







前言
文章性质:学习笔记 📖
学习资料:吴茂贵《 Python 深度学习基于 PyTorch ( 第 2 版 ) 》【ISBN】978-7-111-71880-2
主要内容:根据学习资料撰写的学习笔记,该篇主要介绍了卷积神经网络的池化层部分和现代经典网络。
一、池化层
池化 Pooling 又称下采样,通过卷积层获得图像的特征后,理论上可以直接使用这些特征训练分类器,例如 softmax 。但这样会面临巨大的计算量挑战,而且容易产生过拟合的线下。为了降低网络训练参数及模型的过拟合程度,需要对卷机层进行池化处理。
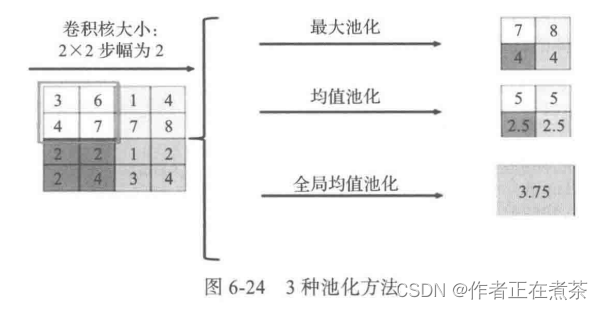
最大池化 Max Pooling:选择 Pooling 窗口中的最大值作为采样值。
均值池化 Mean Pooling:选择 Pooling 窗口中的所有值相加取平均,以平均值作为采样值。
全局最大 / 均值池化:与最大或均值池化不同,全局池化是对整个特征图的池化,而不是在移动窗口范围内的池化。
池化层在卷积神经网络中可用来减小尺寸,提高运算速度及减小噪声影响,让各特征更具有健壮性。池化层比卷积层简单,它没有卷积运算,只是在滤波器算子滑动区域内取最大值或平均值。池化的作用体现在下采样:保留显著特征、降低特征维度、增大感受野。深度网络越往后面越能捕捉到物体的语义信息,这种语义信息建立在较大的感受野基础上。
1、局部池化
局部池化:在移动窗口内的池化,取窗口内的最大值或平均值作为结果,经过操作后,特征图下采样,减少过拟合现象。
在 PyTorch 中,最大池化常使用 nn.MaxPool2d ,平均池化使用 nn.AvgPool2d 。在实际应用中,最大池化最为常用:
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1,
return_indices=False, ceil_mode=False)| 参数 | 说明 |
|---|---|
| kernel_size | 池化窗口的大小,取四维向量,通常是 [height, width] 若二者相等,可以是数字,例如 kernel_size = 3 |
| stride | 窗口在每个维度上滑动的步长,通常是 [stride_w, stride_h] 若二者相等,可以是数字,例如 stride = 1 |
| padding | 与卷积类似,输入的每一条边补充 0 的层数 |
| dilation | 卷积对输入数据的空间间隔 |
| return_indices | 是否返回最大值对应的下标 |
| ceil_mode | 使用一些方块代替层结构 |
假设输入 input 的形状为 ,输出 output 的形状为
,则输出大小与输入大小的计算公式为:
说明:如果不能整除,则取整数。
import torch
import torch.nn as nn
# 池化窗口为正方形 kernel_size=3,stride=2
m1 = nn.MaxPool2d(3, stride=2)
# 池化窗口为非正方形
m2 = nn.MaxPool2d((3, 2), stride=(2, 1))
input = torch.randn(20, 16, 50, 32)
output = m2(input)
print(output.shape)
# torch.Size([20, 16, 24, 31])2、全局池化
与局部池化相对的就是全局池化,也分最大池化或平均池化。局部平均池化会有卷积核大小限制,比如 2×2 ,而全局平均池化没有大小限制,它针对的是整张特征图。我们以全局平均池化为例进行讲解,全局平均池化 Global Average Pooling 不以窗口的形式取均值,而是以特征图为单位进行均值化,即一个特征图输出一个值。具体说明如图 6-25 所示。
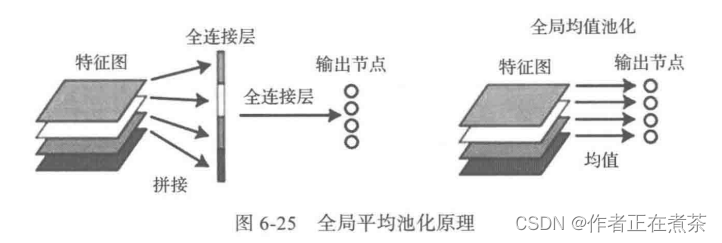
图左:将 4 个特征图先用一个全连接层展平为一个向量,然后通过一个全连接层输出为 4 个分类节点。GAP 可以将这两步合并。
图右:将 GAP 视为特殊的平均池化层,其池的大小与整个特征图的大小相同,其实就是求每张特征图所有像素的均值,输出一个数据值,这样 4 个特征图就会输出 4 个数据点,这些数据点将组成一个 1×4 的向量。
使用全局平均池化代替 CNN 中传统的全连接层。在使用卷积层的识别任务中,全局平均池化能够为每个特定的类别生成一个特征图。GAP 的优势在于:
- 相较于全连接层的黑箱,各类别与特征图之间的联系更加直观,特征图被转化为分类概率更加容易;
- GAP 不需要调参数,避免了过拟合问题;
- GAP 汇总了空间信息,因此对输入的空间转换更具鲁棒性。
所以目前卷积网络中最后几个全连接层大都被 GAP 替换了。
全局池化层在 Keras 中有对应的层,如全局最大池化层 GlobalMaxPooling2D ,PyTorch 中虽然没有对应名称的池化层,但可以使用其中的自适应池化层 AdaptiveMaxPool2d 或者 nn.AdaptiveAvgPool2d 实现。
import torch
import torch.nn as nn
# nn.AdaptiveMaxPool2d(output_size, return_indices=False)
# 输出大小为 5×7
m = nn.AdaptiveMaxPool2d((5, 7))
input = torch.randn(1, 64, 8, 9)
output = m(input)
print(output.size())
# 输出大小为 7×7
m = nn.AdaptiveMaxPool2d(7)
input = torch.randn(1, 64, 10, 9)
output = m(input)
print(output.size())
# 输出大小为 10×7
m = nn.AdaptiveMaxPool2d((None, 7))
input = torch.randn(1, 64, 10, 9)
output = m(input)
print(output.size())
# 输出大小为 1×1
m = nn.AdaptiveMaxPool2d((1))
input = torch.randn(1, 64, 10, 9)
output = m(input)
print(output.size())
说明:自适应池化层的输出张量的大小都是给定的 output_size 。例如输入张量大小为 (1, 64, 8, 9),设定输出大小为 (5, 7),通过自适应池化层,可以得到大小为 (1, 64, 5, 7) 的张量。
二、现代经典网络
最近几年卷积神经网络大致的发展轨迹:
1、LeNet-5 模型
LeNet 模型由卷积神经网络大师 LeCun 在 1998 年提出,用于完成手写数字识别的视觉任务,定下了CNN 的基本架构:卷积层、池化层、全连接层。LeNet-5 模型架构:输入层—卷积层—池化层—卷积层—池化层—全连接层—全连接层—输出层,为串联模式。
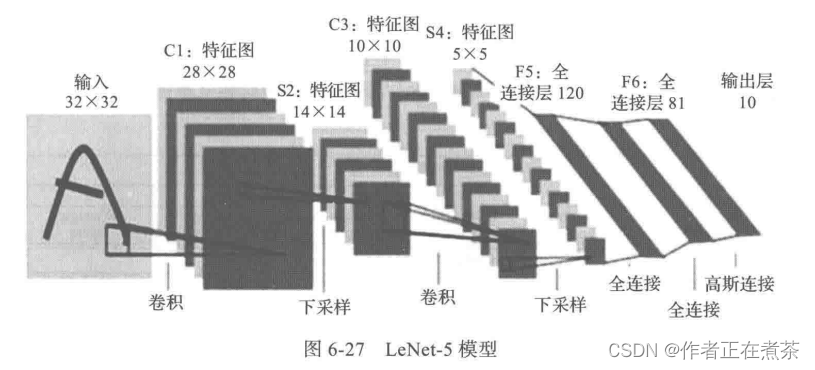
LeNet-5 模型具有如下特点:
- 每个卷积层包含 3 个部分:卷积、池化和非线性激活函数。
- 使用卷积提取空间特征。
- 采用下采样的平均池化层。
- 使用双曲正切 Tanh 的激活函数。
- 最后用 MLP 作为分类器。
2、AlexNet 模型
AlexNet 在 2012 年的 ImageNet 竞赛中以超过第二名 10.9 个百分点的绝对优势夺冠,自此,深度学习和卷积神经网络得到迅速发展。AlexNet 为 8 层深度网络,包含 5 层卷积层和 3 层全连接层,不计 LRN 层和池化层。
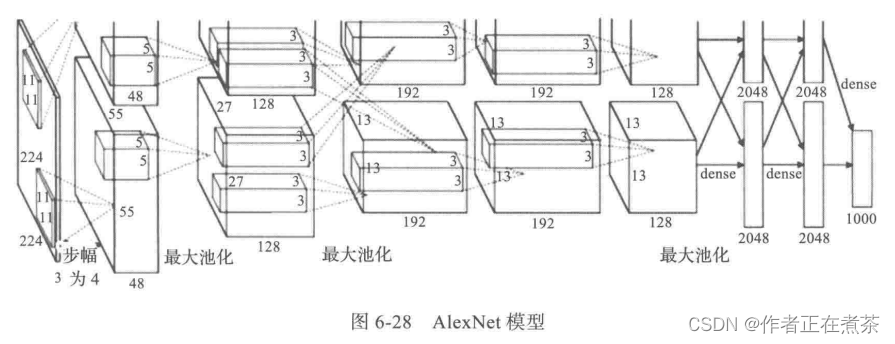
AlexNet 模型具有如下特点:
- 由 5 层卷积层和 3 层 全连接层组成,输入图像为三通道,大小为 224×224 ,网络规模远大于 LeNet 。
- 使用 ReLU 激活函数。
- 使用 dropout 作为正则项,防止过拟合,提升模型鲁棒性。
- 具备一些很好的训练技巧,包括数据增广、学习率策略、权重衰减 Weight Decay 等。
3、VGG 模型
Visual Geometry Group 可以看作升级版本的 AlexNet ,也是由卷积层和全连接层组成,且层数高达 16 或 19 层。

VGG 模型具有如下特点:
- 更深的网络结构。网络层数由 AlexNet 的 8 层增至 16 或 19 层。更深的网络意味着更强大的网络能力,也意味着需要更强大的计算力,不过后来硬件发展也很快,显卡运算力也在快速增长,助推了深度学习的快速发展。
- 模型中使用较小的 3×3 卷积核。两个 3×3 的感受野相当于一个 5×5,且参数量更少,之后的网络都基本遵循这个范式。
4、GoogLeNet 模型
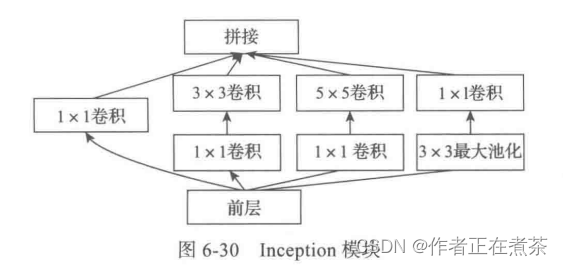
虽然 VGG 模型增加了网络的深度,但当深度达到一定程度时,可能成为瓶颈。GoogLeNet 模型 则从另一个维度来增加网络能力,即让每个单元有许多层并行计算,使网络更宽。基本单元,Inception 模块 如图 6-30 所示。
GoogLeNet 模型架构如图 6-31 所示,包含多个 Inception 模块,且为了便于训练,还添加了两个辅助分类分支补充梯度。

GoogLeNet 模型具有如下特点:
- 引入 Inception 模块,这是一种 Network In Network 网中网结构。通过网络的水平排布,可以用较浅的网络得到很好的模型能力,并进行多特征融合,同时更容易训练。另外,为了减少计算量,使用 1×1 卷积来对特征通道进行降维。Inception 模块堆叠起来就形成了 Inception 网络,而 GoogLeNet 就是一个精心设计的、性能良好的 Inception v1 网络 的实例。
- 采用全局平均池化层,将后面的全连接层全部替换为简单的全局平均池化层,最后的参数会变得更少,例如 AlexNet 中最后 3 层的全连接层参数差不多占总数的 90% ,GoogLeNet 的宽度和深度部分移除了全连接层,不会影响到结果的精度,在 ImageNet 竞赛中实现了 93.3 %的精度,且比 VGG 还快。不过,网络太深无法很好训练的问题始终没有得到解决,直到 ResNet 提出了 残差链接 。
5、ResNet 模型
何恺明在 2015 年推出的 ResNet 模型在 ISLVRC 和 COCO 上超越其他模型,获得冠军。ResNet 在网络结构上做出创新,即采用残差网络结构,而不再简单地堆积层数,为卷积神经网络提供了新思路。残差网络的核心思想:输出的是两个连续的卷积层,并且输入下一层。ResNet 残差网络结构如图 6-32 所示。
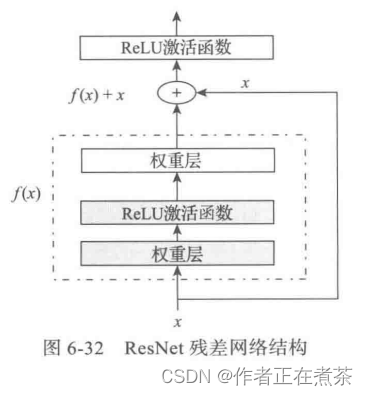
通过引入残差、恒等映射 indentity mapping ,相当于一个梯度高速通道,使训练更简洁,且避免了梯度消失问题,所以可以得到更深的网络,如网络层数由 GoogLeNet 的 22 层发展到 ResNet 的 152 层。
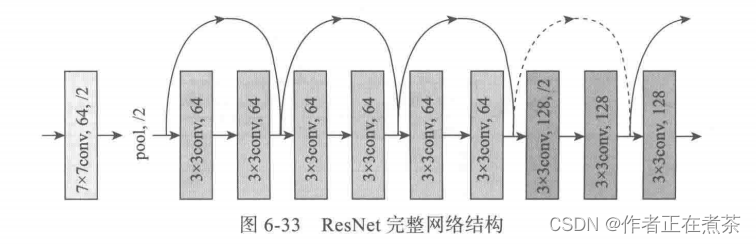
ResNet 模型具有如下特点:
- 层数非常深,已经超过百层。
- 引入残差单元来解决退化问题。
6、DenseNet 模型
ResNet 模型极大地改变了参数化深层网络中函数的方式,DenseNet 稠密网络在某种程度上可以说是 ResNet 的逻辑扩展,其每一层的特征图是后面所有层的输入。DenseNet 网络结构如图 6-34 所示。
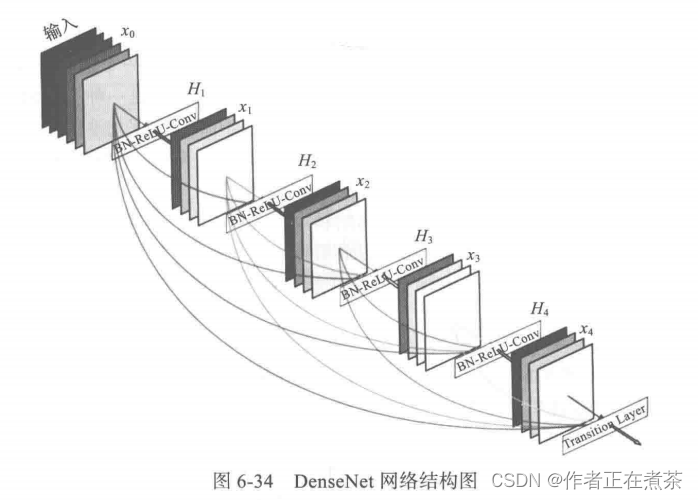
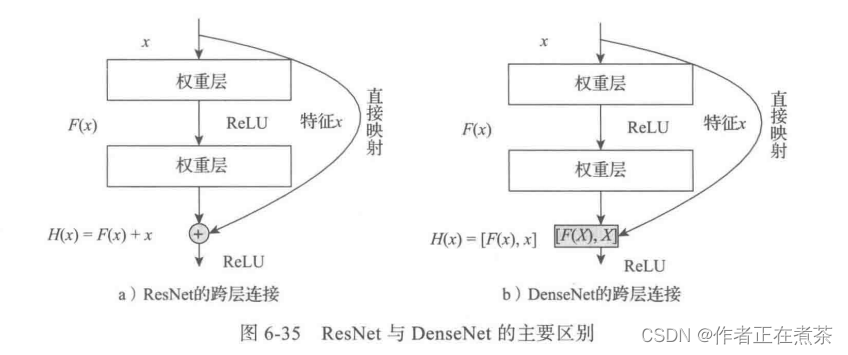
ResNet 模型和 DenseNet 模型的主要区别在于,DenseNet 的输出是连接,而不是 ResNet 的简单相加。
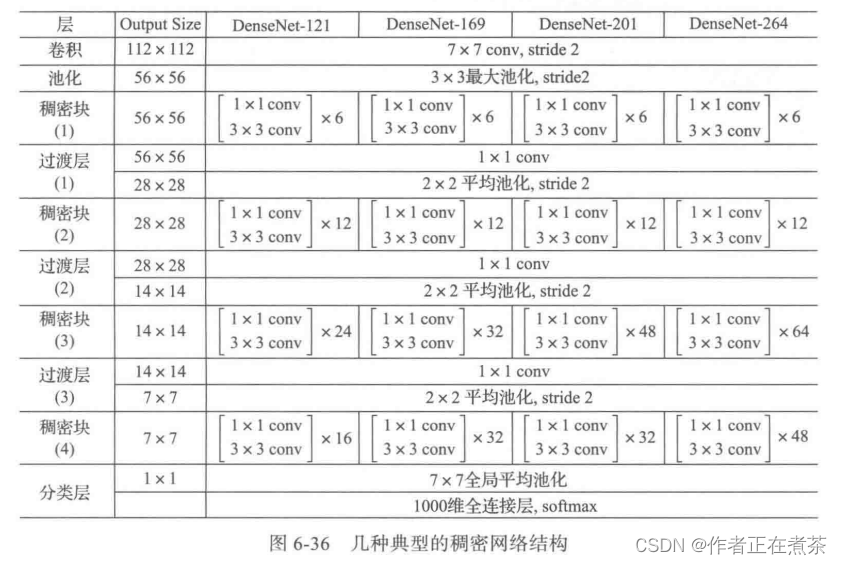
DenseNet 模型主要由两部分构成:稠密块 Dense Block 和 过渡层 Transition Layer 。前者定义如何连接输入和输出,后者控制通道数量、特征图的大小等,使其不会太复杂。图 6-36 是几种典型的稠密网络结构。
DenseNet 模型的主要创新点如下:
- 相较于 ResNet 模型,DenseNet 拥有更少的参数数量。
- 旁路加强了特征的重用。
- 网络更易于训练,并且具有一定正则效果。
- 缓解了梯度消失 Gradient Vanishing 和模型退化 Model Degradation 的问题。
7、CapsNet 模型
Hinton 及其团队在 2017 年底提出了全新的神经网络,即胶囊网络 CapsNet 模型。胶囊网络克服了卷积神经网络的一些不足:
- 训练卷积神经网络一般需要较大数据量,而胶囊网络使用较少数据就能泛化。
- 卷积神经网络因池化层、全连接层等丢失大量的信息,从而降低了空间位置的分辨率,而胶囊网络能将很多细节的姿态信息,如对象的准确位置、旋转、厚度、倾斜度、尺寸等,保存在网络中,从而有效避免嘴巴和眼睛倒挂也被认为是人脸的错误。
- 卷积神经网络不能很好地应对模糊性,但胶囊网络可以,因此胶囊网络在非常拥挤的场景也能表现得很好。
如图 6-37 所示,CapsNet 网络架构由两个卷积层和一个全连接层组成,其中,第一个卷积层为一般的卷积层,第二个卷积层相当于为 Capsule 层做准备,并且该层的输出为向量,所以它的维度要比一般的卷积层再高一个维度。最后就是通过向量的输入与路由过程等构建 10 个向量,每一个向量的长度都直接表示某个类别的概率。
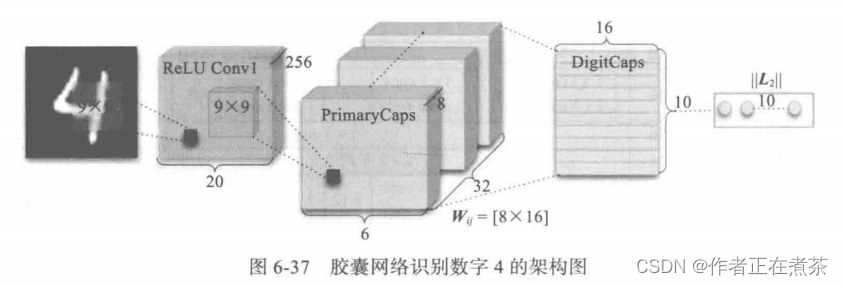
CapsNet 模型具有如下特点:
- 神经元输出为向量。每个胶囊给出的输出是一组向量,而不是传统人工神经元那样的单独数值(权重)。
- 采用动态路由机制。为了解决这组向量向哪一个更高层的神经元传输的问题,就需要动态路由 Dynamic Routing 机制,而这就是胶囊神经网络的一大创新点。动态路由使胶囊神经网络可以识别图形中的多个图形,这是 CNN 所不能的。
说明:虽然 CapsNet 在简单的数据集 MNIST 上表现出了很好的性能,但是在更复杂的数据集如 ImageNet、CIFAR10上,却没有这种表现。这是因为在图像中发现的信息过多会使胶囊脱落。
















 549
549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











