






前言
近年来,多模态大型语言模型(MLLM)的快速发展,为人工智能在图像、文本等多模态信息理解和处理方面带来了前所未有的突破。然而,现有的主流多模态模型多以英文为训练语言,在中文理解和处理方面存在着明显的短板,难以满足日益增长的中文多模态应用需求。为了弥补这一缺陷,OpenGVLab 团队开源了首个中文原生多模态模型 InternVL-Chat-V1-5,旨在为中文多模态领域的发展贡献力量。
-
Huggingface模型下载:https://huggingface.co/OpenGVLab/InternVL-Chat-V1-5
-
AI快站模型免费加速下载:https://aifasthub.com/models/OpenGVLab
技术特点
InternVL-Chat-V1-5 在技术上具有以下突出特点,使其在中文多模态领域展现出了领先优势:
-
中文原生训练,深度理解中文语境
InternVL-Chat-V1-5 采用海量中文数据进行训练,使其对中文语境和文化元素有着更深层的理解,能够生成更符合中文审美和文化意蕴的图像,并更精准地理解中文文本。训练数据涵盖了超过十万个中文类别,包括人物、风景、植物、动物、物品、交通工具、游戏等等,并覆盖了数百种艺术风格,例如动漫、3D、绘画、写实、传统风格等等。
为了确保训练数据的质量,OpenGVLab 团队构建了从数据获取、数据清洗、数据标注到数据应用的完整数据处理流程,并设计了 “数据护航” 机制,不断优化数据质量,提升模型的生成能力。训练数据中包含了大量的图像-文本对,以及专门为中文 OCR 任务构建的大规模数据集,例如 Wukong-OCR 和 LaionCOCO-OCR 等,这些数据帮助模型学习了丰富的中文视觉信息和文字识别能力。
-
支持 4K 分辨率,打破图像分辨率限制
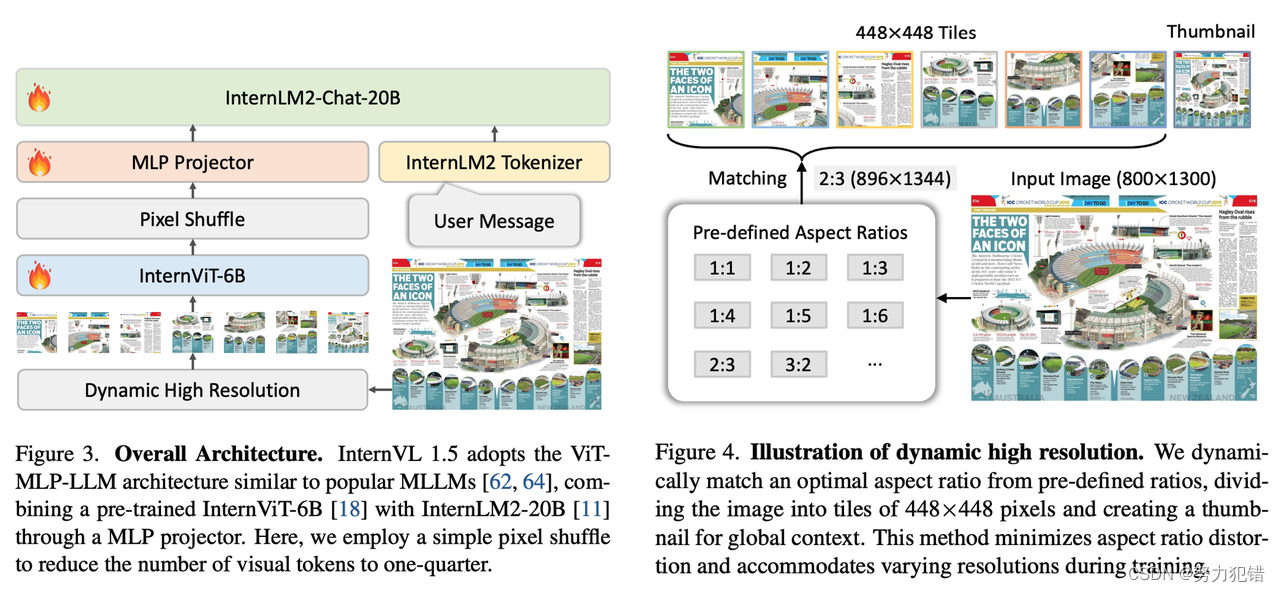
InternVL-Chat-V1-5 采用了一种动态高分辨率训练策略,能够处理高达 4K 分辨率的图像。相比其他模型只能处理固定分辨率的图像,InternVL-Chat-V1-5 可以根据图像的尺寸和长宽比,将图像分割成多个 448x448 像素的图像块,并在推理阶段将这些图像块进行拼接,最终生成完整的图像。 这种策略不仅能够提高模型对高分辨率图像的理解能力,还能有效保留图像的细节信息,避免图像失真。
InternVL-Chat-V1-5 的这种动态分辨率策略类似于 GPT-4V 的 “低分辨率” 和 “高分辨率” 模式,用户可以根据图像内容选择合适的分辨率。例如,对于简单的场景描述,可以使用低分辨率,而对于需要精确理解细节的文档图像,则可以使用高达 4K 的高分辨率。
-
中英双语支持,打破语言壁垒
除了中文,InternVL-Chat-V1-5 还支持英文提示词,实现中英双语的图像生成和文本理解,为用户提供更便捷的操作体验。模型采用了一种结合双语 CLIP 和多语言 T5 编码器的策略,提升语言理解能力,同时能够处理更长的文本提示词。
InternVL-Chat-V1-5 采用 InternViT-6B 作为视觉基础模型,并对其进行了持续学习,使其具备了更强大的视觉理解能力,能够适应不同的语言模型。同时,模型还使用了 InternLM2-20B 作为语言基础模型,使其拥有了强大的语言处理能力。
性能表现
InternVL-Chat-V1-5 在多个方面展现出了优异的性能,在中文多模态领域取得了领先优势:
-
中文理解能力显著提升
与其他开源模型相比,InternVL-Chat-V1-5 在中文理解能力方面有着显著提升,能够准确理解中文提示词,生成更符合语境的图像。例如,对于“繁华的夜市”这一提示词,InternVL-Chat-V1-5 生成的图像展现了喧闹、热闹的夜市景象,而其他开源模型则可能生成较为抽象或不够贴近生活的图像。
-
图像质量超越开源模型
根据内部测试,InternVL-Chat-V1-5 在图像一致性、剔除 AI 伪影、主题清晰度和美学评分等方面均取得了领先优势。 在专业评估团队的评价中,InternVL-Chat-V1-5 在文本图像一致性、剔除 AI 伪影、主题清晰度和美学评分等方面均超过其他开源模型。例如,在生成“古代中国诗词”相关的图像时,InternVL-Chat-V1-5 能够生成具有更高图像质量和语义准确度的图像,展现出对中国文化的理解能力。
-
8项指标超越商业模型,性能媲美 GPT-4V
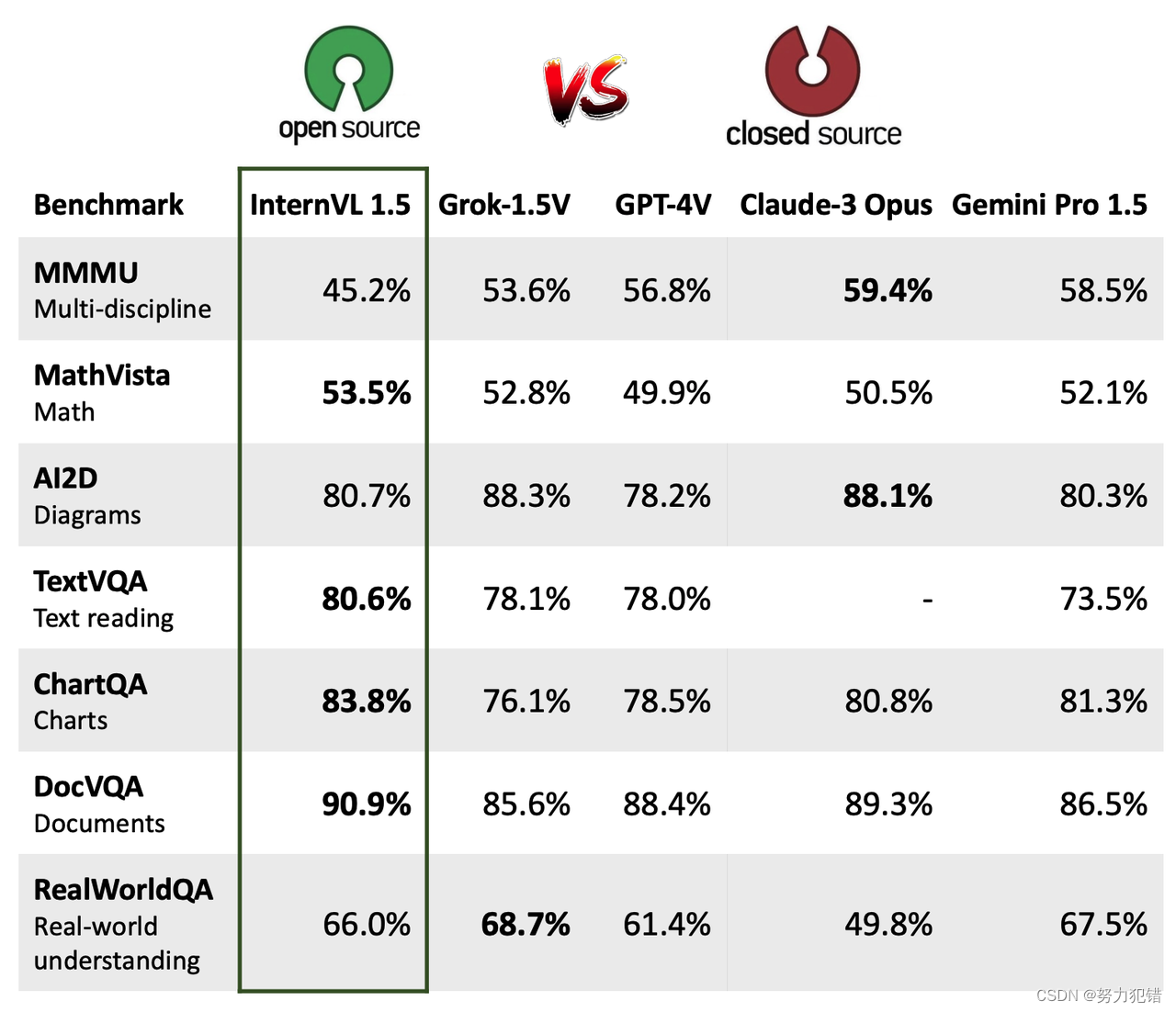
InternVL-Chat-V1-5 在 18 项多模态任务基准测试中,取得了 8 项的领先成绩,与 GPT-4V 的性能相当,在部分测试中甚至超过了 GPT-4V。例如,在 DocVQA、ChartQA、InfographicVQA 和 OCRBench 等 OCR 相关任务中,InternVL-Chat-V1-5 表现突出,证明了其在处理中文文本识别和理解方面具有强大的实力。
InternVL-Chat-V1-5 在 ConvBench 多轮对话评估基准测试中也展现出了不俗的成绩,其在感知、推理和创造力方面都取得了领先优势,显示出其在多轮对话场景中的应用潜力。

应用潜力
InternVL-Chat-V1-5 在多个领域具有广泛的应用潜力,可以为用户提供更便捷、更具创意的创作体验:
-
创意设计:用户可以利用 InternVL-Chat-V1-5 生成各种创意图像,例如海报、插画、产品设计图等,帮助设计师快速完成创作,提升工作效率。
-
内容创作:InternVL-Chat-V1-5 可以帮助用户快速生成各种内容素材,例如游戏场景、电影场景、广告图片等,为内容创作者提供更丰富的创作工具。
-
教育娱乐:InternVL-Chat-V1-5 可以用于制作教材、游戏、动画等,为教育娱乐领域提供更具创意和吸引力的内容。
总结
InternVL-Chat-V1-5 的开源标志着中文多模态领域迈上了新的台阶,为中文多模态模型的发展提供了重要参考。随着技术的不断进步,相信未来 InternVL-Chat-V1-5 会在更多领域发挥重要的作用,为人们的生活带来更多的便利和乐趣。
模型下载
Huggingface模型下载
https://huggingface.co/OpenGVLab/InternVL-Chat-V1-5
AI快站模型免费加速下载
https://aifasthub.com/models/OpenGVLab

















 3026
3026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









