



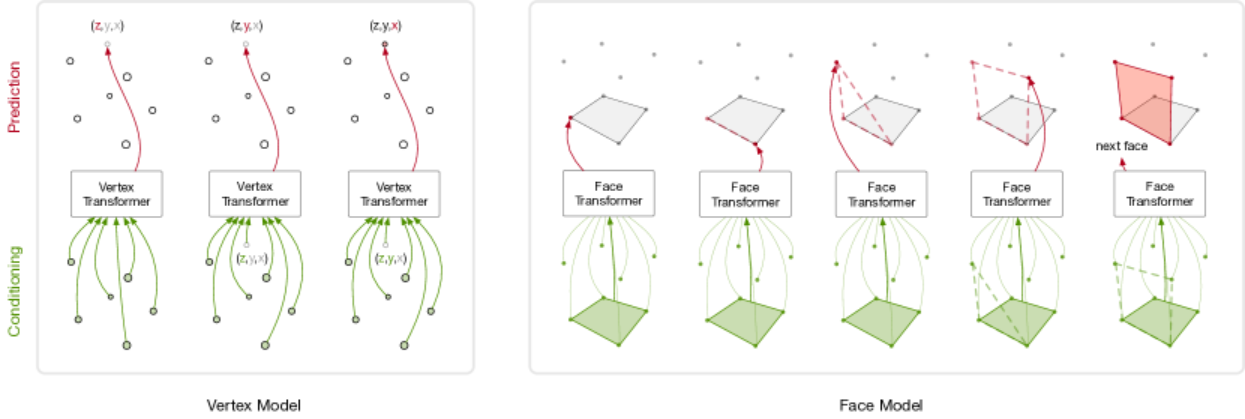
 图 2:PolyGen 首先生成网格顶点(左侧),然后基于这些顶点生成网格面(右侧)。顶点在垂直轴上从低到高顺序生成。为了生成下一个顶点,当前顶点坐标序列被作为上下文输入到顶点 Transformer 中,该 Transformer 输出下一个顶点坐标的预测分布。面模型以一组顶点和当前的面索引序列为输入,输出顶点索引的分布。
图 2:PolyGen 首先生成网格顶点(左侧),然后基于这些顶点生成网格面(右侧)。顶点在垂直轴上从低到高顺序生成。为了生成下一个顶点,当前顶点坐标序列被作为上下文输入到顶点 Transformer 中,该 Transformer 输出下一个顶点坐标的预测分布。面模型以一组顶点和当前的面索引序列为输入,输出顶点索引的分布。
神经自回归模型已展现出对复杂、高维数据的建模能力,包括图像(van den Oord 等人,2016c)、文本(Radford 等人,2019)和原始音频波形(van den Oord 等人,2016a)。受这些方法的启发,我们提出了 PolyGen,一种神经生成模型,它自回归地估计网格顶点和面的联合分布。
PolyGen 由两部分组成:一个顶点模型,用于无条件地建模网格顶点;以及一个面模型,根据输入顶点对网格面进行建模。这两个组件都采用了 Transformer 架构(Vaswani 等人,2017 年),该架构在捕获网格数据中存在的长距离依赖关系方面非常有效。顶点模型使用带掩码的 Transformer 解码器来表示顶点序列的分布。对于面模型,我们将 Transformer 与指针网络(Vinyals 等人,2015 年)相结合,以表示可变长度顶点序列的分布。
我们使用对数似然和预测精度作为指标,评估了 PolyGen 的建模能力,并将生成的样本的统计数据与真实数据进行比较。我们展示了在对象类别、图像和体素作为输入的情况下进行条件网格生成,并与现有的网格生成方法进行了比较。总体而言,我们发现我们的模型能够创建多样化和逼真的几何形状,这些几何形状可以直接用于图形应用。
我们的目标是估计一个关于网格 ℳ 的分布,从中可以生成新的示例。网格是由 3D 顶点 𝒱 和多边形面 F 的集合组成,它们定义了 3D 对象的形状。我们将建模任务分为两个部分:i) 生成网格顶点 𝒱 ,以及 ii) 给定顶点生成网格面 ℱ 。使用链式法则,我们有:
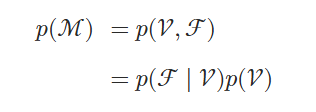
-
公式 (1) :表示网格 M 的概率分布 p(M) ,等于顶点 V 和面 F 的联合概率分布 p(V,F) 。这是概率论中的基本概念,即一个由顶点和面构成的网格的分布,可以用顶点和面同时出现的概率来表示。
-
公式 (2) :利用链式法则(乘法公式),将联合概率分布分解为条件概率分布与边缘概率分布的乘积。即 p(M)=p(V,F)=p(F∣V)p(V) ,其中 p(F∣V) 表示在给定顶点 V 的情况下,生成面 F 的条件概率分布;p(V) 表示生成顶点 V 的边缘概率分布。这样分解的目的是将复杂的联合分布建模任务拆分为两个相对简单且可处理的部分,先生成顶点,再基于顶点生成面。


使用概率写法的目的在于提供一种严谨而清晰的数学框架,以帮助我们理解和分解建模任务的复杂性。具体来说,有以下几方面原因:
1. 描述不确定性
现实世界中的数据生成过程往往存在不确定性。通过使用概率分布,我们能够量化这种不确定性。例如,在生成 3D 网格时,顶点和面的生成不是确定性的,而是存在多种可能性。概率写法允许我们描述每种可能性出现的 likelihood(似然),从而更真实地反映数据生成的本质。
2. 分解复杂任务
链式法则提供了一种将联合概率分布分解为条件概率和边缘概率的工具。这使得我们能够将复杂的建模任务(如同时生成顶点和面)分解为更小、更易处理的子任务。例如,通过将 p(M) 分解为 p(F∣V)p(V),我们可以分别专注于顶点生成和面生成,这样每个子任务都比直接处理整个网格要简单得多。
3. 提供数学基础
概率写法为模型的训练和优化提供了坚实的数学基础。例如,我们可以通过最大化似然函数(Maximum Likelihood Estimation, MLE)来估计模型的参数,这是许多机器学习算法的核心原则。利用概率公式,我们能够明确地定义目标函数,并通过梯度下降等优化方法来调整模型参数,以提高生成数据与真实数据分布的相似性。
4. 评估和比较模型
概率模型允许我们评估生成数据的质量,并对不同模型进行比较。例如,我们可以通过计算生成数据的对数似然(log-likelihood)来衡量模型的性能。对数似然越高,表明模型生成的数据越接近真实数据分布。这种定量评估方法为模型的选择和改进提供了依据。
5. 便于结合先验知识
概率框架使得我们能够方便地将先验知识整合到模型中。例如,如果我们对顶点或面的分布有一定的先验理解(如顶点在空间中的分布密度),我们可以将这些先验信息编码为先验概率分布,并通过贝叶斯定理与数据 likelihood 结合,从而得到后验分布。这种能力对于提高模型的性能和适应特定任务非常重要。
总结
概率写法的使用,本质上是为了在不确定性环境下,以一种系统化和数学化的方式对复杂数据生成过程进行建模。它帮助我们将任务分解,提供优化目标,量化模型性能,并整合各种信息源,使得整个建模和生成过程更加可控、可理解和可优化。
我们使用独立的顶点和面模型,两者都是自回归的;将顶点和面的联合分布分解为条件分布的乘积。要生成网格,我们首先采样顶点模型,然后将生成的顶点作为输入传递给面模型,从中采样面(见图 2)。此外,我们可选地基于上下文 𝐡 条件化顶点和面模型,例如网格类别身份、输入图像或体素化形状。
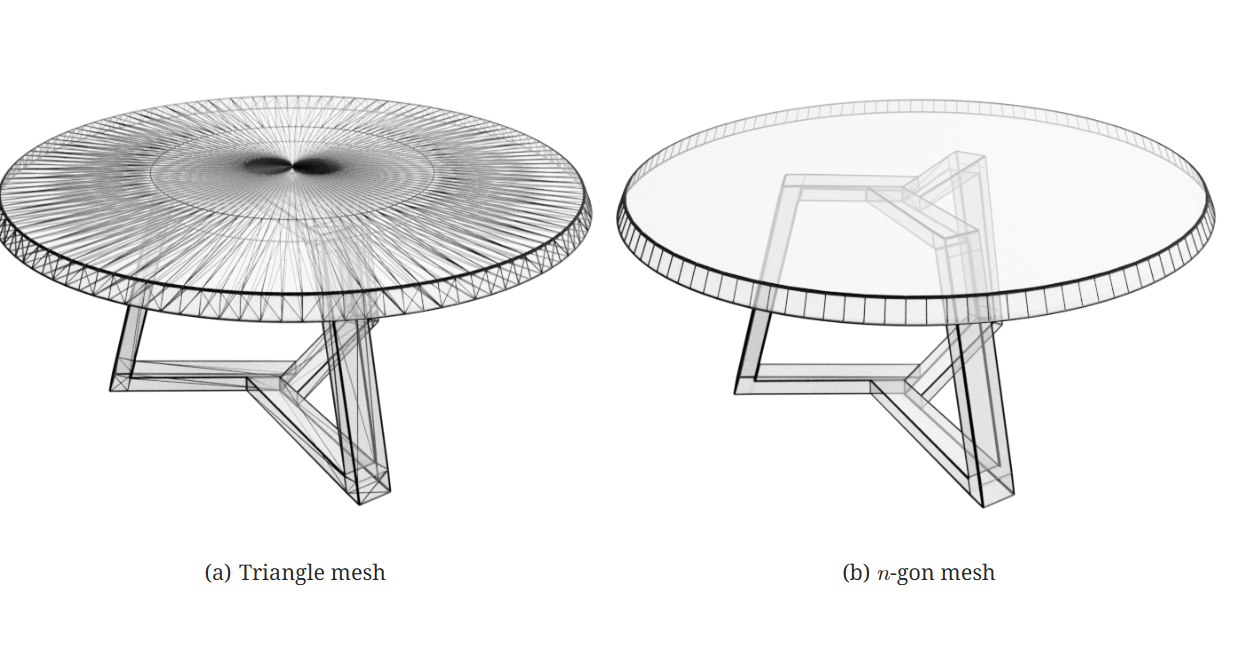
3D 网格通常由一系列三角形组成,但许多网格可以使用不同大小的多边形更紧凑地表示。具有可变长度多边形的网格称为 n -边形网格:
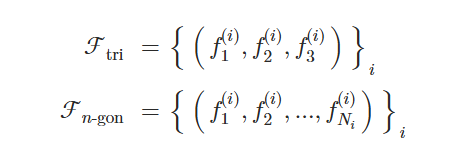
其中 Ni 表示第 i 个多边形的面的数量,并且可能因不同的面而异。这意味着大面积的平坦表面可以用单个多边形表示,例如图 3 中圆形桌面的顶部。在本工作中,我们选择使用 n 边形而不是三角形来表示网格。这有两个主要优点:首先,它可以减小网格的大小,因为平坦表面可以用更少的面来指定。其次,大面积的多边形可以有多种三角剖分方式,并且这些三角剖分在不同的示例中可能不一致。通过建模 n 边形,我们消除了这种三角剖分的变化性。
这种方法需要注意的是,当 n 大于 3 时, n -gons 不会唯一地定义 3D 表面,除非它引用的顶点是平面的。当渲染非平面 n -gons 时,多边形首先通过例如将顶点投影到平面来三角化(Held,2001),如果多边形高度非平面,这可能会导致伪影。在实践中,我们发现我们的模型产生的大多数 n -gons 要么是平面的,要么接近平面的,因此这是一个小问题。三角形网格是 n -gon 网格的子集,因此如果需要,可以使用 PolyGen 对它们进行建模。
2.2Vertex Model 2.2 顶点模型



我们使用自回归网络对这种分布进行建模,该网络在每个步骤输出预测下一个顶点坐标的预测分布的参数。这个预测分布定义在顶点坐标值以及停止标记 s 上。该模型被训练以最大化关于模型参数 θ 的观测数据的对数概率。
架构。顶点模型架构的基础是一个 Transformer 解码器(Vaswani 等人,2017 年),这是一个简单且表达能力强的模型,在多个领域已展现出显著的建模能力(Child 等人,2019 年;Huang 等人,2019 年;Parmar 等人,2018 年)。网格顶点具有强烈的非局部依赖性,包括物体对称性和重复部分,而 Transformer 从输入的任何部分聚合信息的能力使其能够捕捉这些依赖性。我们使用在残差路径中包含层归一化的改进型 Transformer 变体,如(Child 等人,2019 年;Parisotto 等人,2019 年)所述。顶点模型的示意图参见图 12,Transformer 块的详细描述参见附录 C。
顶点作为离散变量。我们对网格顶点应用 8 位均匀量化。这减少了网格的大小,因为落入同一区间的邻近顶点会被合并。我们使用 Categorical 分布对量化后的顶点值进行建模,并在每一步输出该分布的对数概率。这种方法已被用于 PixelCNN(van den Oord 等人,2016c)和 WaveNet(van den Oord 等人,2016a)中对离散连续信号进行建模,并且具有能够表达无形状限制分布的优点。网格顶点具有强对称性和复杂依赖关系,因此能够表达任意分布的能力非常重要。我们发现 8 位量化在网格保真度和网格大小之间取得了良好的平衡。然而,需要注意的是,对于有损网格压缩,通常使用 14 位或更高位。在未来的工作中,将我们的方法扩展到更高分辨率的网格将是理想的。
嵌入。我们发现使用(Child 等人,2019 年)中提出的通过学习位置和值嵌入方法的工作效果良好。我们对每个输入标记使用三种嵌入:一个坐标嵌入,它表示输入标记是 x 、 y 还是 z 坐标;一个位置嵌入,它表示标记属于序列中的哪个顶点;以及一个值嵌入,它表示标记的量化坐标值。我们在每种情况下都使用学习到的离散嵌入。
2.3Face Model 2.3 面模型


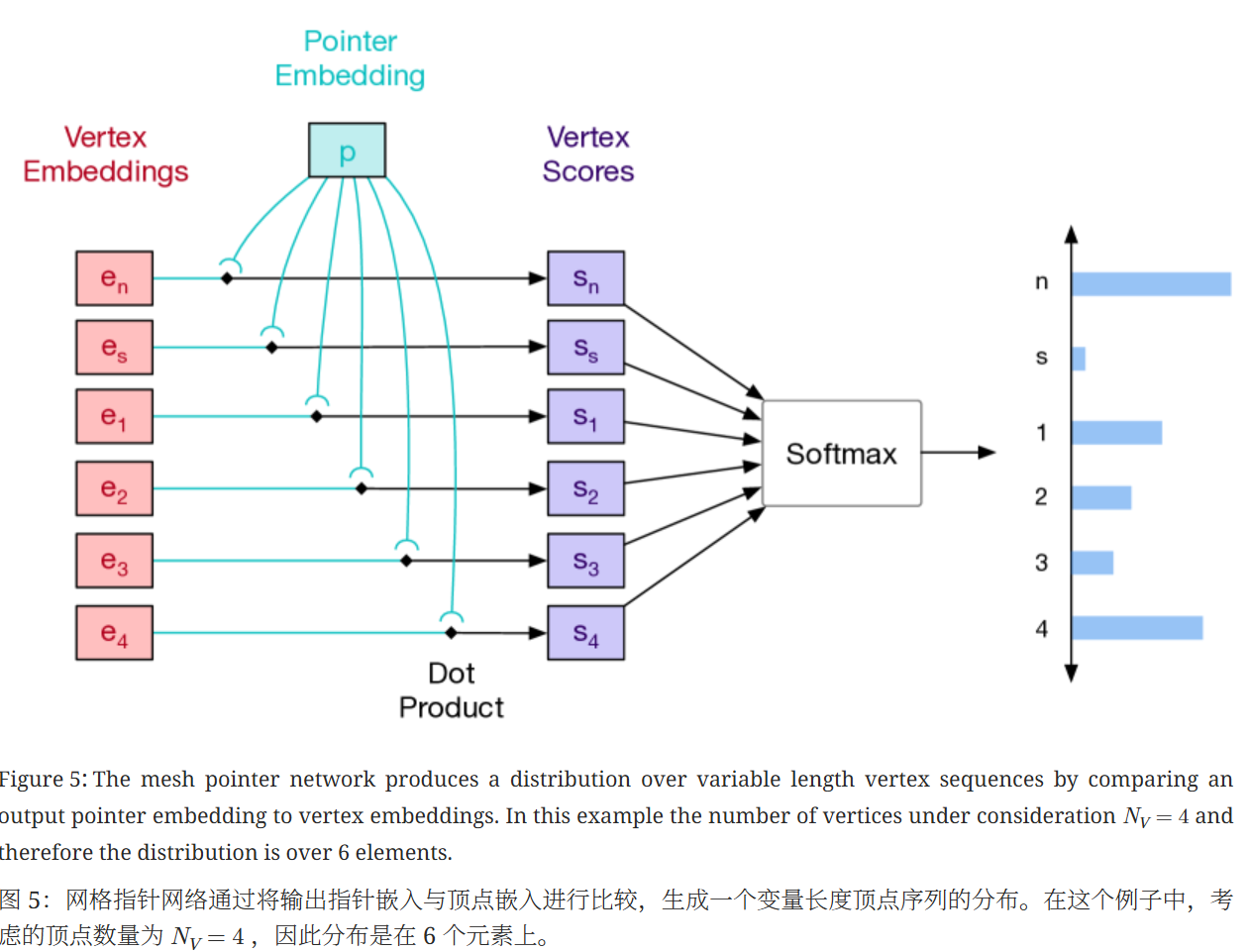
网格指针网络。目标分布 p(fn|f<n,𝒱;θ) 定义在输入顶点集的索引上,这提出了一个挑战,即该集合的大小在不同示例中变化。指针网络(Vinyals 等人,2015 年)提出了一个优雅的解决方案;首先使用编码器对输入集进行嵌入,然后在每一步,自回归网络输出一个指针向量,该向量通过点积与输入嵌入进行比较。然后使用 softmax 对得到的分数进行归一化,以在输入集上形成一个有效的分布。
指针网络(Pointer Networks)是一种用于处理可变大小输入集合的神经网络架构,特别是当输出需要指向输入集合中的特定元素时。它由 Vinyals 等人在 2015 年提出,主要用于解决像旅行商问题(TSP)这样的组合优化问题,但也可以应用于其他需要从输入集合中选择元素的任务,比如网格生成中的面生成。
在网格生成场景中,目标是定义一个条件分布 p(fn∣f<n,V;θ),其中 fn 是当前要生成的面,f<n 是之前生成的面,V 是顶点集合。由于顶点集合 V 的大小在不同示例中变化,这给传统的神经网络建模带来了挑战。指针网络通过以下方式解决了这个问题:
指针网络的工作原理
-
编码器嵌入:
-
首先使用一个编码器(通常是循环神经网络 RNN 或 Transformer)对输入的顶点集合 V 进行嵌入,将每个顶点转换为一个固定维度的向量表示。这一步的目的是捕捉顶点的特征信息,并为后续的指针操作做准备。
-
-
自回归生成指针向量:
-
在每一步生成面 fn 时,自回归网络(通常是另一个 RNN 或 Transformer)根据之前生成的面 f<n 以及当前的上下文信息,输出一个指针向量。这个指针向量的目的是指向输入顶点集合中的某个顶点,从而确定当前面的一个顶点。
-
-
点积比较:
-
指针向量与输入顶点的嵌入向量进行点积操作。点积的结果可以看作是每个顶点与当前指针向量的匹配程度,反映了每个顶点被选为当前面顶点的可能性。
-
-
Softmax 归一化:
-
将点积得到的分数通过 softmax 函数进行归一化,使其形成一个有效的概率分布。这样,每个顶点都有一个对应的概率值,表示它被选为当前面顶点的概率。
-
-
选择顶点:
-
根据 softmax 归一化后的概率分布,选择一个顶点作为当前面的一个顶点。通常可以使用采样或选择概率最大的顶点的方式进行选择。
-
优势
-
适应可变大小输入:指针网络能够处理不同大小的输入顶点集合,因为它通过嵌入和点积操作将输入映射到固定维度的向量空间,从而避免了直接处理可变大小的输入矩阵。
-
高效性:指针网络通过点积和 softmax 操作直接在输入集合上形成一个有效的分布,避免了复杂的组合搜索过程,提高了生成效率。
-
准确性:通过学习输入顶点的嵌入表示和指针向量的生成,指针网络能够准确地捕捉顶点之间的关系,从而生成合理的网格面。

Embeddings. 与顶点模型类似,我们使用学习到的位置嵌入和值嵌入。我们将一个标记的位置分解为它所属面的索引,以及标记在面内的位置,分别使用不同的学习嵌入。对于值嵌入,我们遵循指针网络的方法,通过索引到顶点编码器输出的上下文顶点嵌入来简单地嵌入顶点索引。
2.4Masking Invalid Predictions
2.4 掩蔽无效预测
对于顶点和面模型,每一步中只有某些预测是有效的。例如, z 坐标必须单调递增,停止标记只能放在 x 坐标之后。类似地,网格面不能有重复的索引,并且每个顶点索引必须至少被一个面引用。在评估模型时,我们遮蔽预测的 logits,以确保模型只能做出有效的预测。这对模型的 log-likelihood 分数有非负影响,因为它将无效区域中的概率质量重新分配到有效区域(表 1)。令人惊讶的是,我们发现训练期间的遮蔽会导致性能略微下降,因此我们始终在不遮蔽的情况下进行训练。有关所使用的遮蔽的完整描述,请参见附录 F。
2.5Conditional Mesh Generation
2.5 条件网格生成
我们可以通过条件化上下文来指导网格顶点和面的生成。例如,我们可以输出与给定物体类别一致的顶点,或者推断与输入图像相关的网格。将顶点和面模型扩展到基于上下文 𝐡 是很直接的。我们根据输入域的不同,以两种方式整合上下文。对于类身份等全局特征,我们将学习到的类嵌入投影到一个向量中,该向量在块中每个自注意力层后的中间 Transformer 表示中相加。对于图像或体素等高维输入,我们联合训练一个适合域的编码器,该编码器输出一系列上下文嵌入。然后 Transformer 解码器对嵌入序列执行交叉注意力,就像原始机器翻译 Transformer 模型中一样。
对于图像输入,我们使用由一系列下采样残差块组成的编码器。我们采用预激活残差块(He 等人,2016 年),通过步长为 2 的卷积进行三次下采样,将大小为 [256,256,3] 的输入图像转换为大小为 [16,16,E] 的特征图,其中 E 是模型的嵌入维度。对于体素输入,我们使用类似的编码器,但采用 3D 卷积,将形状为 [28,28,28,1] 的输入转换为形状为 [7,7,7,E] 的空间嵌入。对于这两种输入类型,我们在展平空间维度之前向特征图中添加坐标嵌入。有关更多架构细节,请参见附录 C。
我们比较了在不同条件下训练的无条件模型。作为评估指标,我们报告了模型获得的负对数似然,以比特每顶点为单位,以及下一步预测的准确率。对于顶点模型,这是下一步顶点坐标预测的准确率;对于面模型,这是下一步顶点索引预测的准确率。具体而言,我们比较了掩码无效预测(第 2.4 节)、在顶点模型中使用离散坐标嵌入而非连续坐标嵌入(第 5 节)、使用数据增强(第 3.2 节),以及最终在面模型中使用交叉注意力的影响。除非另有说明,我们使用 256 维的嵌入、1024 维的全连接层,以及分别为顶点模型和面模型使用 18 个和 12 个 Transformer 块。由于目前没有直接对网格顶点和面进行建模的方法,我们报告了在整个数据域分配均匀概率的模型以及在整个有效预测区域均匀分布的模型的得分。此外,我们还报告了网格压缩库 Draco(Google,)获得的压缩率。 有关 Draco 压缩设置的详细信息,请参见附录 G
图 7 展示了 PolyGen 样本以及真实数据分布的网格摘要的分布情况。具体而言,我们展示了:采样网格和真实网格的顶点数、面数、节点度数、平均面面积和平均边长。尽管这些是对 3D 网格的粗略描述,但我们发现我们模型的样本在每种网格统计量上都具有相似的分布。我们观察到,使用 top-p=0.9 的核采样有助于使模型分布与真实数据在多个统计量上保持一致。图 8 展示了我们模型生成的 3D 网格示例,并与通过后处理占用函数(Mescheder 等人,2019)获得的网格进行了比较。我们注意到,我们网格的统计量在更大程度上类似于人工创建的网格。

表 3 展示了条件化对预测性能的影响,包括每个顶点的比特数和准确率。我们发现,对于顶点模型,体素条件化提供了最大的改进,其次是图像,然后是类别标签。这符合我们的预期,因为体素能够明确地表征粗略形状,而图像则可能因物体姿态和光照的不同而具有不确定性。然而,对于人脸模型,额外的上下文并未带来改进,所有条件化的人脸模型的表现都略差于最佳无条件模型。这可能是由于网格面在很大程度上由输入顶点决定,而条件化上下文提供的额外信息相对较少。在预测准确率方面,我们观察到相似的效果,顶点模型的准确率随着更丰富的上下文而提高,但人脸模型则不然。我们注意到,由于顶点和面分布的固有熵,准确率的上限小于 100% ,因此随着模型接近这一上限,我们预期收益会逐渐减少。
体素(Voxel)是三维空间中的基本单元,类似于二维图像中的像素(Pixel)。像素用于表示二维图像的最小单位,而体素则是用于表示三维物体或空间的基本单位。在三维建模、计算机图形学、医学成像和3D 打印等领域中,体素是一个重要的概念。
体素的基本定义
-
体素是一个三维空间中的立方体单元,它具有特定的坐标位置和大小。通常,体素可以表示为一个包含位置信息(如 x、y、z 坐标)和属性值(如密度、颜色、材料等)的三维数据元素。
-
体素是构建复杂三维物体或场景的基本组成部分,通过集合大量的体素,可以近似表示出复杂的三维形状和结构。
体素化形状和过程
-
在三维物体建模中,体素化是将连续的三维形状或物体离散化为体素表示的过程。具体来说,就是将三维空间划分为规则的网格,每个网格单元对应一个体素,然后根据物体的形状和位置,确定哪些体素属于物体内部,哪些属于外部。
-
体素化过程通常涉及到采样和量化操作。采样是指在三维空间中按照一定的间隔和规则选取样本点,量化则是将连续的属性值映射到有限的离散值范围,以便用体素来表示。
体素在 3D 建模中的应用
-
在 3D 建模中,体素表示是一种常见的表示方式,特别是在需要进行体积建模、物理模拟或复杂形状生成时。由于体素可以方便地表示物体的内部结构和形状,因此在医学成像、地质建模、3D 打印等领域得到了广泛应用。
-
例如,在医学成像中,CT 扫描或 MRI 扫描会生成大量的体素数据,每个体素表示人体内部某个小立方体区域的物理属性(如密度、灰度值等),通过这些体素数据可以重建出人体内部的三维结构。
-
在 3D 建模软件中,体素化工具可以帮助艺术家和设计师快速创建复杂的几何形状,通过简单的体素操作(如添加、删除、移动等)来构建出复杂的 3D 模型。
体素的优点和局限性
-
优点是能够表示三维物体的内部结构,在处理体积数据和复杂形状时具有优势,同时体素化后的数据便于进行数学运算和物理模拟。
-
局限性在于体素化后的模型具有较大的数据量,存储和处理效率相对较低,而且在表示精细表面细节时可能会出现锯齿状或块状伪影。
体素是三维空间中的基本单元,是体素化形状表示的基础。它在三维建模、计算机图形学、医学成像和 3D 打印等领域中发挥着重要作用。


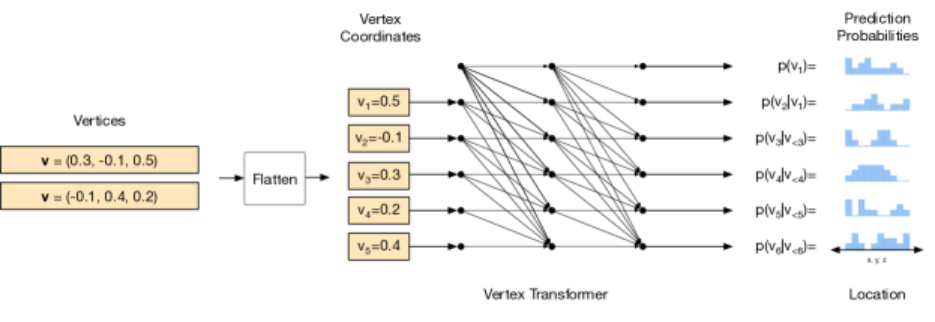
图 12 展示了一个顶点模型的结构,该模型是一个带掩码的 Transformer 解码器。以下是对图中各部分的详细解释:
输入部分
-
Vertices(顶点) :这是模型的输入顶点数据,每个顶点由其坐标表示。图中给出了两个顶点的例子:
-
第一个顶点 v1 的坐标是 (0.3,−0.1,0.5)
-
第二个顶点 v2 的坐标是 (−0.1,0.4,0.2)
-
-
Flatten(展平操作) :将顶点的坐标序列展平成一个一维的序列。展平后的序列为 [0.3,−0.1,0.5,−0.1,0.4,0.2],其中每个元素依次对应第一个顶点的 x、y、z 坐标,然后是第二个顶点的 x、y、z 坐标。
Transformer 解码器部分
-
Vertex Transformer(顶点 Transformer) :Transformer 解码器处理展平后的序列。它包含多头自注意力机制(图中用多个线条连接不同的节点表示),能够捕捉序列中不同位置元素之间的关系。由于是带掩码的 Transformer 解码器,在计算自注意力时会使用掩码,确保在预测序列中第 n 个位置的元素时,只能依赖前面的元素(即 v1 到 vn−1),而不能看到后面位置的元素。
输出部分
-
Prediction Probabilities(预测概率) :Transformer 的输出是对各个坐标位置的预测概率分布。对于序列中的每个位置,模型输出一个概率分布,表示该位置可能的坐标值,以及一个停止标记 s 的概率。图中显示了不同位置的预测概率分布,例如:
-
p(v1=) 表示第一个位置坐标的预测概率分布。
-
p(v2∣v1=) 表示在给定第一个位置坐标 v1 的情况下,第二个位置坐标 v2 的预测概率分布。
-
-
Location(位置) :表示坐标的位置信息,即 x、y、z。模型对每个位置的预测都对应着这三个坐标轴上的值。
这种结构的顶点模型能够基于已经生成的顶点信息,自回归地预测下一个顶点的坐标,直到生成停止标记 s,表示顶点序列生成结束。通过这种方式,模型可以生成整个顶点序列,为后续生成网格的面提供基础。
模型确实能够正确地将拆分开的 x、y、z 坐标重新组合成完整的顶点信息,这主要依赖于以下几个关键机制:
序列位置信息
-
在将顶点坐标展平成序列时,模型会保留每个坐标的原始顺序。例如,第一个顶点的 x、y、z 坐标会依次出现在序列的前三个位置,第二个顶点的坐标紧随其后,以此类推。这种顺序为模型提供了重要的位置线索。
-
当模型处理这个序列时,它会根据位置信息来识别哪些 x、y、z 坐标属于同一个顶点。例如,模型知道序列中第 1、2、3 个位置分别对应第一个顶点的 x、y、z 坐标,第 4、5、6 个位置对应第二个顶点的坐标,依此类推。即使坐标被拆分,模型也能通过位置信息将它们重新组合成完整的顶点。
自回归生成机制
-
顶点模型采用自回归的方式生成顶点序列。在生成过程中,模型在每一步都会根据之前已生成的坐标来预测下一步的坐标。
-
由于模型是逐步生成坐标的,它在生成第一个顶点的 x 坐标后,会继续生成该顶点的 y 和 z 坐标,然后再开始生成下一个顶点的坐标。这种自回归机制使得模型能够保持对当前正在生成的顶点的上下文理解,从而正确地关联属于同一个顶点的 x、y、z 坐标。
Transformer 的自注意力机制
-
Transformer 架构中的自注意力机制能够捕捉序列中不同位置元素之间的关系。即使坐标被拆分,自注意力机制也能在处理序列时,识别出哪些 x、y、z 坐标是相互关联的,属于同一个顶点。
-
自注意力机制通过计算序列中每个位置与其他位置的相关性,为模型提供了全局的上下文信息。这使得模型能够在生成过程中,综合考虑之前生成的所有坐标,以确定当前正在生成的坐标属于哪个顶点,并保持顶点信息的完整性。
模型训练过程中的监督学习
-
在模型训练阶段,使用的是带有完整顶点信息的标注数据。模型通过学习这些数据,逐渐了解到 x、y、z 坐标之间的关联以及它们如何组合成完整的顶点。
-
训练过程中,模型会不断调整其参数,以最小化预测值与真实值之间的差异。这使得模型在学习如何生成坐标的同时,也学会了如何正确地将拆分的坐标重新组合成顶点。通过这种方式,模型在训练完成后,具备了将拆分的坐标重新组合成完整顶点的能力。
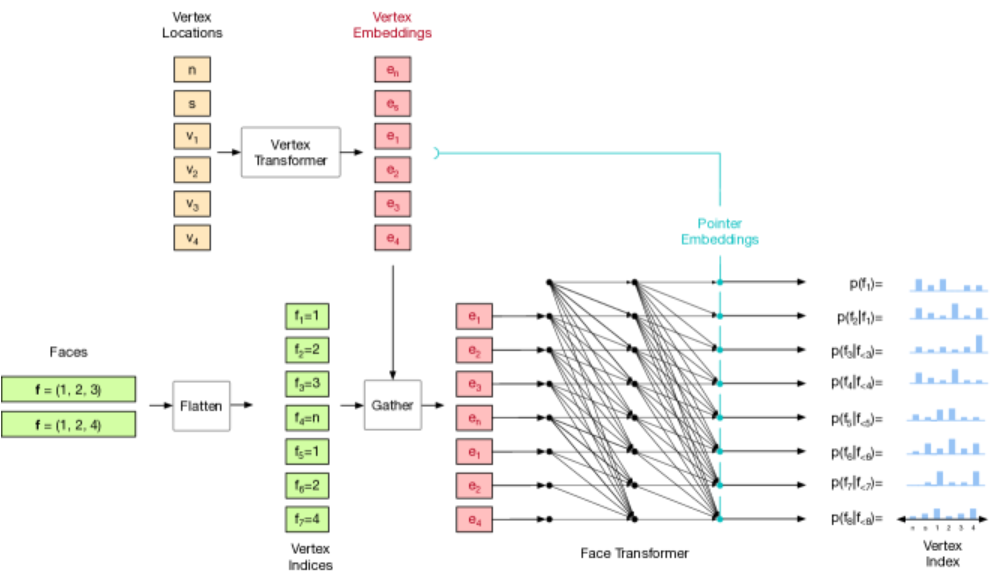
图 13:面模型在顶点输入集以及描述面的扁平化顶点索引上运行。首先,顶点、新的面标记 n 和停止标记 s 通过 Transformer 编码器进行嵌入。然后使用收集操作来识别与每个顶点索引相关联的嵌入。索引嵌入通过掩码 Transformer 解码器进行处理,以在每个步骤中输出顶点索引的分布,以及下一个面标记和停止标记的分布。Transformer 的最后一层输出指针嵌入,这些嵌入通过与顶点嵌入进行点积比较来产生所需的分布。有关面模型的详细描述,请参阅第 2.3 节;有关指针网络机制的详细描绘,请参阅图 5。
图 13 展示了一个用于生成网格面的模型结构,该模型基于输入的顶点集合和面的顶点索引。以下是图中各部分的详细解释:
输入部分
-
Vertex Locations(顶点位置) :这是输入的顶点坐标,每个顶点由其 x、y、z 坐标表示。图中显示了顶点 v1、v2、v3、v4 的位置。
-
Faces(面) :输入的面信息,每个面由指向顶点集合中顶点的索引组成。例如,图中的面 f=(1,2,3) 和 f=(1,2,4) 表示两个面,分别由顶点索引 1、2、3 和 1、2、4 组成。
-
Flatten(展平操作) :将面的索引序列展平成一个一维的序列。例如,面 f=(1,2,3) 和 f=(1,2,4) 展平后变为序列 [1,2,3,1,2,4]。
嵌入部分
-
Vertex Transformer(顶点 Transformer) :顶点 Transformer 的作用是将顶点位置嵌入到一个高维空间中,生成顶点嵌入 e1,e2,e3,e4。这些嵌入捕捉了顶点的特征信息,为后续的面生成提供基础。
-
Vertex Embeddings(顶点嵌入) :顶点嵌入是顶点 Transformer 的输出,表示每个顶点的特征向量。
面处理部分
-
Gather(收集操作) :收集操作根据展平后的面索引序列,从顶点嵌入中提取相应的嵌入。例如,对于索引序列 [1,2,3,1,2,4],收集操作会提取顶点嵌入 e1,e2,e3,e1,e2,e4。
-
Face Transformer(面 Transformer) :面 Transformer 是一个带掩码的 Transformer 解码器,用于处理收集到的顶点嵌入序列。它输出关于各个顶点索引的预测概率分布,以及下一个面标记和停止标记的分布。
输出部分
-
Pointer Embeddings(指针嵌入) :面 Transformer 的最后一层输出指针嵌入。这些指针嵌入通过与顶点嵌入进行点积比较,生成关于顶点索引的分布。
-
Prediction Probabilities(预测概率) :模型输出每个位置的顶点索引的预测概率分布,以及面标记和停止标记的分布。例如,p(f1=) 表示第一个面索引的预测概率分布。
工作流程
-
顶点嵌入 :顶点位置通过顶点 Transformer 转换为顶点嵌入。
-
面索引处理 :面的索引序列被展平,并通过收集操作从顶点嵌入中提取相应的嵌入。
-
面生成 :面 Transformer 处理收集到的嵌入序列,输出指针嵌入和预测概率分布。
-
指针网络 :指针嵌入与顶点嵌入进行点积比较,并通过 softmax 归一化,生成关于顶点索引的分布,用于选择下一个顶点索引。
这种结构使得模型能够根据输入的顶点集合,自回归地生成面的顶点索引,从而构建出完整的网格面。通过指针网络机制,模型能够有效地处理可变大小的顶点集合,并生成合理的面结构。

点模型和面模型在处理输入数据时的需求不同,这导致了它们在是否使用 embedding(嵌入)层上存在差异。
顶点模型不使用 embedding 的原因
-
直接处理连续坐标值:顶点模型直接处理的是顶点的坐标值(如 x、y、z),这些坐标值是连续的数值型数据。模型需要根据这些连续值的大小、范围等信息来预测下一个顶点的位置。使用 embedding 对连续的坐标值进行嵌入可能会丢失坐标值本身的数值意义,不利于模型对顶点位置的精准预测。
-
自回归生成的特点:顶点模型采用自回归的方式生成顶点序列,即每一步生成的顶点坐标依赖于前面已经生成的坐标。直接处理连续的坐标值可以让模型更好地捕捉坐标之间的数值关系和空间分布特点,从而更准确地生成合理的顶点序列。
面模型需要顶点 embedding 的原因
-
处理离散的顶点索引:面模型处理的是顶点的索引,这些索引是离散的类别型数据,表示面由哪些顶点组成。离散的索引本身不包含顶点的坐标信息,也无法直接用于计算。因此,需要通过 embedding 将这些离散的索引映射到一个高维的连续空间中,使其能够被模型有效地处理和分析。
-
捕捉顶点的语义信息:通过对顶点进行 embedding,可以将顶点的坐标信息以及其他相关特征编码到嵌入向量中。这样,面模型在处理顶点索引时,能够利用这些嵌入向量捕捉到顶点之间的语义关系和空间结构信息,从而更好地生成合理的面结构。
-
指针网络的需求:面模型通常使用指针网络来输出顶点索引的分布。指针网络需要将顶点的嵌入向量与指针向量进行比较,以确定选择哪个顶点作为当前面的一个顶点。顶点的 embedding 为指针网络提供了顶点的特征表示,使得指针网络能够有效地计算顶点与指针向量之间的相似性,进而输出合理的分布。





















 173
173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









