







这篇笔记用来描述 2025年 发表在arxiv上的一篇有关 VLA 领域的论文。是一篇关于灵巧手抓取的VLA模型,并创建了一个开源数据集,尽管如此我还是觉得这篇论文内容不够丰满,特别是在模型对比上只和自己进行了消融实验,但文章中的实验却说明了其具备极强的泛化能力。
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 VLA, LLM, VLM 相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:ManipTrans: Efficient Dexterous Bimanual Manipulation Transfer via Residual Learning
- 原文链接: https://arxiv.org/abs/2502.20900
- 发表时间:2025年03月05日
- 发表平台:arxiv
- 预印版本号:[v2] Wed, 5 Mar 2025 16:23:09 UTC (7,171 KB)
- 作者团队:Yifan Zhong, Xuchuan Huang, Ruochong Li, Ceyao Zhang, Yitao Liang, Yaodong Yang, Yuanpei Chen
- 院校机构:
- Institute for AI, Peking University;
- PKU-PsiBot Joint Lab;
- Hong Kong University of Science and Technology (Guangzhou);
- 项目链接: https://dexgraspvla.github.io
- GitHub仓库: https://github.com/Psi-Robot/DexGraspVLA
Abstract
灵巧抓取仍然是机器人技术领域一个基础而又极具挑战性的问题。通用机器人必须能够在任意场景下抓取各种物体。然而,现有研究通常依赖于特定假设,例如单物体设置或有限环境,导致泛化能力受限。作者提出了 DexGraspVLA 一个分层框架,它利用预训练的VL模型作为高级任务规划器,并学习基于扩散的策略作为低级动作控制器。其关键创新在于将各种语言和视觉输入迭代地转换为领域不变的表示,其中由于领域转移的不变性,模仿学习可以得到有效应用,因此能够在广泛的实际场景中实现鲁棒的泛化。该方法在 zero-shot 条件下,面对数千种看未见过的物体、光照和背景组合下实现了 90% 以上的成功率。实证分析进一步证实了内部模型行为在环境变化中的一致性,验证了设计可用性并解释了其泛化性能。演示和代码可在 https://dexgraspvla.github.io/ 找到。
1. Introduction
多指灵巧手作为多功能机器人末端执行器,已在各种操作任务中展现出卓越的能力。在这些能力中,抓取是最基本的前提,但仍然是最具挑战性的问题之一。现有的灵巧抓取方法主要在孤立物体或简化设置下进行评估。然而,现实世界的应用需要更通用的抓取能力,要求能够在工业制造和家庭环境等不同场景中可靠地运行。目前,开发通用的灵巧抓取能力面临着多方面的挑战。在物体级别,策略必须跨各种物理属性进行泛化,包括几何形状、质量、纹理、方向。除了物体特性之外,系统还必须展示对各种环境因素的鲁棒性,例如光照条件、背景复杂性、潜在干扰。除了这些挑战之外,多物体场景还带来了额外的复杂性,需要更复杂的推理能力。例如,在杂乱或堆叠的环境中,规划抓取所有物体的最佳顺序是一项至关重要的认知任务,这种类型任务超越了简单的抓取执行。
传统的灵巧抓取方法遵循两阶段流程:首先根据单帧感知预测目标抓取姿势,然后执行开环运动规划以达到该姿势。然而,此类方法受相机标定和机械精度限制。模仿学习和强化学习等端到端方法通过根据实时感知反馈不断调整动作来实现闭环抓取,提供更稳健、自适应的解决方案。近年来,强化学习在机器人系统应用中取得了显著进展。利用大规模并行模拟,强化学习使机器人能够在仿真环境中接受大量训练,然后将学到的策略部署到现实世界。尽管这种方法取得了一定进展,但现实世界物理参数的复杂性对仿真建模提出了重大挑战,导致仿真与现实之间存在差距。还有学者探索了模仿学习方法来学习操作技能,该方法通过遥操作采集人类演示数据,并利用监督学习直接学习从原始感知输入到机器人控制命令的映射。然而,此类方法往往难以在演示数据之外进行泛化。虽然一般的抓取任务需要应对不同的物体和环境,但采集所有配置的演示样本并不切实际。因此,关键挑战在于如何有效地利用演示数据来实现更广泛的泛化。
VL基础模型的崛起为机器人操作带来了光明前景。通过在预训练中利用海量互联网规模数据,这些模型展示了卓越的场景理解能力以及对视觉和语言输入的泛化能力。为了利用这些能力进行决策,研究人员探索了将视觉和语言基础模型集成到动作生成中,从而开发了VLA模型。虽然一种直观的方式是直接让基础模型生成机器人控制命令,但这种策略存在根本性的限制,训练过程中缺乏物理交互数据导致模型的空间智能有限。另一种方法是以端到端的方式在机器人数据上训练VLM。然而,这种范式通常需要大量手动采集的演示,才能涵盖现实世界的多样性和复杂性。即便如此,这些模型在未见过的场景中性能仍然明显下降,并且仍然需要进一步采集数据并进行微调才能应对新情况。此外,机器人数据集与海量预训练语料库之间的巨大差异会导致灾难性遗忘,损害模型的长程推理能力。有效利用基础模型的世界知识来增强机器人策略的泛化能力仍然具有挑战性。
在本文中,作者提出了 DexGraspVLA 第一个通用灵巧抓取的分层VLA框架,整合了基础模型和模仿学习的互补优势。在高层,利用预训练的 VLM 作为任务规划器,解释和推理语言指令,规划整体抓取任务并提供监督信号。在这些信号和多模态输入的引导下,基于扩散的低层模块化控制器产生闭环动作序列。DexGraspVLA 的精髓在于利用基础模型将不同的视觉和语言输入迭代地转换为领域不变的表示,然后高效地应用基于扩散的模仿学习来捕捉灵巧抓取数据集中的动作分布。因此,训练集之外的新场景不再会导致失败,因为基础模型会将其转化为与训练过程中遇到的场景类似的表示,从而保持在已学习策略的领域内。这种方法将基础模型广泛的世界知识与模仿学习强大的动作建模能力融合在一起,从而在实际应用中实现稳健的泛化性能。
DexGraspVLA 在 zero-shot 环境中测试了 1,287 种看不见的物体、光照和背景组合,在混乱场景中的抓取成功率达到了前所未有的 90.8%。对单物体抓取基准的系统评估表明,DexGraspVLA 的总体成功率达到了 98.6%,比现有的控制器直接从原始视觉输入中学习的基线高出至少 48%。此外,我们的实证分析表明,DexGraspVLA 中的内部表示和注意力图在不同环境中保持一致,从而证实了其框架设计并解释了其性能。实验证实了 DexGraspVLA 可以从少量的单一领域人类演示中有效学习,同时可靠地推广到广泛的现实世界情况,标志着朝着通用灵巧抓取迈出了有希望的一步。
2. Related Work
2.1 Dexterous Grasping
灵巧抓取通常分为以下两类:
- 两阶段方法:首先生成抓取姿势,然后控制灵巧手完成该姿势。主要挑战在于基于视觉观察生成高质量的抓取姿势。当前的方法采用基于样本的、基于优化、基于回归的方法来生成目标抓取姿势,然后进行机器人执行的运动规划。例如,
SpringGrasp使用基于优化的方法对部分观测中的不确定性进行建模,以提高抓取姿势生成的质量;UGG提出了一种基于扩散的方法来统一抓取姿势和物体几何的生成。虽然这些方法受益于解耦的感知和控制以及模拟数据生成,但它们通常缺乏闭环反馈并且对干扰和校准误差敏感。 - 端到端方法:使用模仿学习或强化学习直接建模抓取轨迹。近期一些研究探索了在仿真环境中使用强化学习训练灵巧操作并将其迁移到现实世界。
DexVIP和GRAFF使用CV生成提示,并用强化学习基于这些特征训练策略;DextrAH-G和DextrAH-RGB通过在仿真环境中进行大规模并行训练,展示了其在现实世界中的一定泛化能力。然而,这种对仿真的依赖不可避免地会导致仿真与现实之间的差距,而在现实世界中直接训练则会受到样本效率低下的影响;使用人类示范的模仿学习在复杂任务中表现出了显著的效果,这些方法需要人类遥操作来采集演示数据并直接学习数据集中的分布。虽然这种方法更容易训练,但它限制了它们的泛化能力;SparseDFF和神经注意场探索了如何通过3D提取特征场来增强泛化能力。
2.2. Foundation Models for Robotics
近年来,基于大规模数据集预训练的基础模型取得了显著进展。视觉基础模型(例如 SAM 和 DINO)展现出强大的非分布泛化能力,而包括 GPT-4o 和 Qwen2.5-VL 在内的 VLM 则展现出复杂的多模态推理能力,甚至可以执行游戏中的任务,有效利用这些基础模型已成为机器人研究的一个有前景的方向。
- 一种新颖的方法,如
RT-X、OpenVLA、Pi0等,直接在机器人数据上微调 VLM。然而,这种策略需要大量涵盖各种真实条件的演示才能实现泛化。即使是目前最大的机器人数据集也未能覆盖所有场景;在这些数据集上训练的模型仍然难以领域外达到其已知领域的性能,并且通常需要额外采集数据并针对新环境进行微调。由于机器人操作任务的复杂性和专用数据的稀缺性,这些模型往往会牺牲一些高级推理能力; - 另一类研究以
VoxPoser和Rekep为例,利用 VLM 生成特定于任务的输出,例如特征或约束点,然后可将其与传统的运动规划相结合。虽然这种分层策略通常保留了 VLM 固有的推理能力,但它依赖于足够强大的低级控制器来执行高级命令,因此设计有效的接口至关重要。
作者在本文的工作利用预训练基础模型来生成领域不变的表征,从而促进灵巧抓取策略的学习。通过将现实世界的复杂性转移到基础模型上,可以显著减少所需的演示数据量,同时实现强大的零样本泛化能力。
3. Problem Formulation
模型目标是开发一种基于视觉的控制策略,用于语言引导的灵巧抓取,并将其表述为一个顺序决策问题:
- 首先,提供一个语言指令 l l l 直接指明目标物体(如“抓取玩具”);
- 然后,在每个时间步长 t t t 策略接收腕关节第一视角图像 I t w ∈ R H × W × 3 I^{w}_{t}\in R^{H\times W\times 3} Itw∈RH×W×3 ;一个头部第三视角图像 I t h ∈ R H × W × 3 I^{h}_{t}\in R^{H\times W\times 3} Ith∈RH×W×3(其中 H H H, W W W代表图像的高和宽);机器人本体感知 s t ∈ R 13 s_{t}\in R^{13} st∈R13 包含7个手臂关节角度 s t a r m ∈ R 7 s_{t}^{arm}\in R^{7} starm∈R7、6个手关节角度 s t h a n d ∈ R 6 s_{t}^{hand}\in R^{6} sthand∈R6
- 根据这些观察结果,通过从动作分布中 π ( ⋅ ∣ { I j W } j = 0 t , { I j h } j = 0 t , { s j } j = 0 t , l ) \pi(\cdot|\{I^{W}_{j}\}^{t}_{j=0},\{I^{h}_{j}\}^{t}_{j=0},\{s_{j}\}^{t}_{j=0},l) π(⋅∣{IjW}j=0t,{Ijh}j=0t,{sj}j=0t,l)抽样,机器人做出一个动作 a t = ( a t a r m , a t h a n d ) ∈ R 13 a_{t}=(a_{t}^{arm}, a_{t}^{hand})\in R^{13} at=(atarm,athand)∈R13,其中 a t a r m ∈ R 7 , a t h a n d ∈ R 6 a_{t}^{arm}\in R^{7}, a_{t}^{hand}\in R^{6} atarm∈R7,athand∈R6 表示目标手臂关节与手部关节角度;
- 持续执行上面3步直至达到终止条件。机器人将收到一个二进制奖励 r ∈ { 0 , 1 } r\in\{0,1\} r∈{0,1},指示其是否成功完成指令。策略 π \pi π 的目标是最大化预期奖励 E l , { I j w , I j h , s j , a j } j = 0 T [ r ] E_{l,\{I^{w}_{j},I^{h}_{j},s_{j},a_{j}\}^{T}_{j=0}}[r] El,{Ijw,Ijh,sj,aj}j=0T[r];
不失一般性,考虑用户提示 p p p 可能是一个涉及多个抓取过程的长期任务的情况,例如“清理桌子”。这需要策略 π \pi π 对提示进行推理,将其分解为单独的抓取指令 { l i } \{l_{i}\} {li},并按顺序完成。
4. Method
本节介绍 DexGraspVLA 第一个用于灵巧抓取的分层 VLA 框架。首先阐述 DexGraspVLA 框架(第 4.1 节),然后详细说明数据采集流程(第 4.2 节),这两者共同构成了灵巧抓取策略的训练。
4.1 DexGraspVLA Framework
如Fig.2所示,DexGraspVLA采用了分层模块化的架构,由 规划器 和 控制器组成:
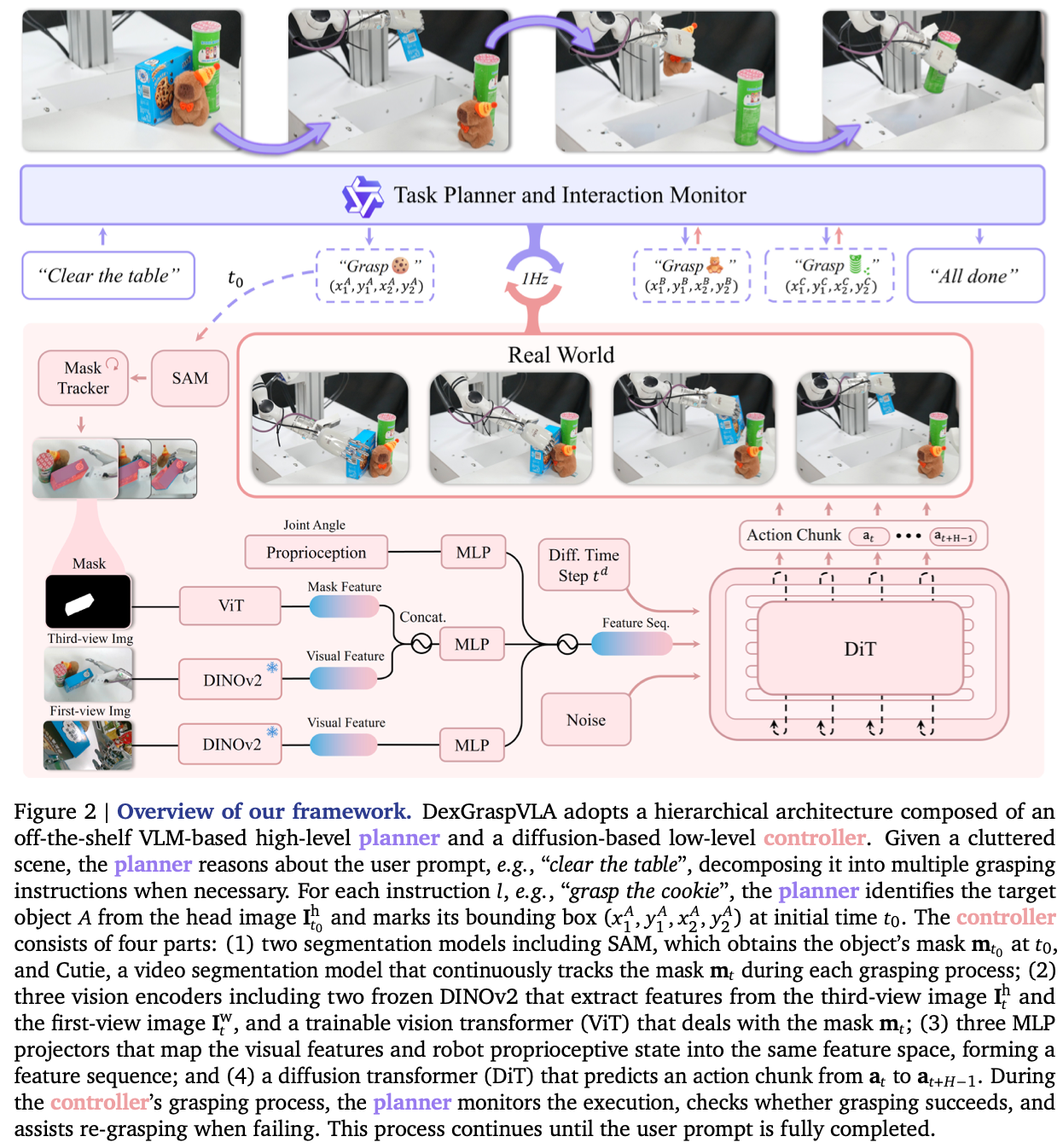
Planner
要实现一般的灵巧抓取,模型需要能够处理多模态输入、进行视觉基础训练,并对用户提示进行推理。基于 VLM 的最新进展,采用现成的预训练 Qwen-VL-Chat 作为高级规划器,以概述和监控灵巧抓取工作流程。对于用户提示
p
p
p,规划器会根据头部摄像头的观察结果推断执行计划。具体而言,如果
p
p
p 是一个涉及多个抓取步骤的长期任务描述,例如“清理桌子”,则规划器会考虑桌子上物体的位置和方向,并提出一个合适的抓取指令
l
1
l_{1}
l1 作为第一步,例如“抓住饼干”;否则,如果
p
p
p 直接瞄准一个物体进行抓取,则规划器会将其视为指令
l
l
l。
- 标记物图bounding box:对于每条指令 l l l,规划器通过在初始 t 0 t_{0} t0 时刻的头部图像 I t 0 h I^{h}_{t_{0}} It0h 标记目标物体bounding box ( x 1 , y 1 , x 2 , y 2 ) (x_{1},y_{1},x_{2},y_{2}) (x1,y1,x2,y2) 来引导低级控制器。虽然语言指令的内容对于不同的用户可能具有多样性和灵活性,即表现出领域差异性,但无论语言和视觉输入如何变化,bounding box对于物体定位都具有一致的格式,即实现了领域不变性,这种转换减轻了控制器的难度。
- 在控制器接受到bounding box后的执行过程中,规划器通过以 1Hz 的频率查询当前头部图像来监控进度;
- 如果发现机器人成功抓取物体,规划器将执行脚本化的放置动作将物体放入袋中,然后将机械臂和手重置为初始状态;
- 然后,规划器通过推理提示和视图中剩余的物体来提出新的抓取指令 l 2 l_{2} l2,直到提示 p p p 完全完成;
- 如果控制器未能抓取目标物体,规划器将重置机器人,并根据当前物体状态使用新指令重新初始化抓取循环;
Controller
基于目标 bounding box
(
x
1
,
y
1
,
x
2
,
y
2
)
(x_{1},y_{1},x_{2},y_{2})
(x1,y1,x2,y2),控制器旨在在杂乱环境中抓取目标物体。作者将此边界框作为输入输入到 SAM ,以获得目标物体的初始二值掩码
m
0
∈
{
0
,
1
}
H
×
W
×
1
m_{0}\in\{0,1\}^{H\times W\times 1}
m0∈{0,1}H×W×1,然后使用 Cutie 持续跟踪该掩码,在每个时间步
t
t
t 生成
m
t
m_{t}
mt,确保在整个过程中在杂乱场景中实现准确识别。核心在于学习到有效建模动作分布的策略
π
(
⋅
∣
I
t
W
,
I
t
h
,
s
t
,
m
t
)
\pi(\cdot|I^{W}_{t},I^{h}_{t},s_{t},m_{t})
π(⋅∣ItW,Ith,st,mt)。
为了实现通用灵巧抓取能力,系统必须能够在各种现实世界场景中有效泛化。然而,原始视觉输入
I
t
W
I^{W}_{t}
ItW 和
I
t
h
I^{h}_{t}
Ith 的可变性对学习任务关键表征构成了底层的挑战。传统的模仿学习方法即使在物体或环境条件的微小变化下也常常会失败。为了解决这个问题,作者的解决方案仍然是将潜在的领域变化输入转换为适合模仿学习的领域不变表征,虽然像素级感知可能差异很大,但大模型提取的细粒度语义特征往往更加稳健且一致。因此,利用一个特征提取器
ϕ
\phi
ϕ(例如已在互联网规模数据上预训练的 DINOv2 )从原始图像中获取特征。
在每个时刻 t t t,获取头部摄像头图像特征:
z t h = ϕ h ( I t h ) ∈ R L h × D h z^{h}_{t}=\phi^{h}(I^{h}_{t})\in R^{L^{h}\times D^{h}} zth=ϕh(Ith)∈RLh×Dh
在每个时刻 t t t,获取腕关节摄像图像特征:
z t w = ϕ w ( I t w ) ∈ R L w × D w z^{w}_{t}=\phi^{w}(I^{w}_{t})\in R^{L^{w}\times D^{w}} ztw=ϕw(Itw)∈RLw×Dw
其中 L h , D h , L w , D w L^{h},D^{h},L^{w},D^{w} Lh,Dh,Lw,Dw 分别表示头部和腕部图像特征序列的长度和隐藏维度,这些提取的特征对于分散视觉因素保持相对不变。
原始语言和视觉输入(包括指令和图像 I t w I^{w}_{t} Itw 和 I t h I^{h}_{t} Ith )已通过基础模型迭代转换为领域不变的表示,包括掩码 m t m_{t} mt 和特征 z t h z^{h}_{t} zth 和 z t w z^{w}_{t} ztw 。这为模仿学习奠定了基础。学习策略 π \pi π 基于这些表示来预测一个范围动作块。
为了将物体掩码与头部摄像头特征融合,使用随机初始化的 ViT 将
m
t
m_{t}
mt 映射到头部图像特征空间,得到
z
t
m
∈
R
L
h
×
D
h
z^{m}_{t}\in R^{L^{h}\times D^{h}}
ztm∈RLh×Dh,然后将
z
t
m
z^{m}_{t}
ztm 和
z
t
h
z_{t}^{h}
zth 逐块连接起来,形成:
z ˉ t h ∈ R L h × 2 D h \bar{z}^{h}_{t}\in R^{L^{h}\times 2D^{h}} zˉth∈RLh×2Dh
将 z ˉ t h \bar{z}^{h}_{t} zˉth、腕部摄像头特征 z t w z^{w}_{t} ztw 、机器人状态 s t s_{t} st 映射到一个由独立 MLP 组成的公共嵌入空间中,得到 z ~ t h , z ~ t w , z ~ t s \tilde{z}^{h}_{t}, \tilde{z}^{w}_{t}, \tilde{z}^{s}_{t} z~th,z~tw,z~ts,将这些嵌入连接起来,形成完整的观测特征序列:
z ~ t o b s ∈ R ( 1 + L h + L w ) × D \tilde{z}^{obs}_{t}\in R^{(1+L^{h}+L^{w})\times D} z~tobs∈R(1+Lh+Lw)×D
对于动作预测,遵循扩散策略范式采用 DiT生成多步骤动作。具体而言,在每个时刻
t
t
t,将后续动作打包成一个块
A
t
=
a
t
:
t
+
H
=
[
a
t
,
a
t
+
1
,
…
,
a
t
+
H
−
1
]
A_{t}=a_{t:t+H}=[a_{t},a_{t+1}, \dots,a_{t+H-1}]
At=at:t+H=[at,at+1,…,at+H−1]。训练期间随机采样扩散步骤
t
d
=
k
t^{d}=k
td=k,并将高斯噪声
ϵ
\epsilon
ϵ 添加到
A
t
A_{t}
At,得到带噪声的动作标记
x
k
x_{k}
xk:
x k = α k A t + σ k ϵ x_{k}=\alpha_{k}A_{t}+\sigma_{k}\epsilon xk=αkAt+σkϵ
其中
α
k
\alpha_{k}
αk 和
σ
k
\sigma_{k}
σk 是标准 DDPM 系数。然后将
x
k
x_{k}
xk 与观测特征序列
z
~
t
o
b
s
\tilde{z}^{obs}_{t}
z~tobs 一起输入 DiT。每个 DiT 层对动作 token 执行双向自注意力机制,对
z
~
t
o
b
s
\tilde{z}^{obs}_{t}
z~tobs 执行交叉注意力机制并进行 MLP 变换,最终预测原始噪声
ϵ
\epsilon
ϵ。通过最小化预测噪声与真实噪声之间的差异,模型学习重建真实动作块
A
t
A_{t}
At。
在推理时,迭代去噪步骤从学习到的分布中恢复预期的多步骤动作序列,从而能够对复杂的长时域行为进行鲁棒模拟。作者还采用了滚动时域控制策略,该策略仅执行前 H a H_{a} Ha 个动作,然后再生成新的动作块预测,从而增强了实时响应能力。
总体而言,DexGraspVLA 通过基础模型,对从输入的变化领域中衍生出领域不变表征,以此进行模仿学习。这种方法不仅利用了基础模型的世界知识和泛化能力,还能有效地捕捉从这些抽象表征到最终动作输出的映射。
4.2 Data Collection
为了训练灵巧抓取策略,作者手动采集了一个数据集,该数据集包含在杂乱场景中 2,094 个成功的抓取场景。该数据集涉及 36 个家用物品,涵盖各种尺寸、重量、几何形状、纹理、材料、类别。每个集和
τ
=
{
(
I
t
h
,
I
t
w
,
s
t
,
m
t
,
a
t
)
}
t
=
0
T
\tau=\{(I^{h}_{t},I^{w}_{t},s_{t},m_{t},a_{t})\}^{T}_{t=0}
τ={(Ith,Itw,st,mt,at)}t=0T 均包含原始相机图像
I
t
h
I^{h}_{t}
Ith、
I
t
w
I^{w}_{t}
Itw、机器人本体感知
s
t
s_{t}
st 、物体掩码
m
t
m_{t}
mt 、每个时刻
t
t
t 的动作
a
t
a_{t}
at。掩码
m
t
m_{t}
mt 的标记方式与控制器中的相同,对于每个物体,将其放置在
3
×
3
3\times 3
3×3 的网格排列九宫格中,并在每个位置采集多个抓取演示。杂乱场景中的其他物体在每集之间随机化。这些演示以人类平均速度进行大约需要 3.5 秒。样本经过了严格的人工筛洗,以确保质量和可靠性。DexGraspVLA 控制器基于该数据集,通过模仿学习进行训练。
5. Experiments
所有实验均在与演示配置不同的机器人和环境中进行。这种 zero-shot 设置从根本上比大多数先前的模仿学习研究更具挑战性,因为后者依赖于少量学习来实现高性能。实验旨在解决以下问题:
DexGraspVLA如何有效地推广到杂乱场景中数千种不同的、以前从未见过的物体、光照和背景组合(第 5.2 节);- 与不使用冻结特征提取器并直接从原始视觉输入中学习的基线相比,
DexGraspVLA的泛化优势如何(第 5.3 节); DexGraspVLA的规划器在不同场景下的bounding box预测有多准确(第 5.4 节);DexGraspVLA在不同环境下是否表现出一致的内部模型行为(第 5.5 节);
5.1 Experiment Setups
Hardware Platform
如Fig.3 所示,用于灵巧抓取的机器人是一个 7 自由度 Real-Man RM75-6F 机械臂,搭配一个 6 自由度 PsiBot G0-R 机械手。安装在机械臂手腕上的 RealSense D405C 摄像头提供第一人称视角,而安装在机器人头部的 RealSense D435 摄像头提供第三人称视角,待抓取的物体放置在机器人前方的桌子上,机器人的控制频率为 20 Hz。

Baselines
目前还没有可以直接作为比较基准的研究。大多数灵巧抓取方法无法处理杂乱场景的语言输入,而现有的接受语言输入的 VLA 框架与灵巧手不兼容。因此,作者对比了以下方法:
DexGraspVLA(Ours):DexGraspVLA的完整实现;DexGraspVLA(DINOv2-train):使用相同的模型结构,只是两个 DINOv2 模型是可训练的而不是冻结的;DexGraspVLA(ViT-small):使用相同的模型结构,只是两个 DINOv2 模型被两个小型可训练的预训练ViT(R26-S-32 ResNet-ViT)所取代。
DexGraspVLA (ViT-small) 代表了扩散策略的增强版本,模型实现细节在Appendix. A 中提供。在实验初期,作者发现失败可能是由于策略推理的随机性引起的,可以通过额外的尝试来克服。在 5.2 节中比较了 DexGraspVLA (Ours@k),k 的范围从 1 到 3,所有部分都一样只是它们分别允许在每次测试中尝试 9 次,Ours@1 则只允许尝试1次。在单次尝试中初始失败后由策略执行的重新抓取是被允许的,并且不算作单独的尝试。在第 5.4 节中,评估了DexGraspVLA(规划器)的bounding box预测性能,它是 DexGraspVLA 中高级规划器的完整实现。
5.2 Large-Scale Generalization Evaluation
Tasks
作者挑选了 360 个未见过的物体、6 种未见过的背景、3 种未见过的光照条件。这些物体都经过精心挑选,以确保它们涵盖各种不同的尺寸、重量、几何形状、纹理、材质、类别,同时又能被灵巧手抓握,Fig.4 展示了上述多样性。
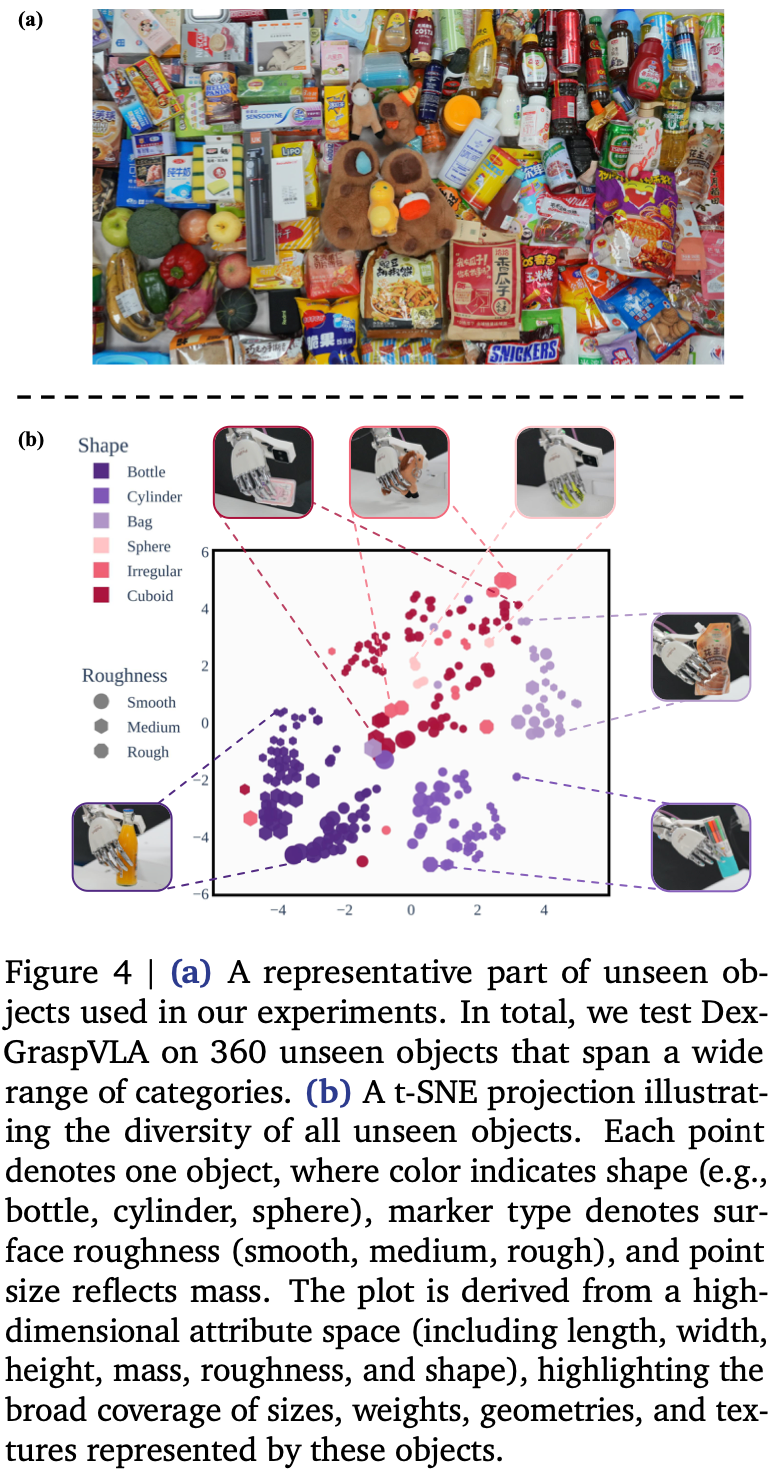
基于此配置,作者设计了三种杂乱场景中的抓取任务,每种杂乱场景涉及大约六个物体:
- 未见过的物体:在白光下从白色桌面上的随机场景中抓取一个未见过的物体。360 个未见过的物体每个都瞄准一次,共计 360 次测试;
- 未见过的背景:首先随机选择 103 个未见过的物体作为物体子集 S S S。对于每种背景,在白光下随机排列 103 个杂乱场景,其中包含 S S S 中的物体。 103 个物体中的每一个都被瞄准一次,总共进行了 618 次测试;
- 未见光照:对于每种未见光照颜色,构建 103 个杂乱场景,其中
S
S
S 中的物体位于一张白色桌子上。对这 103 个物体中的每一个都瞄准一次,总共进行了 309 次测试。详情请参阅
Appendix. B。
Metrix
如果抓取物体距离桌面 10 厘米并保持 20 秒,则被认为抓取尝试成功。将成功率作为评估指标,其定义为成功测试次数除以总测试次数。
Results
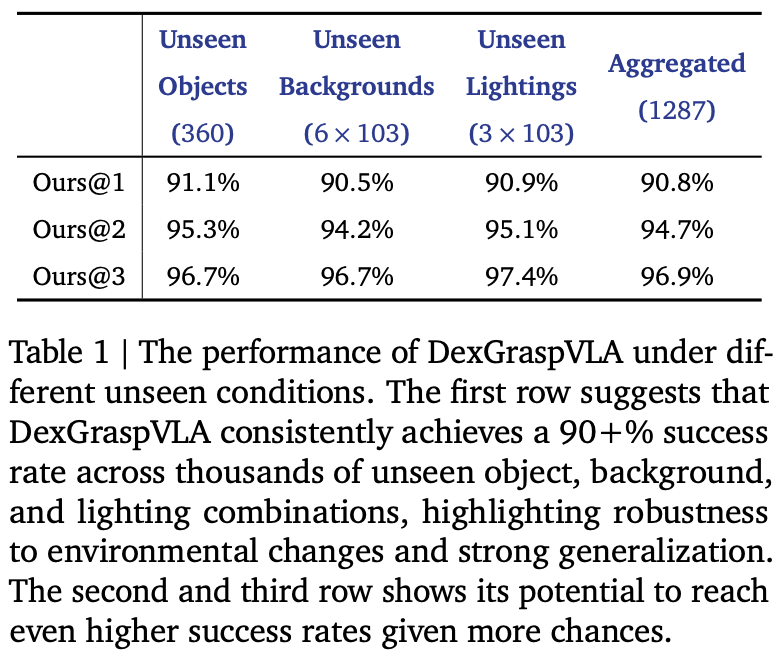
Table.1中展示了定量结果。从第一行(“Ours@1”)开始,DexGraspVLA 在 360 个未见过的物体上实现了 91.1% 的单次尝试成功率;在 6 个未见过的背景下实现了 90.5% 的成功率;在 3 种未见过的光照条件下实现了 90.9% 的成功率,总体成功率为 90.8%。
实验结果表明,DexGraspVLA 能够精准控制灵巧手从杂乱物体中抓取指定物体,同时保持对环境变化的鲁棒性。尽管评估新颖环境新颖的任务是前所未有的,DexGraspVLA 仍能始终保持高成功率,无需进行任何微调,彰显了其强大的泛化能力。框架显著缓解了模仿学习中长期存在的挑战,即过度拟合到单一领域并依赖微调才能获得令人满意的性能,在5.5节中将进一步分析这一泛化能力的来源。
从定性上看,DexGraspVLA 能够学习灵活地调整手臂和手部以适应不同的物体几何形状、尺寸、位置。尽管物理干扰或非最优动作偶尔会导致抓取失败,但策略的闭环特性有助于基于更新的观测数据进行重新抓取,从而增强了鲁棒性。该方法还能容忍人为干扰,因为机器人可以跟踪并跟随重新定位的物体,直到成功抓取。
从第二行和第三行(“Ours@2”和“Ours@3”)可以看出,虽然单次尝试可能会出现随机性和偶然失败,但多次尝试通常可以成功,三次尝试内的成功率提升至 96.9%。这表明策略能够达到更高的成功率。模型平均需要约 6 秒才能抓取一个物体,这与人类的抓取速度接近,并确保了在实际场景中的实用性。
通过大规模评估证实DexGraspVLA 可以稳健地处理各种未见过的场景,这代表着朝着一般灵巧抓取迈出了有意义的一步,并有望在现实世界中得到更广泛的部署。
5.3 Comparison to Baselines without Frozen Vision Encoders
Tasks
为了系统地将 DexGraspVLA 与未使用冻结视觉编码器并直接从原始视觉输入中学习的基线进行比较,使用训练数据集中的 13 个可见物体和 8 个不可见物体进行了单物体抓取实验。在桌子上选择了五个位置,这些位置既跨越操作工作空间,又在机器人的触及范围和头部摄像头的视野范围内。每个物体都放置在这五个点上,在每个点上让策略抓取它两次,同一点对同一物体的两次抓取计为两次单独的测试,而不是同一测试的重复尝试。这种方法定量地解释了实验中的随机性。总共涉及 210 次测试。这些实验中的环境条件是白色桌面和白光。
Results
Fig.5 表明,DexGraspVLA(Ours)在可见和不可见物体抓取实验中始终能达到 98% 以上的成功率,显著优于 DexGraspVLA(DINOv2-train)和 DexGraspVLA(ViT-small)。策略在 zero-shot 测试环境中的总体表现近乎完美,这表明 DexGraspVLA(Ours)不受视觉输入域偏移的影响。在未见过物体上的表现甚至比在可见物体上的表现还要好一些,这再次证实了模型学会了完成抓取任务,而不是对训练集中的可见数据进行过度拟合。相比之下,其他设计在新环境中无法正常工作,因为它们直接将原始输入映射到动作,而感知变化很容易使它们脱离分布。
5.4 Bounding-box Prediction Accuracy of Planner
Tasks
规划器的bounding box预测精度对于抓取的成功至关重要,因为它决定了控制器的目标。为了评估该精度,作者设计了三类具有不同环境干扰的任务:
- 无干扰(1 种场景):杂乱的场景摆放在白光下的白色桌子上;
- 背景干扰(2 种场景):杂乱的场景放在校准板或色彩鲜艳的桌布上,均在白光下;
- 灯光干扰(2 种场景):场景设置在由台灯或迪斯科灯照明的黑暗房间中。
对于每种场景随机安排 5 个杂乱的场景,每个场景包含 6 个随机选择的物体,然后记录头戴式摄像机图像;每个物体提对其外观和位置的文本提示,并检查规划器的bounding box预测是否准确标记了目标。总体而言,无干扰占 30 次测试,而背景干扰和灯光干扰各占 60 次测试,总共 150 次测试。
Results
Table.2 的 150 个提示中,规划器仅错误标记了一个bounding box,其余 149 个测试均成功,总体准确率超过 99%。证明了规划器能够可靠地对用户提示进行视觉定位,并能够在不同程度的背景和光照复杂度下为控制器标记正确的bounding box。

5.5 Internal Model Behavior Analysis
为了进一步证明模型内部行为在视觉变化中是一致的,如Fig.6所示。由于版面大小限制,作者仅显示包含桌面工作空间的每幅图像的相关部分,完整的未裁剪图像在Appendix. B 中提供。
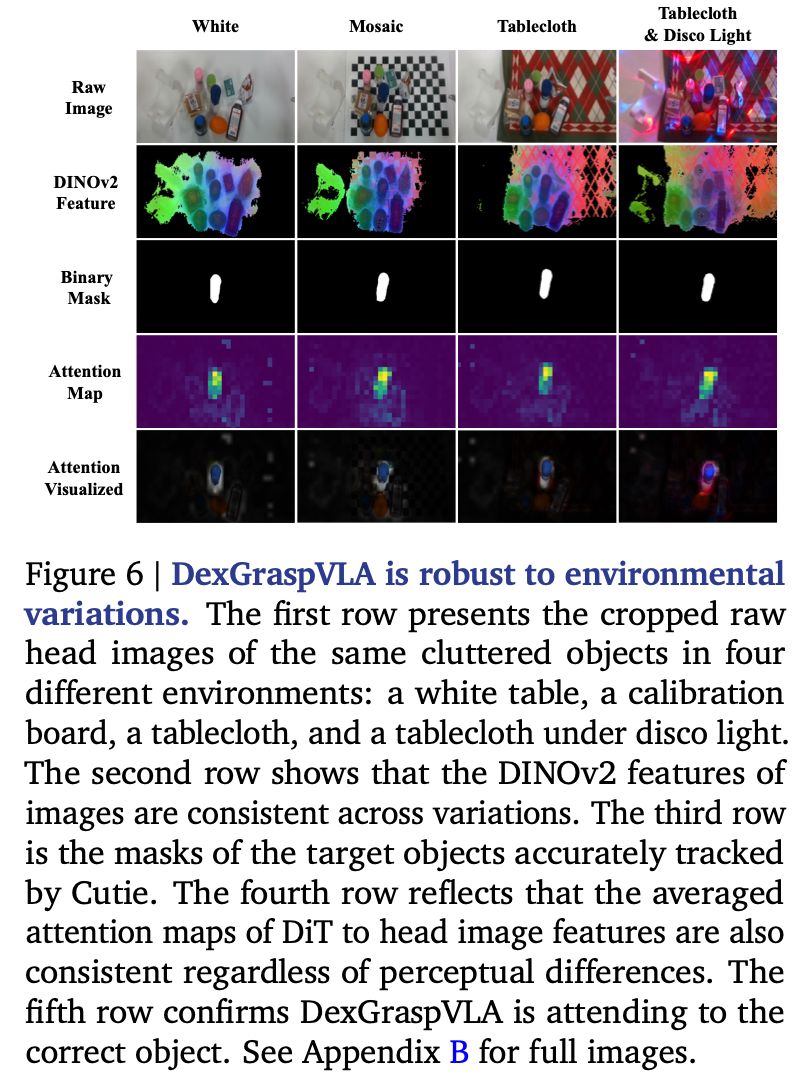
作者通过设计四种截然不同的环境条件:白色桌子、校准板、彩色桌布、带有迪斯科灯光的彩色桌布。在每种环境中,构建包含九个物体的相同杂乱场景,并让 DexGraspVLA “抓住中间的蓝色酸奶”。虽然Fig.6 第一行中的头部图像看起来明显不同,但第二行中的 DINOv2 特征看起来相当一致。这些特征通过将主成分映射到 RGB 通道来可视化。跨环境对象属性得到稳健的维护和匹配,从根本上使在单个数据域上训练的 Dex-GraspVLA 能够泛化。第三行显示 Cutie 准确地跟踪对象,为控制器提供正确的引导。基于领域不变掩码和 DINOv2 特征,DiT 动作头可以预测后续动作。在第四行中,对 DiT 的所有对头部图像的交叉注意进行平均和归一化,发现所有注意力图都表现出相同的行为,即专注于目标对象而不是被环境分散注意力。第五行将注意力图叠加在原始图像上,以确认合理的注意力模式。
综上,证实 DexGraspVLA 确实将感知多样的原始输入转换为不变的表示,在此基础上它有效地应用模仿学习来建模数据分布,从而解释了其卓越的泛化性能。不出所料,它成功地在四种环境中抓住了酸奶。
6. Limitations
尽管 DexGraspVLA 在一系列未见过的场景中取得了很高的成功率,但仍存在一些局限性。首先,由于时间限制,训练集不包含非常小的物体或极其混乱的环境;通过专门的数据采集,可以提升在这些更具挑战性的情况下的表现。此外,目前尚未探索抓取后对物体进行操作的部分,这是未来研究的一个有前景的方向。
7. Conclusion
本文提出了 DexGraspVLA,这是首个面向通用灵巧抓取的分层VLA框架。它利用预训练的VLM作为高级规划器来规划抓取过程,并采用基于扩散的策略作为低级控制器来执行抓取的闭环动作预测。Dex-GraspVLA 利用基础模型的世界知识来理解各种原始输入,并将其转换为领域不变的表征。然后,运用模仿学习来建模从表征到动作分布的映射,由于减轻了领域偏移的影响,该方法非常有效。实验表明,模型 zero-shot 测试中对数千个未见过的杂乱场景中取得了超过 90% 的成功率,展现了强大的泛化能力。对其内部模型行为的实证分析进一步验证了底层框架的设计。总体而言,DexGraspVLA 展现了利用基础模型提升灵巧抓取泛化能力的潜力。作者计划在未来的工作中进一步提升其性能并拓展其应用范围。

















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









