewellthree/STAN
2.The Projection-Enhancement Network (PEN)

标题:投影增强网络(PEN)
作者: Christopher Z. Eddy, Austin Naylor, Bo Sun
文章链接:https://arxiv.org/abs/2301.10877v1
摘要:
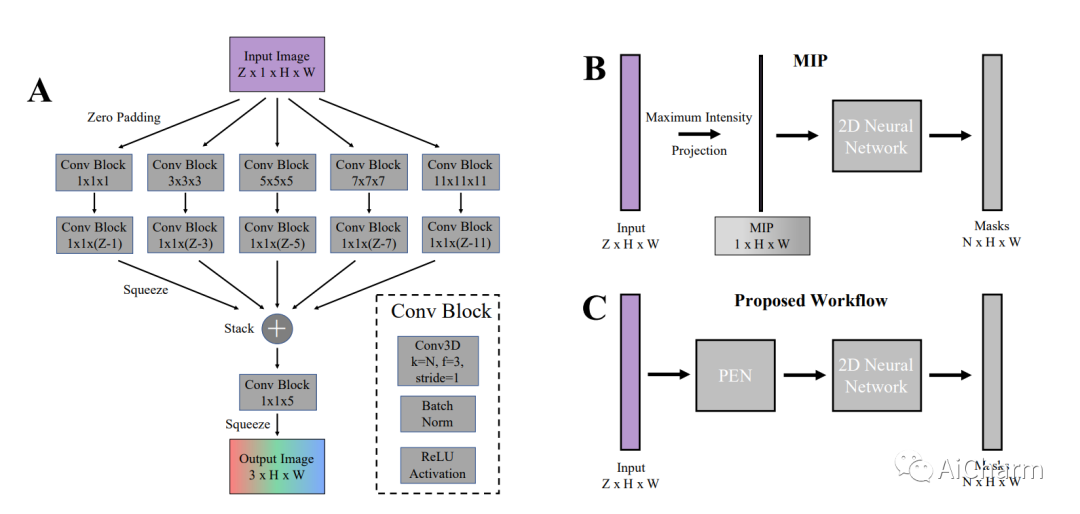
当代细胞科学中的实例分割方法根据实验和数据结构使用二维或三维卷积网络。然而,显微镜系统的限制或防止光毒性的努力通常需要记录次优的采样数据,这大大降低了这种三维数据的效用,特别是在对象之间有显著轴向重叠的拥挤环境中。在这种情况下,二维分割对细胞形态来说更可靠,也更容易进行注释。在这项工作中,我们提出了投影增强网络(PEN),这是一个新颖的卷积模块,它处理子采样的3D数据并产生2D RGB语义压缩,并与选择的实例分割网络一起训练以产生2D分割。我们的方法结合了增加细胞密度,使用低密度的细胞图像数据集来训练PEN,并通过策划数据集来评估PEN。我们表明,通过PEN,CellPose中学习到的语义表示对深度进行了编码,与作为输入的最大强度投影图像相比,大大提高了分割性能,但对基于区域的网络如Mask-RCNN的分割没有类似帮助。最后,我们剖析了PEN与CellPose在并排球状体的传播细胞上对细胞密度的分割强度。我们将PEN作为一个数据驱动的解决方案,以形成三维数据的压缩表示,改善实例分割网络的二维分割。
Contemporary approaches to instance segmentation in cell science use 2D or 3D convolutional networks depending on the experiment and data structures. However, limitations in microscopy systems or efforts to prevent phototoxicity commonly require recording sub-optimally sampled data regimes that greatly reduces the utility of such 3D data, especially in crowded environments with significant axial overlap between objects. In such regimes, 2D segmentations are both more reliable for cell morphology and easier to annotate. In this work, we propose the Projection Enhancement Network (PEN), a novel convolutional module which processes the sub-sampled 3D data and produces a 2D RGB semantic compression, and is trained in conjunction with an instance segmentation network of choice to produce 2D segmentations. Our approach combines augmentation to increase cell density using a low-density cell image dataset to train PEN, and curated datasets to evaluate PEN. We show that with PEN, the learned semantic representation in CellPose encodes depth and greatly improves segmentation performance in comparison to maximum intensity projection images as input, but does not similarly aid segmentation in region-based networks like Mask-RCNN. Finally, we dissect the segmentation strength against cell density of PEN with CellPose on disseminated cells from side-by-side spheroids. We present PEN as a data-driven solution to form compressed representations of 3D data that improve 2D segmentations from instance segmentation networks.
Subjects: cs.AI、cs.LG、cs.CE、cs.CL
1.Molecular Language Model as Multi-task Generator

标题:作为多任务发生器的分子语言模型
作者: Yin Fang, Ningyu Zhang, Zhuo Chen, Xiaohui Fan, Huajun Chen
文章链接:https://arxiv.org/abs/2301.11259v1
摘要:
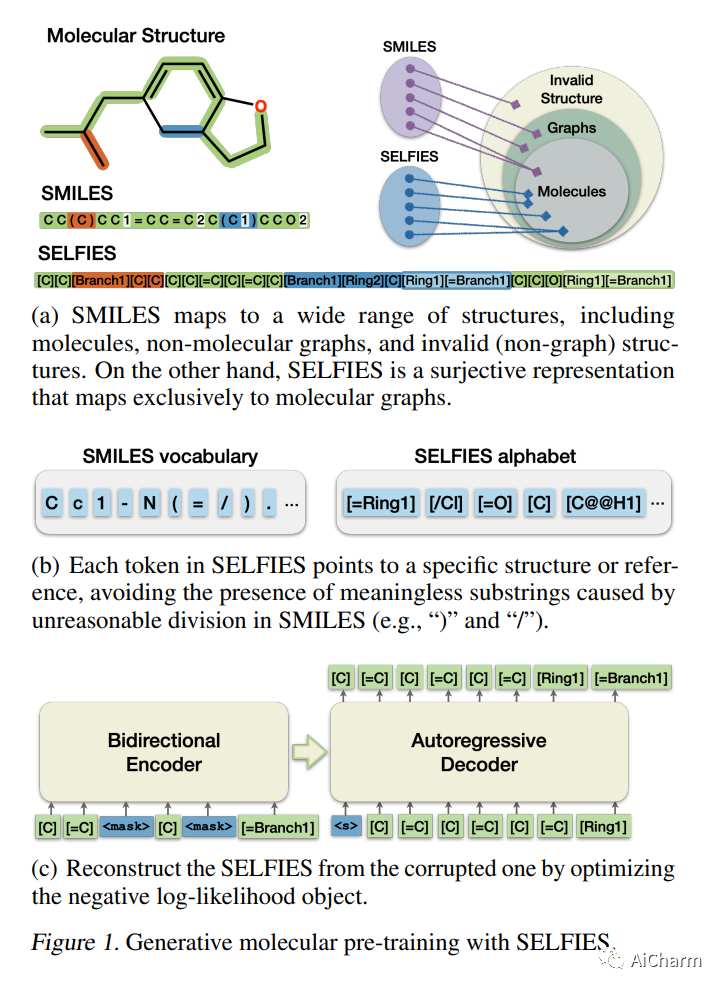
具有所需特性的分子生成,颠覆性地改变了科学家设计分子结构的方式,为化学和材料设计提供了支持,从而获得了巨大的人气。然而,尽管成果喜人,但以前基于机器学习的深度生成模型存在着对复杂的、特定任务的微调、有限维度的潜在空间或专家规则质量的依赖。在这项工作中,我们提出了MolGen,一个预训练的分子语言模型,可以有效地学习和分享多个生成任务和领域的知识。具体来说,我们用化学语言SELFIES对超过1亿个没有标签的分子进行了预训练。我们进一步提出在多个分子生成任务和不同的分子领域(合成和天然产品)中通过自我反馈机制进行多任务分子前缀调整。大量的实验表明,MolGen可以在著名的分子生成基准数据集上获得卓越的性能。进一步的分析表明,MolGen可以准确地捕捉分子的分布,隐含地学习它们的结构特征,并在多任务分子前缀调整的指导下有效地探索化学空间。代码、数据集和预训练模型将在https://github.com/zjunlp/MolGen。
Molecule generation with desired properties has grown immensely in popularity by disruptively changing the way scientists design molecular structures and providing support for chemical and materials design. However, despite the promising outcome, previous machine learning-based deep generative models suffer from a reliance on complex, task-specific fine-tuning, limited dimensional latent spaces, or the quality of expert rules. In this work, we propose MolGen, a pre-trained molecular language model that effectively learns and shares knowledge across multiple generation tasks and domains. Specifically, we pre-train MolGen with the chemical language SELFIES on more than 100 million unlabelled molecules. We further propose multi-task molecular prefix tuning across several molecular generation tasks and different molecular domains (synthetic & natural products) with a self-feedback mechanism. Extensive experiments show that MolGen can obtain superior performances on well-known molecular generation benchmark datasets. The further analysis illustrates that MolGen can accurately capture the distribution of molecules, implicitly learn their structural characteristics, and efficiently explore the chemical space with the guidance of multi-task molecular prefix tuning. Codes, datasets, and the pre-trained model will be available in this https https://github.com/zjunlp/MolGen.

















 916
916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











