






01
引言
神经网络一开始是为了研究人脑图并了解人类如何做出决策,而算法试图从交易方面消除人类情绪的影响。我们有时没有意识到的是,人脑很可能是这个世界上最复杂的机器,并且众所周知,它可以非常有效地在创纪录的时间内得出结论。
想想看,如果我们能够利用我们大脑的工作方式并将其应用到机器学习领域(神经网络毕竟是机器学习的一个子集),我们可能会在处理能力和计算资源方面取得巨大飞跃。
在深入了解神经网络交易的本质之前,我们应该了解主要组件(即神经元)的工作原理。因此,本文试图从以下方面为大家解读神经网络及其在交易策略中的应用:神经元的结构(Structure of a Neuron)、感知器:计算机神经元(Perceptron: the Computer Neuron)、了解神经网络(Understanding a Neural Network)、交易中的神经网络(Neural Network In Trading)、训练神经网络(Training the Neural Network)、梯度下降(Gradient Descent)、反向传播(Backpropagation)、神经网络交易策略。通过学习本文,可以让读者们了解神经网络中涉及的概念以及如何将它们应用于预测实时市场中的股票价格。
02
神经网络简介
01 神经元结构
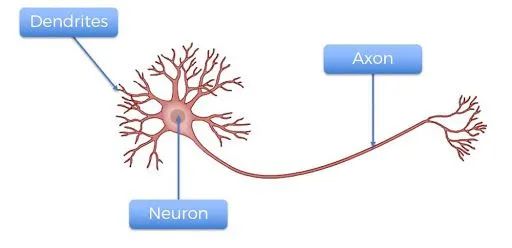
下面我们先来了解一下什么是神经元。神经元由树突(Dendrites)、轴突(Axon)和神经元主体(Neuron)三个部分组成(如下图所示)。树突是信号的接收器,轴突是发射器。单独一个神经元并没有多大用处,但当它与其他神经元连接时,它会进行一些复杂的计算,并帮助操作我们星球上最复杂的机器——人体。
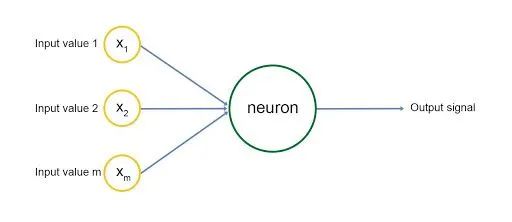
02 感知器:计算机神经元
感知器(即计算机神经元)以类似的方式构建,如下图所示。神经元有输入(input),用黄色圆圈标记,即图中的输入值X1、X2、X3,神经元经过一系列计算后发出输出信号(Output signal)。输入层类似于神经元的树突,输出信号是轴突。每个输入信号都分配了一个权重。
这个权重乘以输入值,神经元(neuron)存储所有输入变量的加权和。这些权重是在神经网络学习的训练阶段通过称为梯度下降(gradient descent)和反向传播(backpropagation)的概念计算出来的,我们稍后将介绍这些概念。然后将激活函数应用于加权和,从而产生神经元的输出信号。输入信号由其他神经元生成,即其他神经元的输出,并且构建网络以这种方式进行预测和计算。
这是神经网络的基本思想。下面将分别介绍神经网络中涉及到的重要概念。
03 了解神经网络
我们将通过一个示例来了解神经网络的工作原理。输入层由有助于我们得出输出值或进行预测的参数组成。我们的大脑基本上有五个基本的输入参数,它们是我们的触觉、听觉、视觉、嗅觉和味觉。
我们大脑中的神经元根据这些基本输入参数创建更复杂的参数,例如情绪和感觉。而我们的情绪和感觉,使我们采取行动或做出决定,这基本上是我们大脑神经网络的输出。因此,在这种情况下,在做出决定之前有两层计算。
第一层将五种感官作为输入并产生情绪和感觉,它们是下一层计算的输入,其中输出是决策或动作。
因此,在这个极其简单的人脑工作模型中,我们有一个输入层、两个隐藏层和一个输出层。当然,从我们的经验来看,我们都知道大脑比这复杂得多,但本质上这就是我们大脑中进行计算的方式。
03
交易中的神经网络
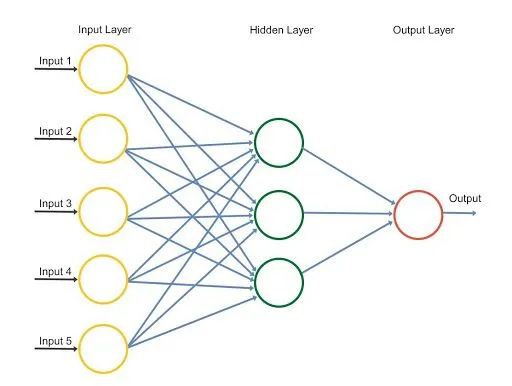
为了理解神经网络在交易中的工作,让我们考虑一个简单的股票价格预测示例,其中 OHLCV(开盘价、最高价、最低价、收盘价)值是输入参数,有一个隐藏层,输出包括对股票价格的预测。如下图所示,交易中的神经网络输入层(Input Layer,黄色圆圈)有五个输入参数(Input 1、Input 2、Input 3、Input 4、Input 5)。隐藏层(Hidden Layer)由 3 个神经元组成(图中绿色圆圈),输出层(Output Layer,红色圆圈)的结果是对股票价格的预测。
隐藏层中的 3 个神经元对五个输入参数中的每一个都有不同的权重(Weights),并且可能具有不同的激活函数(activation functions),这将根据输入的各种组合激活输入参数。例如,第一个神经元可能正在查看成交量以及收盘价和开盘价之间的差异,并且可能会忽略最高价和最低价。在这种情况下,最高价和最低价的权重将为零。基于模型训练获得的权重,一个激活函数将被应用到神经元的加权和上,这将产生特定神经元的输出值。
类似地,其他两个神经元将根据它们各自的激活函数和权重产生一个输出值。最后,股票价格的输出值或预测值将是每个神经元的三个输出值之和。这就是神经网络预测股票价格的方式。
现在你已经理解了神经网络的工作原理,我们将进入神经网络的核心内容,即学习人工神经网络如何通过自我学习(train itself)来预测股票价格的走势。
01 训练神经网络
为了简化神经网络,有两种方法可以编写程序来执行特定任务。
定义程序所需的所有规则,以计算给程序一些输入的结果。
开发一个框架,在这个框架上,代码将学习执行特定的任务,方法是在一个数据集上训练自己,调整计算结果,使其尽可能接近观察到的实际结果。
第二个过程称为训练模型,这是我们将重点关注的。下面让我们看看神经网络将如何训练自己来预测股票价格。神经网络将获得数据集,该数据集由 OHLCV 数据作为输入和输出组成,我们还将为模型提供第二天的收盘价,这是我们希望模型通过学习后进行预测的值。输出的实际值将由y表示,预测值将由y^表示。模型的训练涉及调整神经网络中存在的所有不同神经元的变量权重。这是通过最小化“成本函数”来完成的。顾名思义,成本函数是使用神经网络进行预测的成本。它是对预测值y^与实际值或观察值 y 相差多大的度量。实践中有许多成本函数可以使用,最常用的是计算训练数据集的实际值和预测值之间的平方差之和的一半。
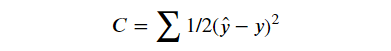
神经网络训练自己的方式是首先为给定的神经元权重集计算训练数据集的成本函数。然后它返回并调整权重,然后根据新的权重计算训练数据集的成本函数。将错误发送回网络以调整权重的过程称为反向传播。这会重复几次,直到成本函数最小化。
接下来,我们将更详细地研究如何调整权重和最小化成本函数。调整权重以最小化成本函数。一种方法是通过蛮力。假设我们为权重取 1000 个值,并评估这些值的成本函数。当我们绘制成本函数图时,我们将得到如下图所示的图形。权重的最佳值将是与该图的最小值相对应的成本函数。
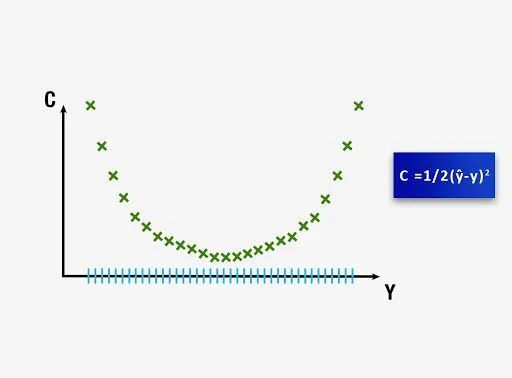
对于涉及需要优化的单个权重的神经网络,这种方法可能是成功的。然而,随着要调整的权重数量和隐藏层数量的增加,所需的计算量将急剧增加。即使在世界上最快的超级计算机上,训练这样一个模型所需的时间也将非常长。因此,必须开发一种更好、更快的方法来计算神经网络的权重。这个过程称为梯度下降(Gradient Descent)。下文将深入介绍这个概念。
02 梯度下降
梯度下降涉及分析成本函数曲线的斜率。我们根据斜率调整权重,以逐步最小化成本函数,而不是计算所有可能组合的值。
梯度下降的可视化如下图所示。第一个图是权重的单个值,因此是二维的。可以看出,红球以之字形移动以达到成本函数的最小值。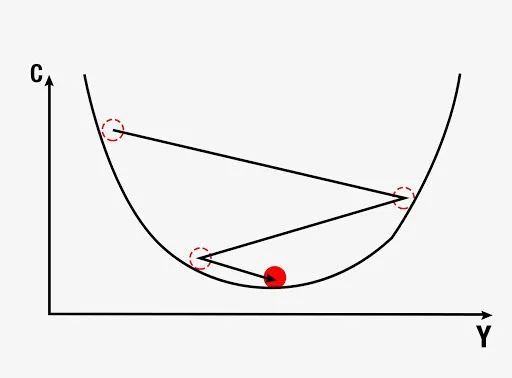
在第二张图中,我们必须调整两个权重以最小化成本函数。因此,我们可以将其可视化为等高线,如图所示,我们正朝着最陡坡的方向移动,以便在最短的时间内达到最小值。使用这种方法,我们不必进行很多计算,因此计算时间不会很长,使模型的训练成为一项可行的任务。
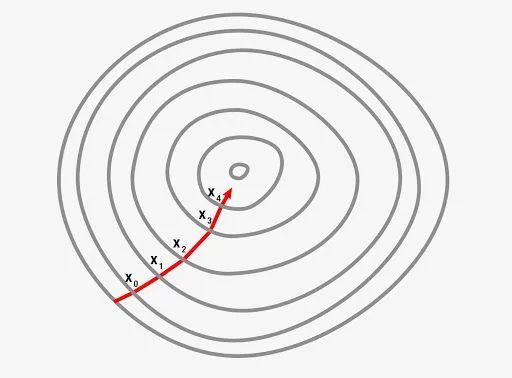
梯度下降可以通过三种可能的方式完成,
批量梯度下降(batch gradient descent)
随机梯度下降(stochastic gradient descent)
小批量梯度下降(mini-batch gradient descent)
在批量梯度下降中,成本函数是通过对训练数据集中的所有单个成本函数求和,然后计算斜率并调整权重来计算的。
在随机梯度下降中,成本函数的斜率和权重的调整是在训练数据集中的每个数据输入之后完成的。如果成本函数的曲线不是严格凸的,这对于避免陷入局部最小值非常有用。每次运行随机梯度下降时,到达全局最小值的过程都会有所不同。如果批量梯度下降在局部最小值处停止,它可能会导致陷入次优结果。
第三种是小批量梯度下降,它是批量和随机方法的结合。在这里,我们通过将一批中的多个数据组合在一起来创建不同的批次。这实质上导致在训练数据集中的大批量数据上实现随机梯度下降。
03 反向传播
反向传播是一种高级算法,它使我们能够同时更新神经网络中的所有权重。这大大降低了调整权重的过程的复杂性。如果我们不使用该算法,我们将不得不通过计算特定权重对预测误差的影响来单独调整每个权重。让我们看一下使用随机梯度下降训练神经网络所涉及的步骤:
将权重初始化为非常接近 0(但不是 0)的小数字
前向传播 - 通过使用我们训练数据集中的第一个数据,从左到右激活神经元,直到我们得到预测结果
测量将产生的误差
反向传播——产生的误差会从右向左反向传播,根据学习率调整权重
在整个训练数据集上重复前三个步骤,前向传播、误差计算和反向传播
这将标志着第一个操作的结束,后续的操作将从之前得到的权重值开始,当成本函数收敛在某个可接受的范围内时,我们可以停止这个过程
我们在这个神经网络的介绍中涵盖了很多内容,这引导我们在实践中应用这些概念。接着我们将学习如何开发我们自己的人工神经网络来预测股票价格的走势。
04
策略应用
导入数据训练和测试模型可能用到的库。
import numpy as np
import pandas as pd
import talib将随机种子设置为固定数(注意挂号中的数字只有标记作用,本身无意义),以便每次运行代码时都从相同的种子开始。
import random
random.seed(2022)导入数据集
原文使用pandas本地导入美股数据,本文则使用tushare获取上证综指2000年至2021年的行情交易数据(开盘、最高、最低、收盘)作为分析样本。
import tushare as ts
df=ts.get_k_data('sh',start='2000-01-01',end='2021-12-31')
df.index=pd.to_datetime(df.date)
cols=['Open', 'High', 'Low', 'Close']
dataset=df[['open','high','low','close']]
dataset=dataset.rename(columns=dict(zip(dataset.columns,cols)))
dataset.head()01 数据预处理
数据初始数据构建其他输入特征,人工神经网络学习将使用这些特征进行预测。我们定义了以下输入特征:
最高价与最低价之差(H-L)
收盘价减去开盘价(O-C)
三天移动平均线(3day MA)
十日均线(10day MA)
30天移动平均线(30day MA)
5天的标准差(Std_dev)
技术指标:相对强弱指数(RSI)
技术指标:威廉姆斯 %R
dataset['H-L'] = dataset['High'] - dataset['Low']
dataset['O-C'] = dataset['Close'] - dataset['Open']
dataset['3day MA'] = dataset['Close'].shift(1).rolling(window = 3).mean()
dataset['10day MA'] = dataset['Close'].shift(1).rolling(window = 10).mean()
dataset['30day MA'] = dataset['Close'].shift(1).rolling(window = 30).mean()
dataset['Std_dev']= dataset['Close'].rolling(5).std()
dataset['RSI'] = talib.RSI(dataset['Close'].values, timeperiod = 9)
dataset['Williams %R'] = talib.WILLR(dataset['High'].values, dataset['Low'].values, dataset['Close'].values, 7)然后我们将输出值定义为价格上涨,它是一个二进制变量,当明天的收盘价大于今天的收盘价时赋值1。
dataset['Price_Rise'] = np.where(dataset['Close'].shift(-1) > dataset['Close'], 1, 0)
#删除缺失值
dataset = dataset.dropna()#查看最后五列数据
dataset.tail()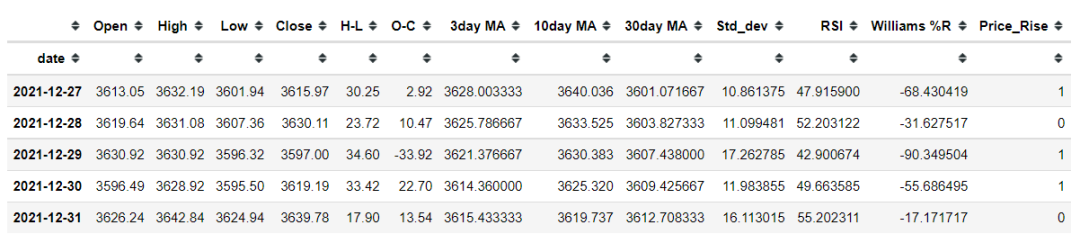
接着创建两个数据框来存储输入和输出变量。数据框“X”存储输入特征,从数据集的第五列(或索引 4)开始到倒数第二列的列。最后一列将存储在数据框 y 中,这是我们要预测的值,即价格的涨跌。
X = dataset.iloc[:, 4:-1]
y = dataset.iloc[:, -1]数据集分拆
在这部分代码中,我们将拆分输入和输出变量以创建测试和训练数据集。这是通过创建一个名为 split 的变量来完成的,该变量被定义为数据集长度的 0.8 倍的整数值。然后,我们将 X 和 y 变量分成四个单独的数据集:Xtrain、Xtest、ytrain 和 ytest。这是任何机器学习算法的重要组成部分,模型使用训练数据来获得模型的权重。测试数据集用于查看模型将如何处理将被输入模型的新数据。测试数据集还具有输出的实际值,这有助于我们了解模型的效率。我们将在后面的代码中查看混淆矩阵(confusion matrix),它本质上是衡量模型做出的预测有多准确的指标。
split = int(len(dataset)*0.8)
X_train, X_test, y_train, y_test = X[:split], X[split:], y[:split], y[split:]特征缩放(Feature Scaling)
数据预处理的另一个重要步骤是标准化数据集。此过程使所有输入特征的均值为零,并将它们的方差转换为 1。这确保了在训练模型时由于所有输入特征的不同尺度而没有偏差。如果不这样做,神经网络可能会感到困惑,并为那些平均值高于其他特征的特征赋予更高的权重。
通过从sklearn.preprocessing 库中导入 StandardScaler方法来实现这一步。使用 StandardScaler() 函数实例化变量sc之后,使用 fittransform 函数在 Xtrain 和 Xtest 数据集上实现这些更改。ytrain 和 y_test 集包含二进制值,因此它们不需要标准化。现在数据集已经准备好了,我们可以继续使用 Keras 库构建人工神经网络。
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)02 构建神经网络
现在我们将导入用于构建人工神经网络的函数。我们从 keras.models 库中导入 Sequential 方法。这将用于顺序构建神经网络学习的层。我们导入的下一个方法将是 keras.layers 库中的 Dense 函数。
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout将 Sequential() 函数实例化为变量分类器。然后,此变量将用于在 python 中构建人工神经网络学习的层。
classifier = Sequential()使用 add() 函数将层添加到我们的分类器中。add 函数的参数是 Dense() 函数,该函数又具有以下参数:
Units: 定义了该特定层中的节点或神经元的数量。我们将此值设置为 128,这意味着我们的隐藏层中将有 128 个神经元。
Kernel_initializer:这定义了隐藏层中不同神经元权重的起始值。我们将其定义为“均匀”,这意味着权重将使用来自均匀分布的值进行初始化。
Activation:这是特定隐藏层中神经元的激活函数。在这里,将函数定义为单元函数或“relu”。
Input_dim:定义隐藏层的输入数量,将此值定义为等于输入特征数据集的列数。后续层不需要此参数,因为模型将知道前一层产生了多少输出。
classifier.add(Dense(units = 128, kernel_initializer = 'uniform', activation = 'relu', input_dim = X.shape[1]))然后我们添加第二层,有 128 个神经元,具有统一的内核初始化器和“relu”作为其激活函数。我们只在这个神经网络中构建了两个隐藏层。我们构建的下一层将是输出层,我们需要一个输出层。因此,传递的单位为 1,激活函数选择为 Sigmoid 函数,因为我们希望预测是市场向上移动的概率。
classifier.add(Dense(units = 1, kernel_initializer = 'uniform', activation = 'sigmoid'))最后,我们通过传递以下参数来编译分类器:
Optimizer(优化器):优化器被选为“adam”,它是随机梯度下降的扩展。
Loss(损失函数):这定义了在训练期间要优化的损失。我们将此损失定义为均方误差。
Metrics(指标):这定义了模型在测试和训练阶段要评估的指标列表。我们选择准确性作为我们的评估指标。
classifier.compile(optimizer = 'adam', loss = 'mean_squared_error', metrics = ['accuracy'])现在需要将我们创建的神经网络拟合到训练数据集。通过在 fit() 函数中传递 Xtrain、ytrain、batch size和 epoch 数来完成的。batch size是指模型在反向传播误差和修改权重之前用于计算误差的数据点的数量。epoch 数表示模型训练将在训练数据集上执行的次数。有了这个,我们在 Python 中的人工神经网络已经编译完毕,可以进行预测了。
classifier.fit(X_train, y_train, batch_size = 10, epochs = 100)03 预测股票走势
现在神经网络已经编译好了,可以使用 predict() 方法进行预测。将 Xtest 作为其参数传递,并将结果存储在名为 ypred 的变量中。然后,通过存储条件 ypred > 5 将 ypred 转换为存储二进制值。现在,变量 y_pred 存储 True 或 False,具体取决于预测值是大于还是小于 0.5。
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5)接下来,在dataframe数据集中创建一个新列,列标题为“ypred”,并将 NaN 值存储在列中。然后将 ypred 的值存储到这个新列中,从测试数据集的行开始。这是通过使用 iloc 方法对数据集进行切片来完成的,如下面的代码所示。然后,我们从数据集中删除所有 NaN 值,并将它们存储在名为 trade_dataset 的新数据框中。
dataset['y_pred'] = np.NaN
dataset.iloc[(len(dataset) - len(y_pred)):,-1:] = y_pred
trade_dataset = dataset.dropna()04 计算策略收益
现在我们有了股票走势的预测值。可以计算策略的回报。当 y 的预测值为真时,我们将持有多头头寸,而当预测信号为假时,我们将持有空头头寸。
首先计算如果在今天结束时持有多头头寸并在第二天结束时平仓,该策略将获得的回报。先在 trade_dataset 中创建一个名为“Tomorrows Returns”的新列,并在其中存储一个值 0。我们使用十进制表示法表示浮点值将存储在这个新列中。接下来,将今天的对数收益存储在其中,即今天收盘价除以昨天收盘价的对数。接下来,将这些值向上移动一个元素,以便将明天的收益与今天的价格相比较。
import warnings
warnings.filterwarnings('ignore')trade_dataset['Tomorrows Returns'] = 0.
trade_dataset['Tomorrows Returns'] = np.log(trade_dataset['Close']/trade_dataset['Close'].shift(1))
trade_dataset['Tomorrows Returns'] = trade_dataset['Tomorrows Returns'].shift(-1)接下来,我们将计算策略回报。我们创建一个列名为“StrategyReturns”的新列,并将其初始化为 0。以指示存储浮点值。通过使用 np.where() 函数,如果 'ypred' 列中的值存储 True(多头头寸),我们将值存储在列 'Tomorrows Returns' 中,否则我们将在列中存储负值 'Tomorrows Returns'(空头头寸)。
trade_dataset['Strategy Returns'] = 0.
trade_dataset['Strategy Returns'] = np.where(trade_dataset['y_pred'] == True,
trade_dataset['Tomorrows Returns'], - trade_dataset['Tomorrows Returns'])现在计算市场和策略的累积回报,这些值是使用 cumsum() 函数计算的。在最后一步中,我们将使用累积和来绘制市场和策略收益图。
trade_dataset['Cumulative Market Returns'] = np.cumsum(trade_dataset['Tomorrows Returns'])
trade_dataset['Cumulative Strategy Returns'] = np.cumsum(trade_dataset['Strategy Returns'])05 收益可视化
下面使用数据trade_dataset 中的累积值绘制市场回报和策略回报曲线,以可视化上述交易策略在市场上的表现。
import matplotlib.pyplot as plt
trade_dataset[['Cumulative Market Returns','Cumulative Strategy Returns']].plot(figsize=(14,8));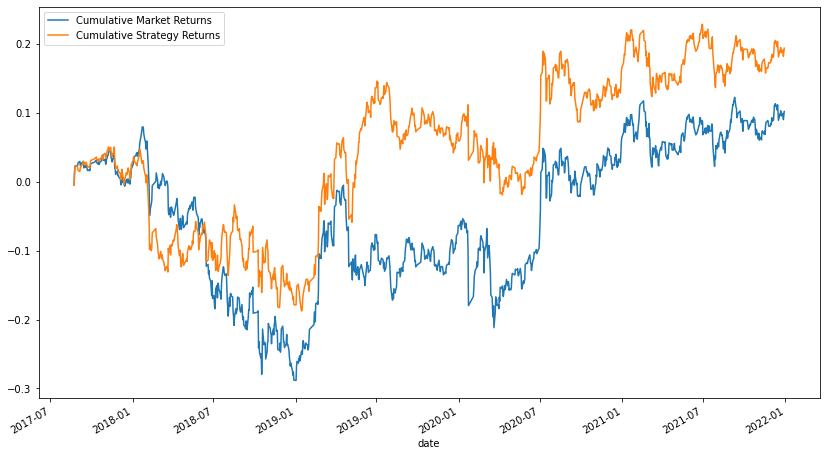
04
结语
到这一步,相信你对神经网络的相关概念已有所了解,并能用 Python 构建自己的人工神经网络进行量化交易。实际上,除了神经网络,还有很多其他机器学习模型可用于交易。当你有超过 100,000 个数据点用于训练模型时,人工神经网络或任何其他深度学习模型将最为有效。本文所用的模型是根据每日价格开发的,旨在让读者了解如何构建模型。建议使用更高频的数据,如分时交易数据来训练模型,这将为你提供足够的数据进行有效的训练。
英文原文:Neural Network In Python: Introduction, Structure And Trading Strategies,By Devang Singh

关于Python金融量化

专注于分享Python在金融量化领域的应用。加入知识星球,可以免费获取30多g的量化投资视频资料、量化金融相关PDF资料、公众号文章Python完整源码、量化投资前沿分析框架,与博主直接交流、结识圈内朋友等。















 653
653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









