




向量数据库基础概念
LLM的向量通常是在数据经过Embedding模型后所得到的。由此产生大量的向量数据,而存储向量数据的数据库就是向量数据库
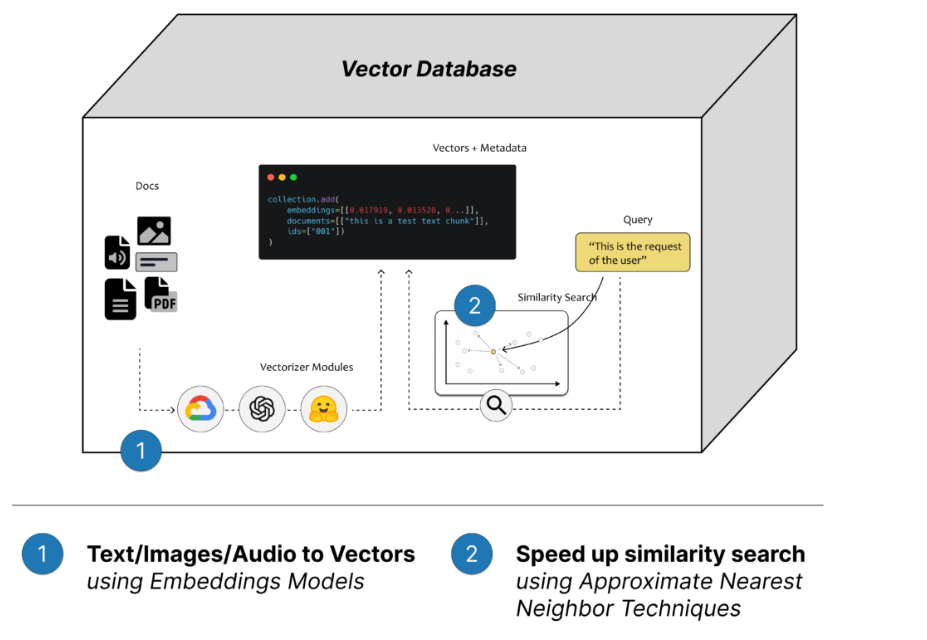
向量数据库的工作流程可概括为以下几个步骤:
- 向量化:使用嵌入模型将文本等数据转化为向量
- 索引构建:使用HNSW等算法构建高效检索索引
- 向量存储:将向量与原始数据元信息一起存储
- 相似性检索:基于距离计算(如余弦相似度、欧氏距离)找到最相似的向量
- 结果匹配:返回相似向量对应的原始数据
向量数据库之所以能实现高效检索,关键在于其高效的索引与搜索机制,举例百万的向量存储在向量数据库中,当用户输入时候首先进行索引构建得到topk个向量,而不是直接对百万个向量进行相似度计算。向量数据库中采用的索引技术为如下:
-
层次化可导航小世界(HNSW):构建一种类似"快捷通道"的多层图结构,使搜索可以先在高层快速跳跃,再在低层精确定位,显著减少需要比较的向量数量。
-
乘积量化(PQ):通过将高维向量分解并压缩成更小的子向量码本,大幅降低内存占用和计算复杂度,同时保留向量的核心语义特征。
-
局部敏感哈希(LSH):巧妙地将相似向量映射到相同的"桶"中,使系统只需比较有限范围内的候选项,而非整个数据集。
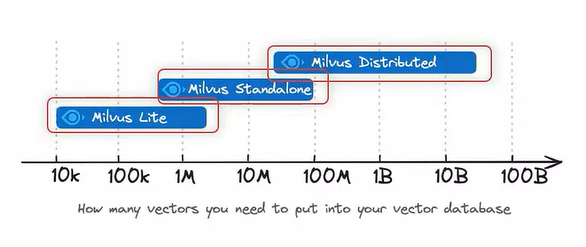
主流向量数据库对比
目前市场上的向量数据库大致可分为两类:专用向量数据库和传统数据库的向量扩展。如图左侧板块是专用向量数据库,右侧是传统数据库的拓展。

- Chroma:适合快速原型开发、中小规模项目、简单部署要求
- Milvus:适合企业级应用、大规模项目、高并发场景、需要分布式部署
本文会重点分析两款热门的专用开源向量数据库:
chroma
Milvus
Chroma
Chroma是一款AI原生的开源向量数据库,特点是简单易用。
使用方式:pip install Chroma
核心优势:
- 框架集成:与LangChain、LlamaIndex等框架无缝对接
- 适合场景:千万级别向量的中小型项目
基本用法示例:
import chromadb
# 创建客户端
client = chromadb.Client()
# 创建集合
collection = client.create_collection(
name="documents",
embedding_function=embedding_model # 指定向量化模型
)
# 添加文档
collection.add(
documents=["文档内容..."],
ids=["doc1"],
metadatas=[{"category": "finance"}] # 元数据用于后期过滤
)
# 查询相似文档
results = collection.query(
query_texts=["用户问题"],
n_results=3,
where={"category": "finance"} # 元数据过滤
)
Milvus
Milvus是一款高性能、分布式的云原生向量数据库,功能更强大,更适合大规模应用。本地部署支持百万级别查询,服务端部署支持亿级别查询。还支持GPU加速查询
基本用法示例:
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType
# 连接Milvus服务器
connections.connect("default", host="localhost", port="19530")
# 需要使用FieldSchema,来声明字段
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=1536),
FieldSchema(name="metadata", dtype=DataType.JSON)
]
schema = CollectionSchema(fields=fields)
# 创建集合
collection = Collection(name="documents", schema=schema)
# 创建索引
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 1024}
}
collection.create_index("embedding", index_params)
# 添加数据
collection.insert([
[1], # id
[[0.1, 0.2, ..., 0.3]], # 向量
[{"category": "finance"}] # 元数据
])
# 加载集合并查询
collection.load()
results = collection.search(
data=[[0.1, 0.2, ..., 0.3]],
anns_field="embedding",
param={"metric_type": "L2"},
limit=3,
expr="metadata.category == 'finance'" # 元数据过滤
)
向量相似度计算:欧氏距离与余弦相似度的比较
在大模型应用中,无论是RAG(检索增强生成)系统、语义搜索还是推荐系统,都需要计算查询向量与知识库中大量向量的相似度。
选择合适的相似度计算方法直接影响检索结果的质量和系统的性能。我们将从两种主流相似度计算方法,来探究选择方案。
欧氏距离(Euclidean Distance)
欧氏距离是将两个向量对应位置的元素相减,对差值进行平方,然后求和并开平方根。
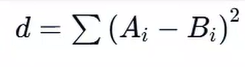
特点:
- 距离越小,表示向量越相似
- 当两个向量完全相同时,距离为0
- 计算结果受向量幅值(magnitude)影响
- 计算结果范围:[0, +∞)
欧氏距离的优势场景
-
当向量幅值有实际意义时:例如在图像处理或传感器数据分析中,向量的绝对大小携带重要信息。
-
数据分布均匀且规范化良好的情况:当数据经过良好的标准化处理,欧氏距离能提供直观且有效的相似度度量。
-
低维向量空间:在低维空间中,欧氏距离的几何直观性更有优势。
-
需要考虑绝对差异的场景:例如基于坐标的物理系统,距离的绝对值有实际物理意义。
余弦相似度(Cosine Similarity)
余弦相似度通过计算两个向量之间夹角的余弦值来衡量相似性,它关注的是向量的方向而非大小。
余弦相似度是两个向量的点积除以它们模长的乘积。
特点:
- 相似度越大(接近1),表示向量越相似
- 当两个向量方向完全一致时,相似度为1
- 当两个向量方向完全相反时,相似度为-1
- 当两个向量方向垂直时,相似度为0
- 计算结果不受向量幅值影响,只关注方向
- 计算结果范围:[-1, 1](文本向量通常为正,范围缩小为[0, 1])
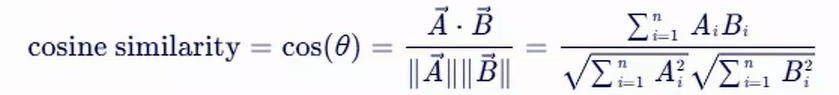
余弦相似度的优势场景
-
文本语义检索:在大模型文本语义搜索中,通常更关注语义方向而非"量"的大小,余弦相似度是首选。
-
高维稀疏向量:文本embedding通常是高维稀疏向量,余弦相似度在处理这类数据时计算效率更高。
-
文档长度差异大的情况:余弦相似度不受文档长度影响,能更好地比较不同长度的文档。
-
需要忽略幅值差异的场景:当只关注向量方向而不关心大小时,例如文本语义、用户偏好分析等。


















 376
376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











