







论文:Video Enhancement for Underwater Exploration Using Forward Looking Sonar Video
Abstract
机器人技术和成像技术的进步为新环境的无人探索领域带来了各种成像设备。前视声纳是一种新兴的水下环境探测成像技术。由于前视声纳系统产生的视频序列具有低信噪比、低分辨率和视野范围有限的特点,因此期望视频增强技术能够促进视频序列的解释。因为前视声纳视频序列的视频增强技术适用于大多数前视声纳序列,且光学摄像机视频增强技术只有专门制作的视频序列才能受益,所以开发前视声呐视频序列的视频增强技术比开发光学摄像机视频增强技术更为关键。在本文中,我们介绍了一种程序,以增强前视声纳视频序列通过合并的知识,获得的目标物体在先前的观察帧。该方法包括帧间配准、图像强度线性化和视频序列中图像的最大后验融合。通过增强双频识别声纳(DIDSON)的视频序列来验证该程序的性能,DIDSON是市场领先的前视声纳系统。
Introduction
前视声纳是一种通过叠加由一维换能器阵列产生的一维图像来产生二维图像的声纳。与传统声纳不同,前视声呐的波束形成是自发实现的,无需额外的计算,因此它可以以与光学摄像机相当的帧速率产生相对高分辨率的图像。
其优点是高帧率、相对较高的分辨率、低功耗和便携性,但与光学相机相比仍有不足之处:首先,角度分辨率相对较低,通常小于100像素;其次,由于b扫描图像的特性,其信噪比仍然低于光学相机。
Scope of Applicable Video Sequences
基于超分辨率技术的视频增强算法基本上由三部分组成:1) registration配准,2) transformation变换,3)fusion融合。
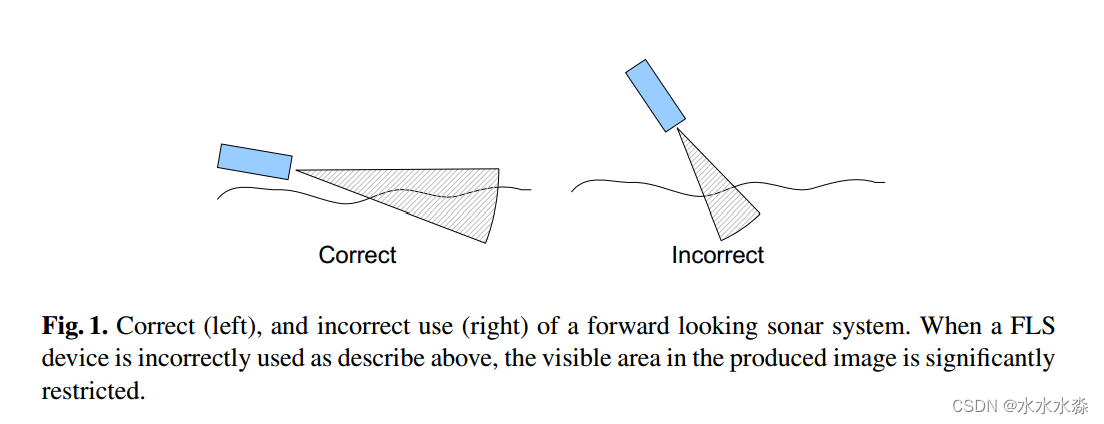
对于图像配准,需要根据成像设备的成像几何形状对图像间的单应性进行建模。大多数光学相机图像增强方法使用透视单应性或类似的低层次单应性,如仿射单应性。然而,投影单应性要求目标物体是一个平面,或者相机只进行旋转运动而不进行平移运动。对于光学摄像机来说,大多数有意制作的视频序列都能满足这一要求。而从图像采集层面上看,前视声呐要求目标物体在一个平面上,会导致声纳的可见性非常狭窄,输出图像有明显的渐晕(见图1)。这一特性对前视声呐的可变性施加了巨大的限制,因此仿射变换可以解释大多数FLS视频序列。
对于图像融合,为了将多帧光学摄像机视频序列组合在一起,需要一个没有遮挡的视频序列。FLS视频序列的另一个优点是,只要遮挡是静态的,融合方法就可以容忍遮挡。在FLS图像中,一个区域在被遮挡时变暗,一旦脱离遮挡就会恢复原来的亮度。这只是光照的改变,这比光学摄像机视频增强中的遮挡排除问题要容易处理得多。
Methodology
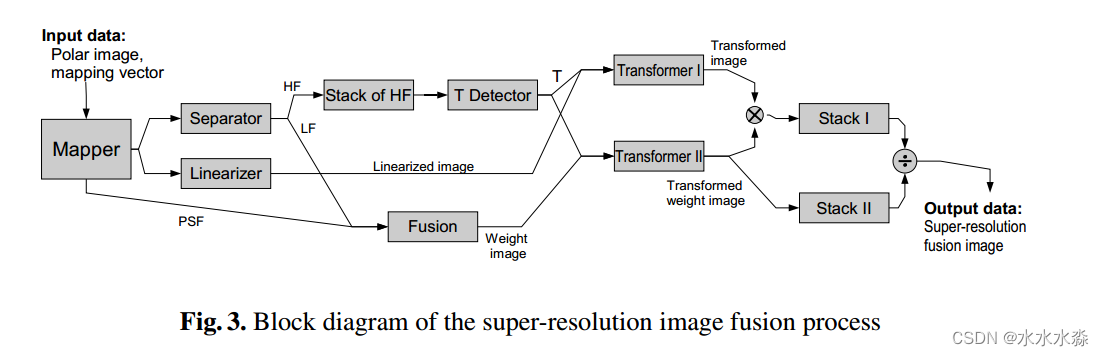 该方法主要由以下几个步骤组成:
该方法主要由以下几个步骤组成:
1) separation of illumination profile 光照轮廓的分离;
2) inter-frame image registration 帧间图像的配准;
3)linearization of brightness 亮度的线性化;
4)maximum a posteriori (MAP) fusion of images 图像的最大后验融合。
步骤1)
在步骤1)中,将图像分为高频部分和低频部分。
因为照明仅取决于从设备本身入射的超声波束。FLS装置的掠射角和目标表面曲率的微小变化都会引起光照条件的变化,最终给配准和融合带来困难。出于这个原因,需要将目标物体的照度剖面与反射率剖面分开,对于FLS图像,对图像进行简单的同态滤波就足以实现分离,见下式。
HF(x)=I(x)/LF(x)
式中I(x)、LF(x)、HF(x)分别表示原图像x位置、低频部分和高频部分的强度值。低频部分通过对图像进行低通滤波得到,作者认为LF和HF分别是照度剖面和反射率剖面。
步骤2)
在步骤2)中,在两个相邻帧之间和帧之间进行配准。将其中找到的配准参数进行最优组合,以最小化配准误差的累积。
即使在两帧之间获得亚像素精度的配准,仍然存在一个问题,即在视频序列中注册多帧时累积的配准误差。此外,FLS图像的配准是基于单应性的仿射近似,而不是精确的几何模型,配准误差的积累会导致配准误差更大。作者针对这一问题,对配准参数进行了调整。
最小化配准误差的理想条件是当视频序列中的所有帧一致地彼此配准时。然而,在大多数情况下,由于摄像机处于运动状态,目标区域的视图在图像采集过程中会发生变化,因此大多数帧只能与其相邻的少数帧进行配准。作者提出了一种算法来确定一帧可以配准多少相邻帧(称为“锚帧”),具体代码以及步骤如下:
anchor frame = 1
for current frame = 2:
end of sequenceRegister current frame with anchor frame.
if anchor frame != current frame-1,
Register current frame with current frame-1.
end if
if the registration above fails,
Optimize valid transformation parameters
between anchor frame and current frame-1.
reset anchor frame = current frame
else if current frame-anchor frame == predefined number,
Optimize transformation parameters until
between anchor frame and current frame.
Reset anchor frame = current frame + 1.
end if
end for将感兴趣序列的第一帧设置为锚帧(step1),并将以下帧与锚帧(step3)以及它们的前一帧(step5)进行配准,直到任何配准失败(step7)。当确定锚帧的可配准部分的大小(step7)时,计算最优的变换参数集,以最小的误差(step8)解释该部分中所有帧的单应性。在此优化步骤之后,继续移动到视频序列的剩余部分,锚帧被重置为剩余部分的一节的第一帧,直到到达序列的末尾(step9)。为了防止优化中的维数过大,在允许的计算能力下达到所需的进程延迟,并满足图像增强的所需性能,对可配准部分的最大尺寸进行了限制(step10)。
变换参数的优化是通过最小化定义为的能量函数来实现的,见下式:
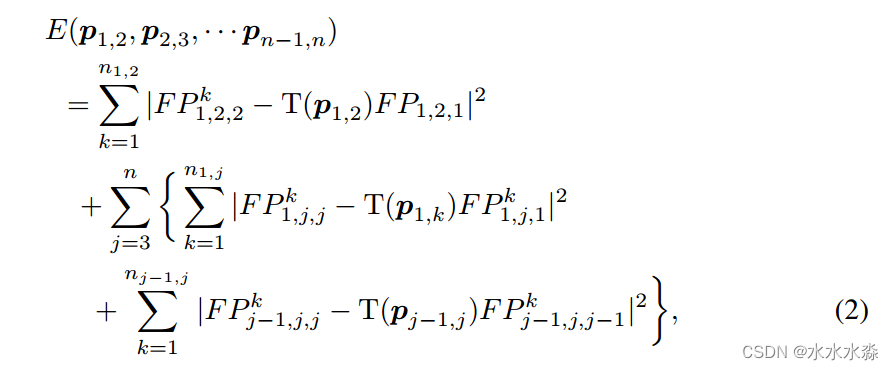
式中,n为锚帧可配准部分的帧数,n(p,q)为第p帧和第q帧配准的内层特征点对的个数。FP(k;p,q,r)是在第r帧中找到的第p和第q帧的配准的第k个内层特征点对的位置向量,T[p(p,q)]是由配准参数p(p,q)定义的变换算子。对于任意两个非连续的帧数i和j,将第i帧和第j帧之间的连续帧的所有变换参数相加,得到p(i,j),如p(i,i+1),···,p(j−2,j−1),p(j−1,j)。
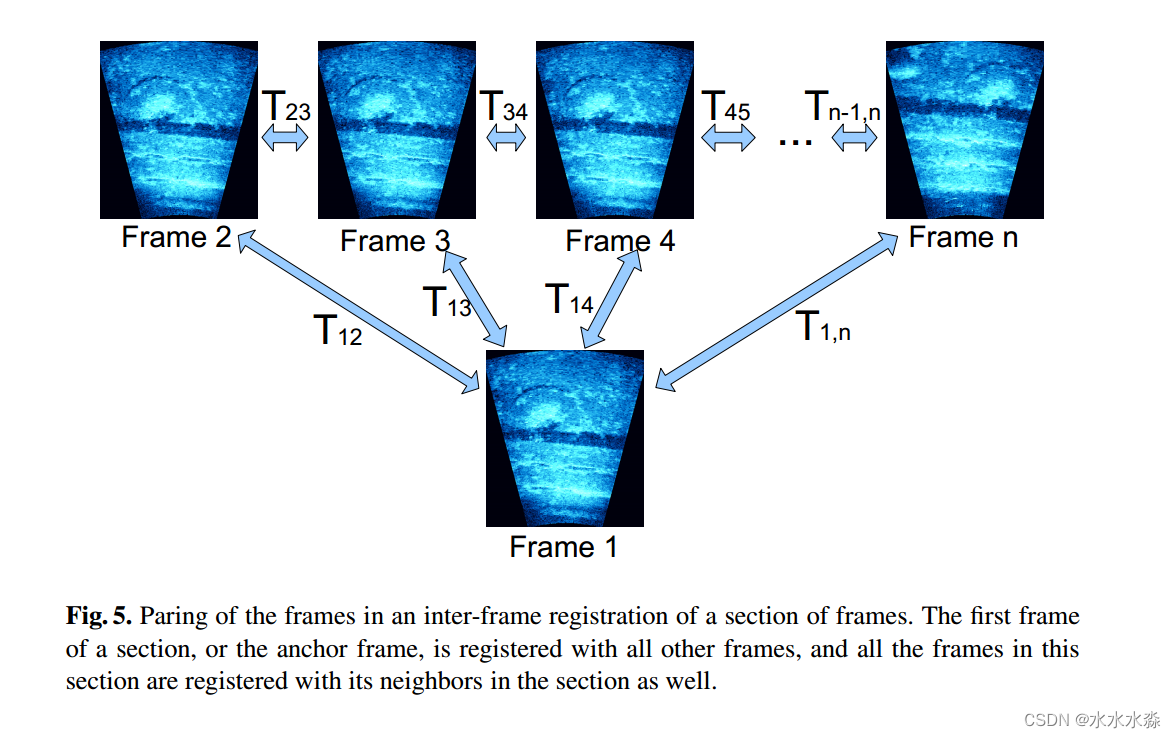
图5:在帧的一段的帧间配准中对帧进行裁剪。一节的第一帧或锚帧与所有其他帧配准,并且该节中的所有帧也与其在该节中的相邻帧配准。
步骤3)
在步骤3)中,对图像的图像强度进行线性化,以便在下一步骤中对序列进行最大的后验融合。
对于DIDSON图像,以下线性化函数可以显著提高融合质量:
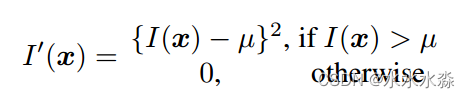
I(x)、μ和I`(x)分别表示位置向量x处的强度、平均背景噪声电平和x处的线性化强度。
步骤4)
在步骤4)中,将先前观察到的帧融合成一幅图像,以最好地呈现当前显示的帧。
基于一组低质量观测图像的图像的最大后验估计可以通过对低质量图像的加权融合来近似。这意味着可以执行MAP图像融合,而无需许多超分辨率算法所需的迭代计算。此外,该方法在非均匀光照条件下具有较强的鲁棒性。FLS视频序列中的帧增强是通过使用MAP融合将预定义数量的帧融合到所需的视角中来实现的;当融合N幅低分辨率图像β1、···、βN时,
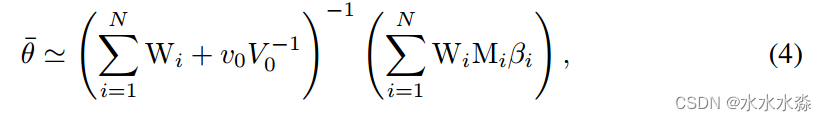
其中θ、Wi、Mi和v0V(-1;0)分别表示计算得到的MAP融合图像、第i个可靠性矩阵、第i个上采样矩阵和正则化因子。
Results 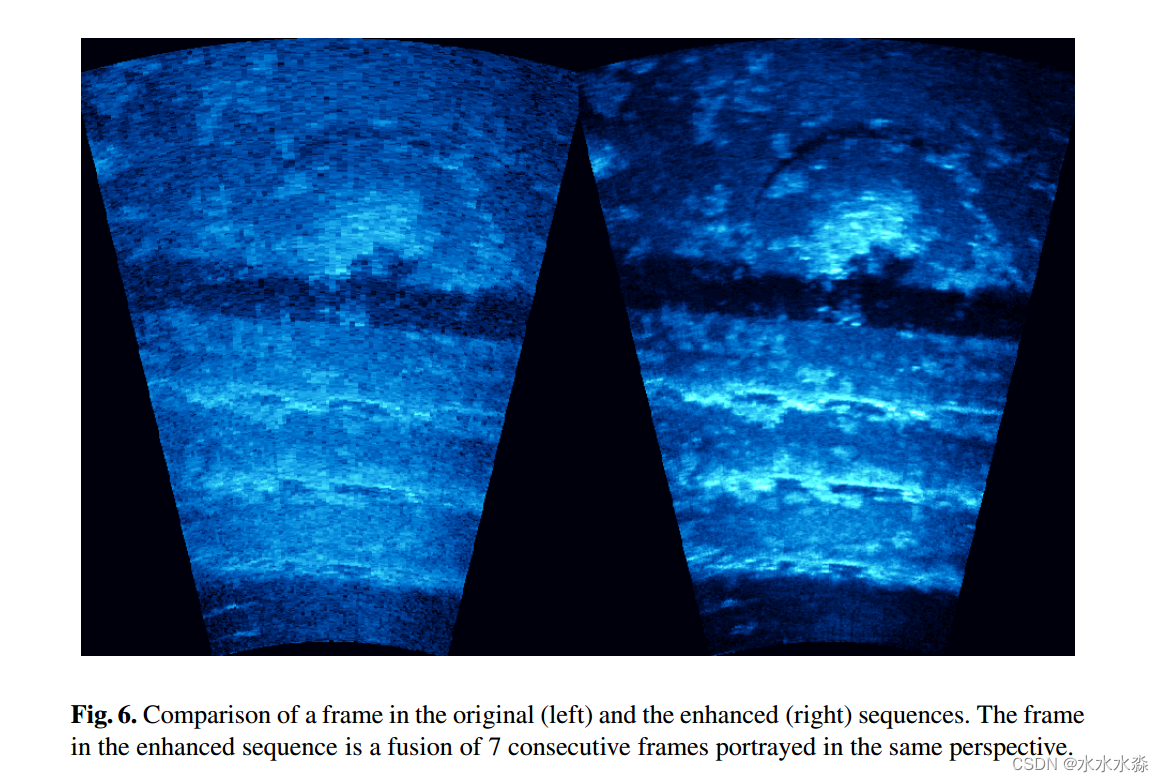
图6是原始序列中的一个帧与增强序列中的一个帧的比较,在增强序列中,多达7个相邻帧被融合以重新呈现一个帧。在图6中,可以验证融合图像(右)比原始图像(左)更清晰地揭示了目标物体的边缘。还需要注意的是,在原始序列中难以识别的表面纹理在增强序列中可以很容易地识别,因为噪声水平降低了,分辨率增加了。
Conclution
本文提出了一种增强前视声纳视频序列的方法。该过程包括光照轮廓的分离、帧间配准、图像的线性化以及图像的非迭代最大后验融合以实现超分辨率。
由于FLS的图像采集方法限制了适用的目标物体在平面上,因此大多数FLS图像可以使用简单的仿射单应性进行配准。此外,在处理光学视频序列时经常遇到的障碍遮挡问题,可以简单地看作是FLS视频序列中的照明问题,处理起来比较容易。这意味着无需进一步考虑FLS视频序列中的遮挡问题。由于这些原因,一般来说,FLS视频增强技术适用于大多数FLS视频序列。
本文提出的视频增强过程主要由四个步骤组成,分别是照度轮廓的分离、通过帧间图像配准对配准参数进行微调、亮度的线性化以及图像的最大后验融合。所有这些步骤都可以在较低的计算能力下实现。


















 956
956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











