







 Visual Genome数据集由斯坦福大学人工智能实验室主任李菲菲等开发,旨在提供一个丰富的数据集以帮助计算机理解图片。它包含了区域描述、物体、属性、关系、区域图、场景图和问答对,通过将视觉概念落实到语义层面,提供更全面的图像理解。数据集的创建灵感来源于人类认知过程,目标是通过多区域描述、问答和形式化表示来实现图像认知的深化。
Visual Genome数据集由斯坦福大学人工智能实验室主任李菲菲等开发,旨在提供一个丰富的数据集以帮助计算机理解图片。它包含了区域描述、物体、属性、关系、区域图、场景图和问答对,通过将视觉概念落实到语义层面,提供更全面的图像理解。数据集的创建灵感来源于人类认知过程,目标是通过多区域描述、问答和形式化表示来实现图像认知的深化。
Visual Genome数据集
Visual Genome数据集,是由斯坦福大学人工智能实验室主任李菲菲与几位同事合作开发的。
数据集及论文网址:http://visualgenome.org/
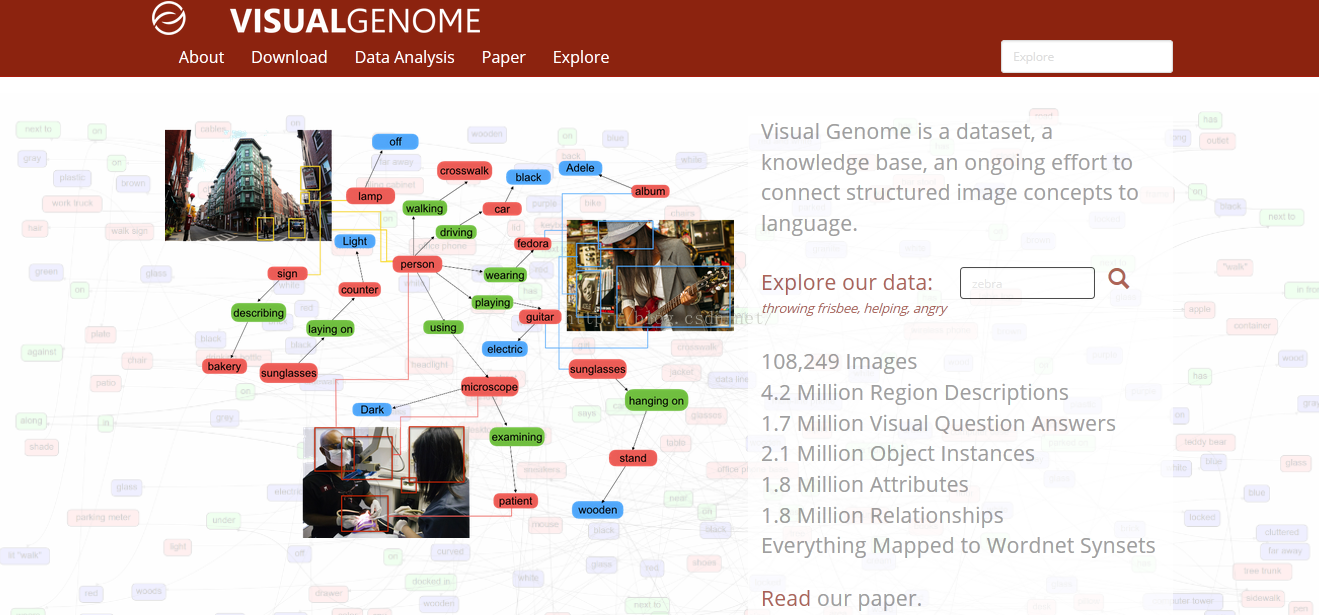
一、作者的初衷是什么?为什么要设计出这样一个数据集?
1.作者在视觉领域研究了多年,一直致力于寻求最好的算法,来达到更好的效果。但是受人类对于世界的认识过程的启发,作者认为,教计算机理解图片,其实和教儿童认识世界的过程是类似的。儿童的眼睛就类似一对生物相机,3岁时他已经浏览过数亿张真实世界的图像,这是一个非常庞大的训练数据集。
由
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









