







目录
前言
文章性质:学习笔记 📖
视频教程:使用 Pytorch 搭建 U-Net 网络并基于 DRIVE 数据集训练(语义分割)-2 自定义数据集读取
主要内容:根据 视频教程 中提供的 U-Net 源代码(PyTorch),对 my_dataset.py 文件进行具体讲解。
Preparation
├── src: 搭建U-Net模型代码
├── train_utils: 训练、验证以及多GPU训练相关模块
├── my_dataset.py: 自定义dataset用于读取DRIVE数据集(视网膜血管分割)
├── train.py: 以单GPU为例进行训练
├── train_multi_GPU.py: 针对使用多GPU的用户使用
├── predict.py: 简易的预测脚本,使用训练好的权重进行预测测试
└── compute_mean_std.py: 统计数据集各通道的均值和标准差
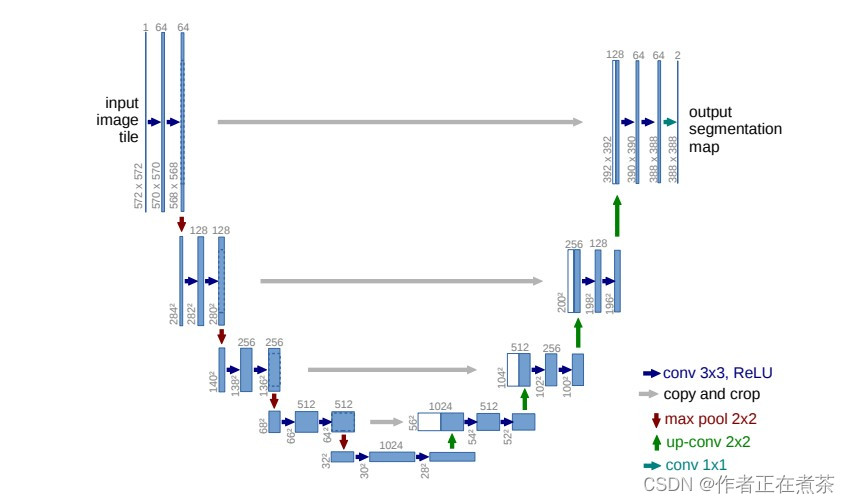
一、U-Net 网络结构图
原论文提供的 U-Net 网络结构图如下所示:
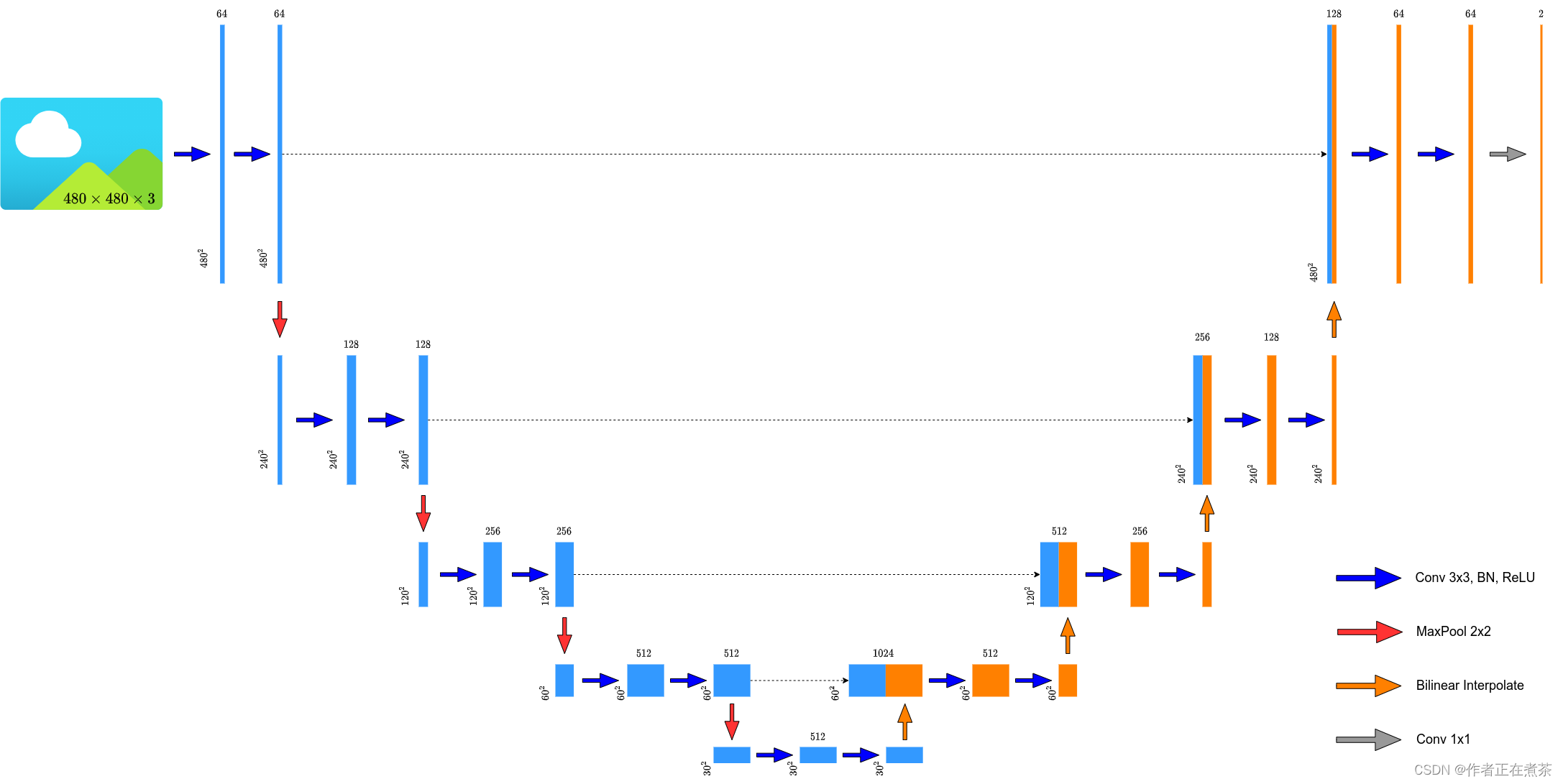
原论文中提供的 U-Net 网络结构所使用的卷积层会改变特征层的高和宽,而现在比较主流的方式是 不去改变输入特征层的高和宽 ,将转置卷积替换成简单的双线性插值进行上采样,所以霹雳吧啦重绘的 U-Net 网络结构图也是按照 双线性插值 进行绘制的,如下图所示:
二、U-Net 网络源代码
1、my_dataset.py 解析
在 my_dataset.py 文件中,DriveDataset 类继承自 Dataset 父类,其 __init__ 初始化函数的传入参数包括:
- root 指 DRIVE 文件夹所在的根目录
- train 为 True 时载入 training 数据集中的数据,train 为 False 时载入 test 数据集中的数据
- transforms 定义了针对数据的预处理方式
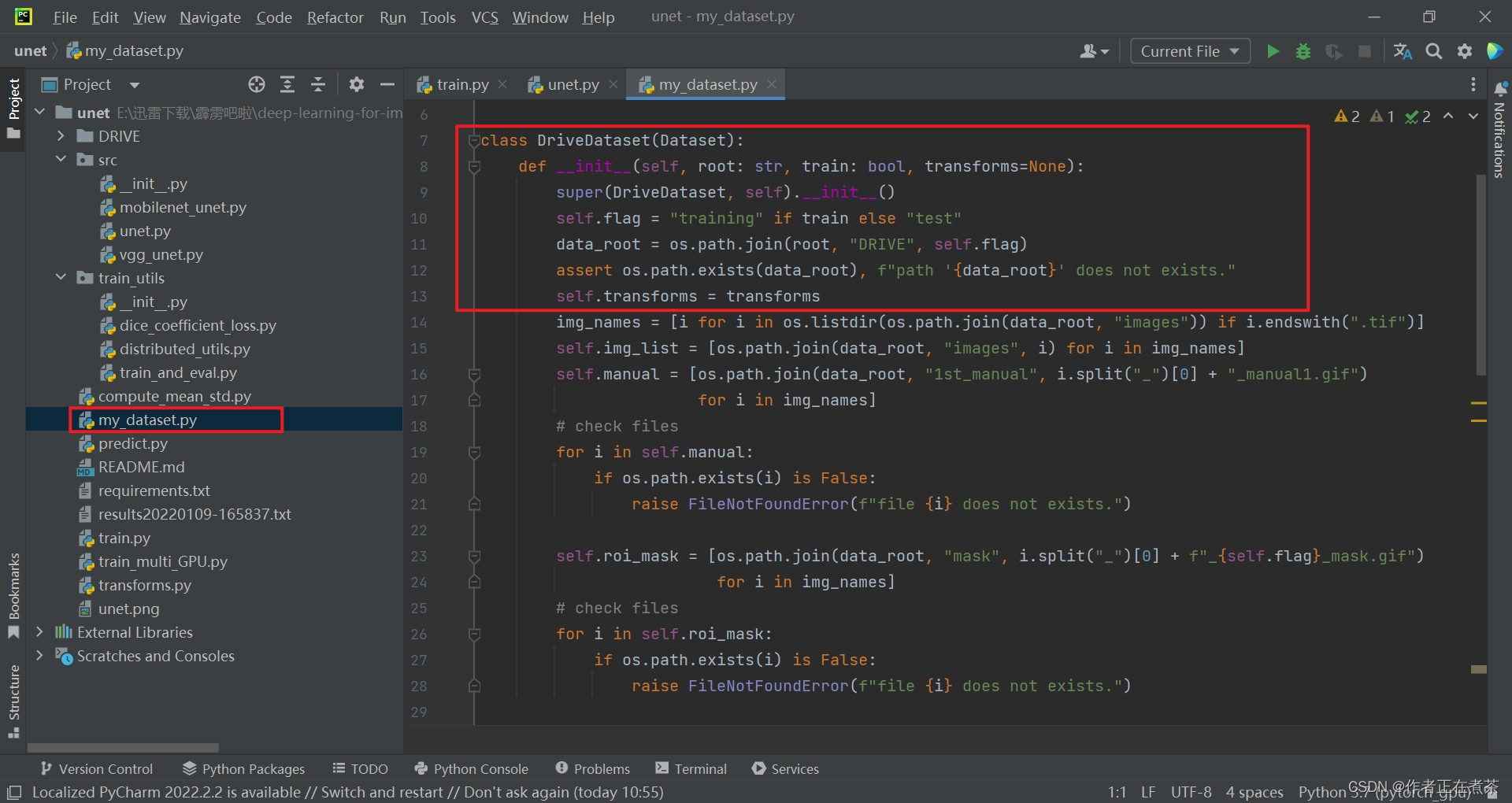
【代码解析1】针对 DriveDataset 类代码的具体解析(结合上图):
- 传入 train 参数来定义 self.flag ,如果 train 为 True 则 self.flag 为 training ,如果 train 为 False 则 self.flag 为 test
- 再将 root ," DRIVE " 和 self.flag 进行 路径拼接 ,从而得到 数据集的路径
- 检查数据集路径是否存在,如果不存在则抛出异常
- 将传入的 transforms 赋值给实例变量 self.transforms
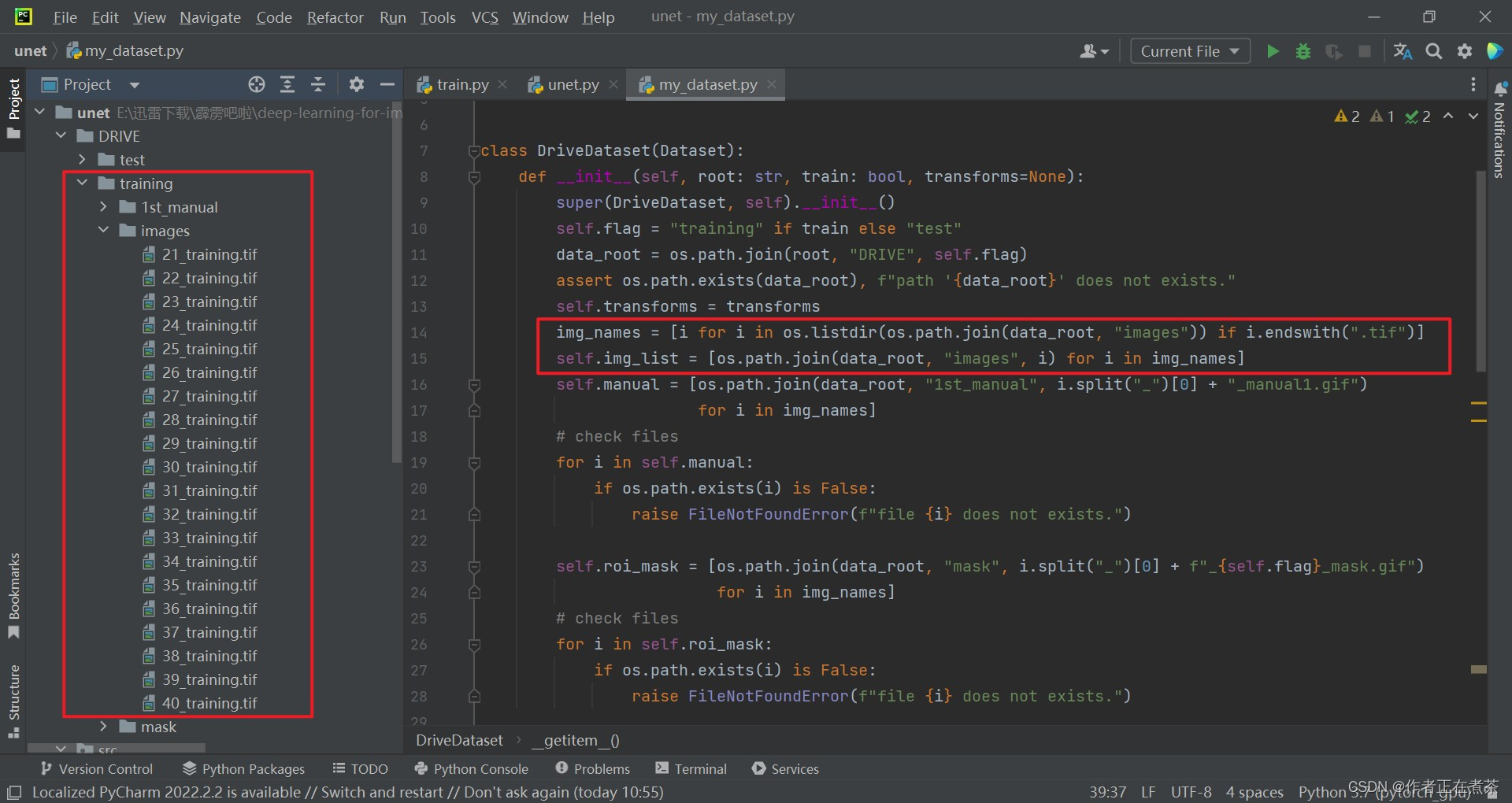
【代码解析2】针对 DriveDataset 类代码的具体解析(结合上图):
- 通过 os.listdir 遍历 data_root 下的 images 目录,保留 以 .tif 结尾 的文件,从而得到 images 目录下所有图片名称 img_names
- 遍历 img_names ,再将 data_root ," images " 和图片名称进行 路径拼接 ,从而得到 每张图片所对应的路径
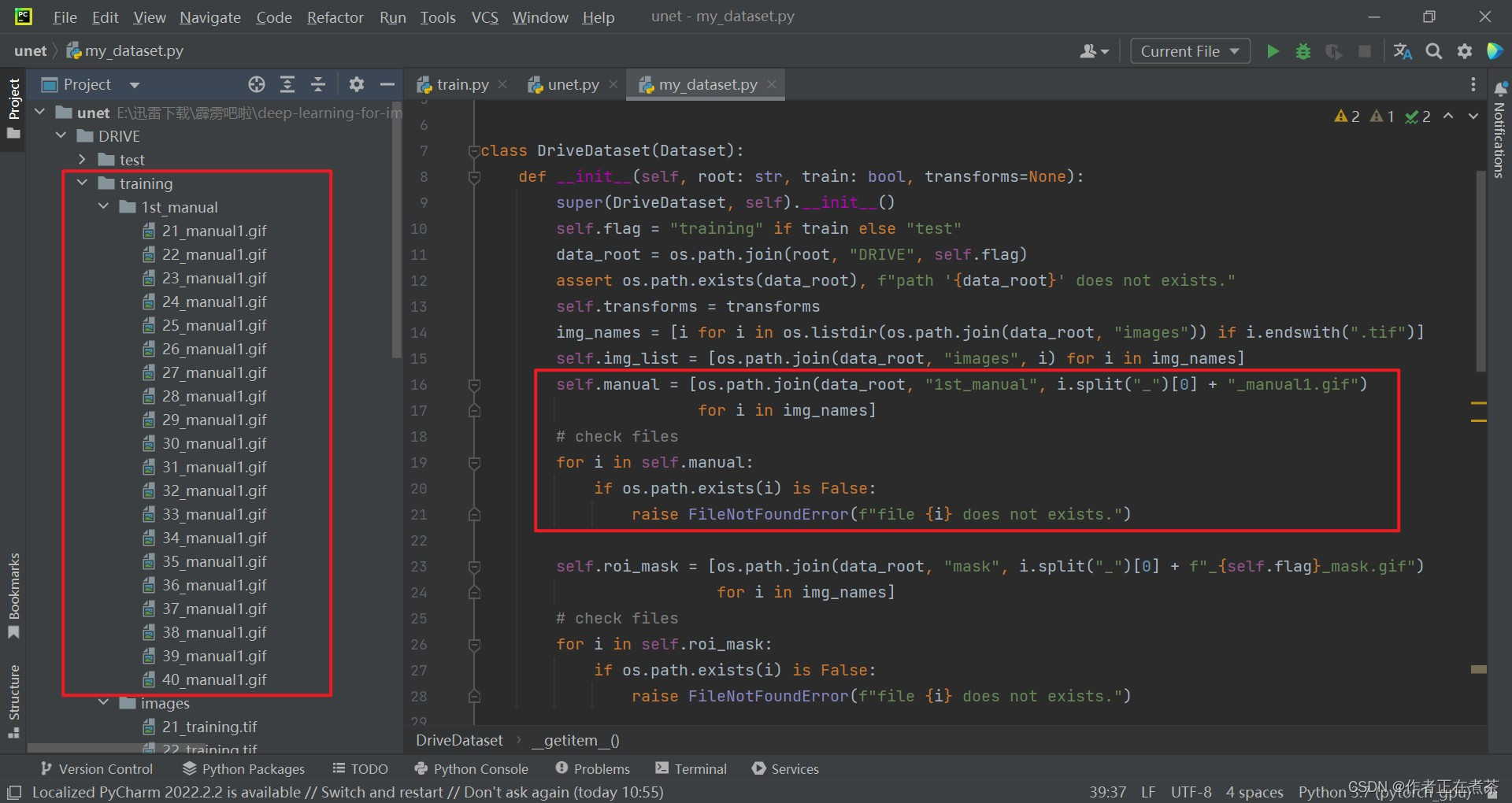
【代码解析3】针对 DriveDataset 类代码的具体解析(结合上图):对比 1st_manual 目录和 images 目录下的图片名称,可以发现二者的开头序号相同,因此可以用 spilt ("_") [0] 的方式提取 img_names 的开头序号,并在后面加上 " _manual1.gif " 得到 1st_manual 目录下的图片名称 ,再通过路径拼接得到对应的图片路径。然后循环遍历 self.manual ,确认 self.manual 中的图片是否都存在,若不存在则报错 FileNotFoundError 。
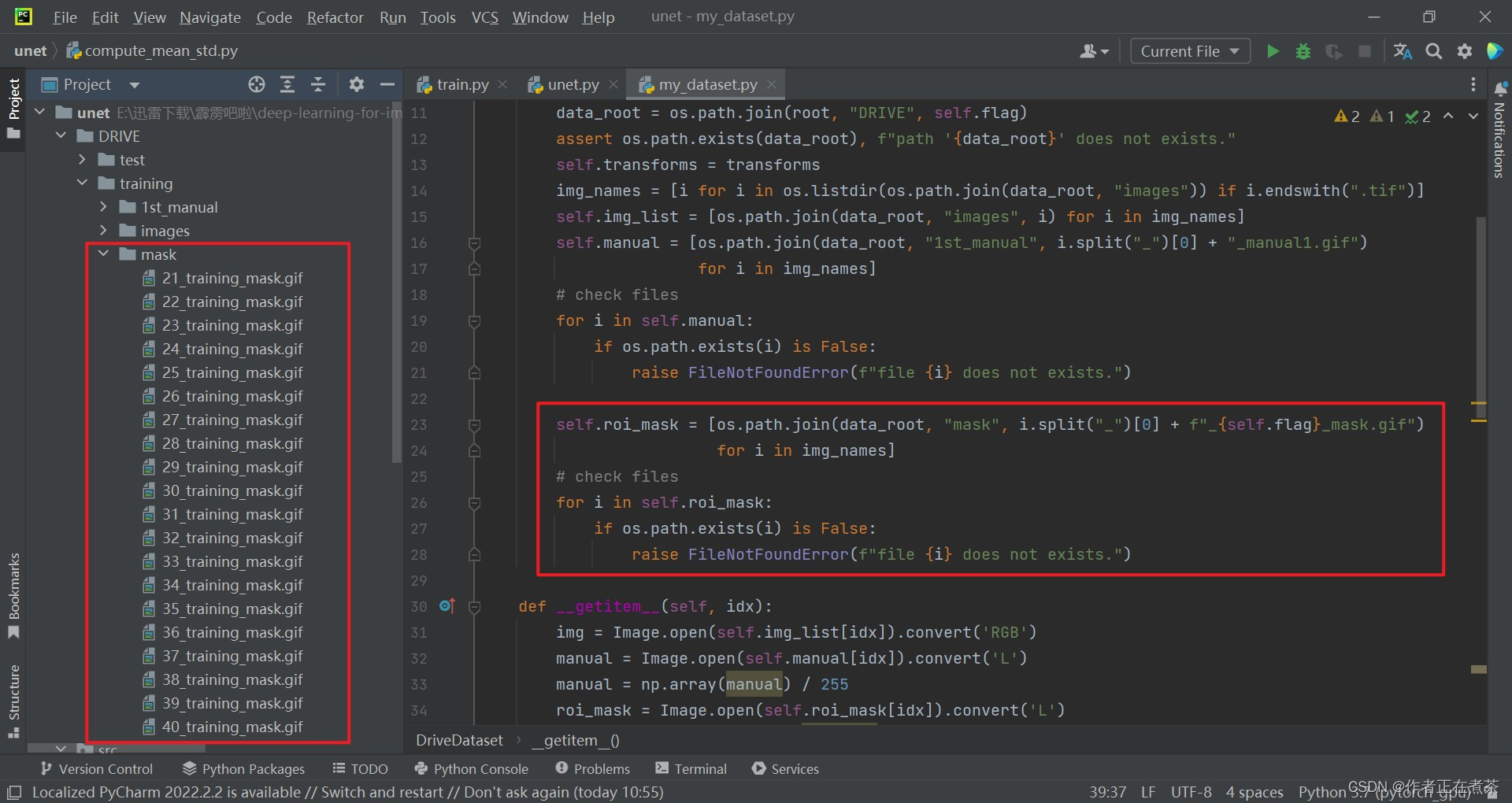
【代码解析4】针对 DriveDataset 类代码的具体解析(结合上图):同上面的 1st_manual ,得到 mask 目录下的图片路径。
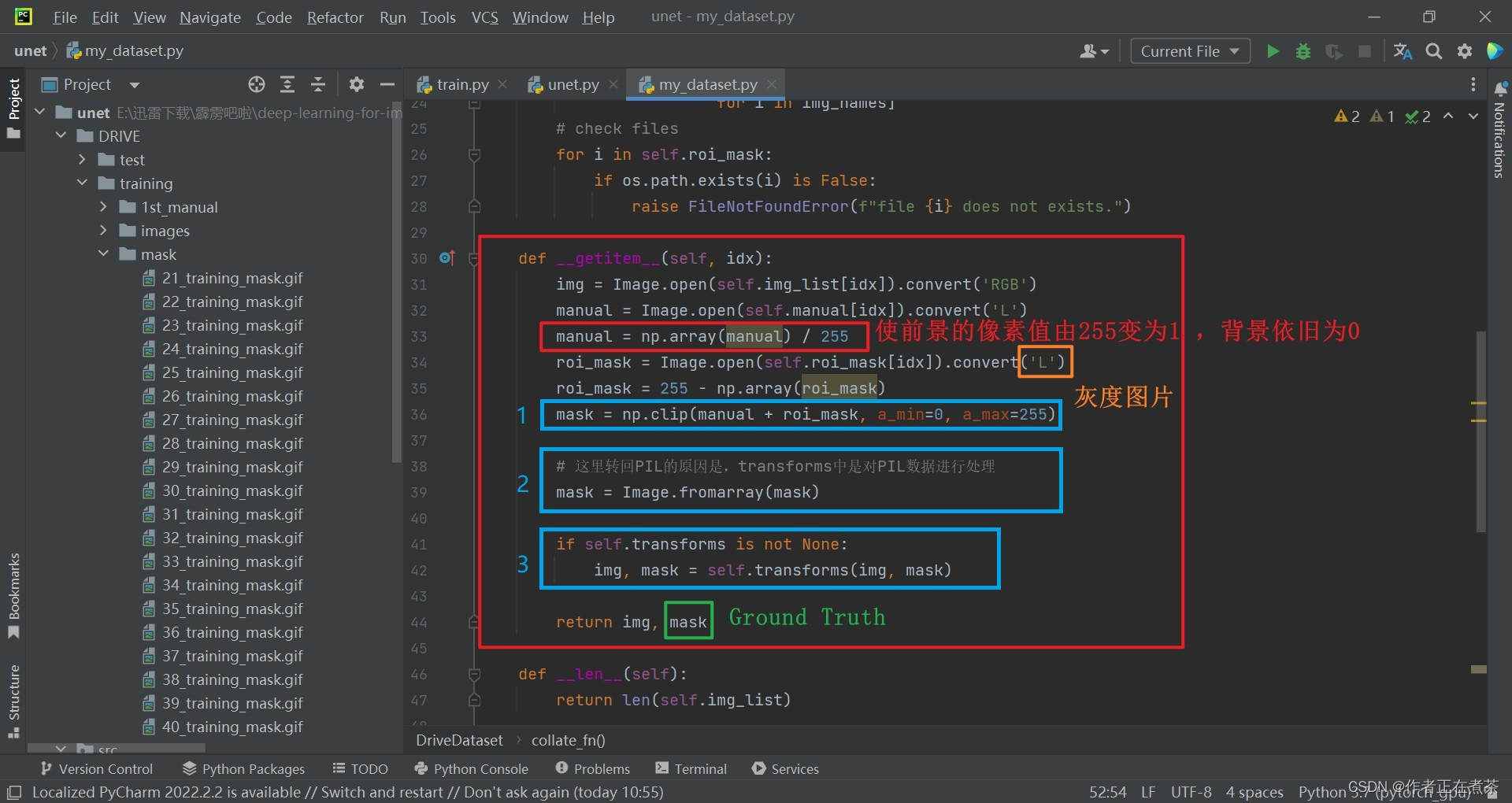
【代码解析5】针对 DriveDataset 类代码的具体解析(结合上图):
- 将 manual 和 roi_mask 相加后用 np.clip 方法为其设置上下限,得到的 mask 对应前景区域是 1 ,背景区域是 0 ,不感兴趣的区域是 255
- 因为在 transforms 中定义的一系列预处理方法,基本上都是针对 PIL 的数据进行处理,因此需要将 mask 转成 PIL 图片的格式
- 若 transforms 不为 None 的话,就将图片和 mask 传入到 transforms 中,进行相应的预处理,得到对应的图片和 mask ,最后 return
Question:为什么要做 roi_mask = 255 - np.array(roi_mask) 处理?
回答:这样处理后,感兴趣区域的像素值变为 0 ,不感兴趣区域的像素值变为 255 ,计算损失时就可以将不感兴趣的像素都忽略掉。
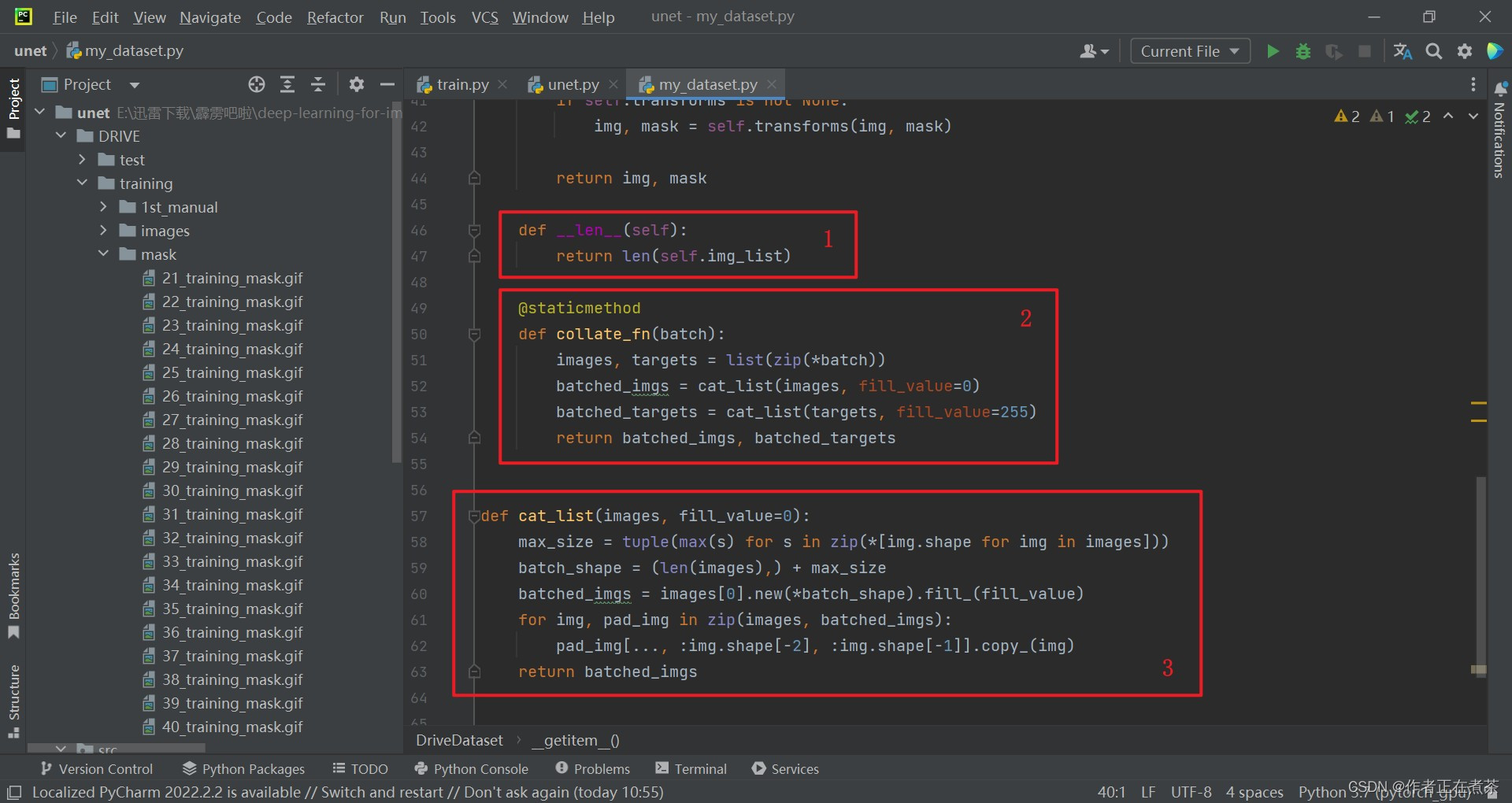
【代码解析6】针对 DriveDataset 类代码的具体解析(结合上图):
- 这个 __len__ 函数用于返回图像列表 self.img_list 的长度,也就是数据集中图像的数量
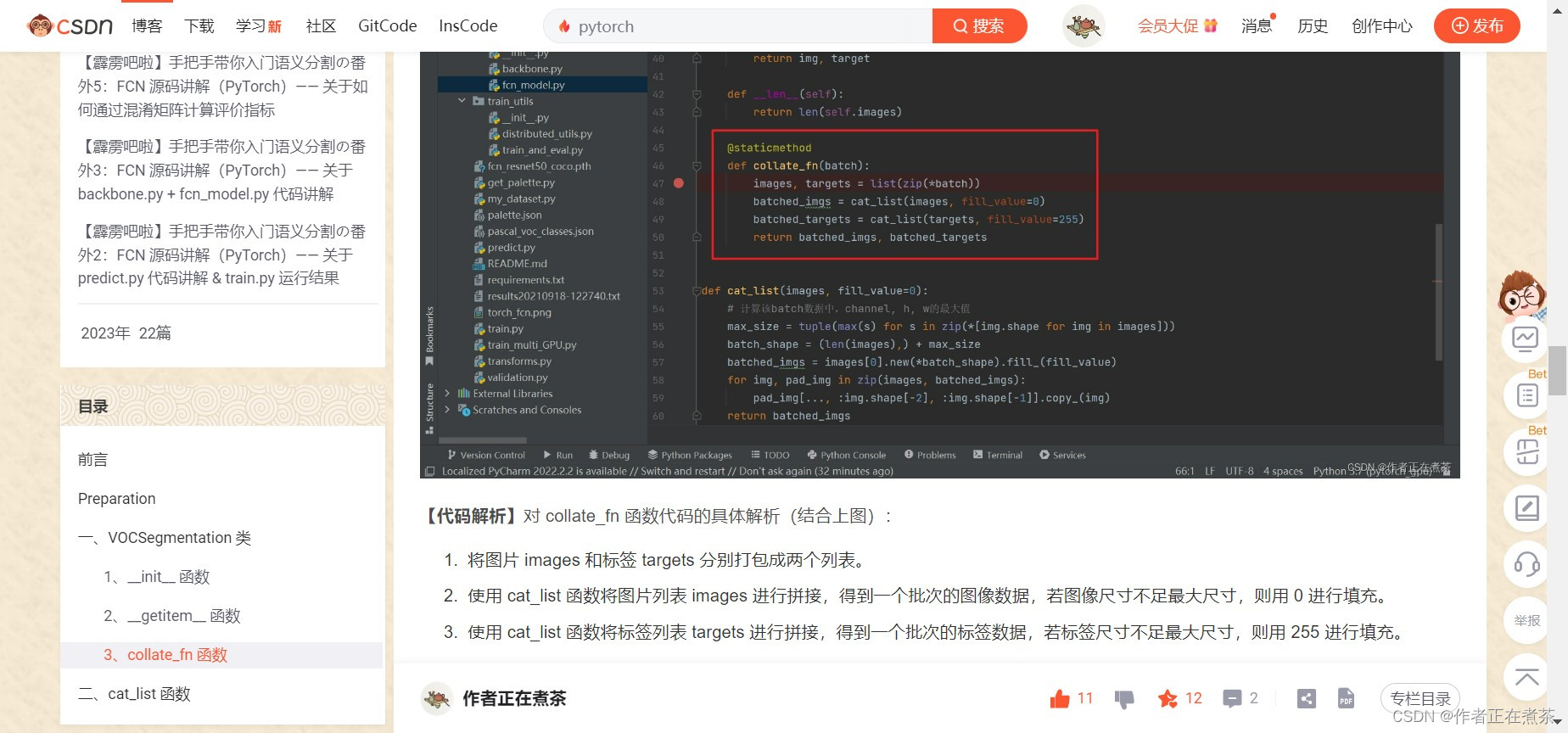
- 这个 collate_fn 函数在讲解 FCN 源码时有详细讲解过,就是将我们一张张图片以及我们的 target 打包成一个 batch
- 这个 cat_list 函数用于将一组大小不同的图片按照最大尺寸进行填充后拼接在一起
【补充】针对上面第二条,微臣将讲解了 collate_fn 函数的文章链接贴在下面啦:
2、my_dataset.py 源码
import os
from PIL import Image
import numpy as np
from torch.utils.data import Dataset
class DriveDataset(Dataset):
def __init__(self, root: str, train: bool, transforms=None):
super(DriveDataset, self).__init__()
self.flag = "training" if train else "test"
data_root = os.path.join(root, "DRIVE", self.flag)
assert os.path.exists(data_root), f"path '{data_root}' does not exists."
self.transforms = transforms
img_names = [i for i in os.listdir(os.path.join(data_root, "images")) if i.endswith(".tif")]
self.img_list = [os.path.join(data_root, "images", i) for i in img_names]
self.manual = [os.path.join(data_root, "1st_manual", i.split("_")[0] + "_manual1.gif")
for i in img_names]
# check files
for i in self.manual:
if os.path.exists(i) is False:
raise FileNotFoundError(f"file {i} does not exists.")
self.roi_mask = [os.path.join(data_root, "mask", i.split("_")[0] + f"_{self.flag}_mask.gif")
for i in img_names]
# check files
for i in self.roi_mask:
if os.path.exists(i) is False:
raise FileNotFoundError(f"file {i} does not exists.")
def __getitem__(self, idx):
img = Image.open(self.img_list[idx]).convert('RGB')
manual = Image.open(self.manual[idx]).convert('L')
manual = np.array(manual) / 255
roi_mask = Image.open(self.roi_mask[idx]).convert('L')
roi_mask = 255 - np.array(roi_mask)
mask = np.clip(manual + roi_mask, a_min=0, a_max=255)
# 这里转回PIL的原因是,transforms中是对PIL数据进行处理
mask = Image.fromarray(mask)
if self.transforms is not None:
img, mask = self.transforms(img, mask)
return img, mask
def __len__(self):
return len(self.img_list)
@staticmethod
def collate_fn(batch):
images, targets = list(zip(*batch))
batched_imgs = cat_list(images, fill_value=0)
batched_targets = cat_list(targets, fill_value=255)
return batched_imgs, batched_targets
def cat_list(images, fill_value=0):
max_size = tuple(max(s) for s in zip(*[img.shape for img in images]))
batch_shape = (len(images),) + max_size
batched_imgs = images[0].new(*batch_shape).fill_(fill_value)
for img, pad_img in zip(images, batched_imgs):
pad_img[..., :img.shape[-2], :img.shape[-1]].copy_(img)
return batched_imgs















 922
922











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











