






前言
文本嵌入模型能够将文本信息转化为稠密的向量表示,并在信息检索、语义相似度计算、文本分类等众多自然语言处理任务中发挥着关键作用。近年来,基于解码器的大型语言模型 (LLM) 开始在通用文本嵌入任务中超越传统的 BERT 或 T5 嵌入模型,展现出更强的语义理解能力和更灵活的应用潜力。
-
Huggingface模型下载:https://huggingface.co/nvidia/NV-Embed-v1
-
AI快站模型免费加速下载:https://aifasthub.com/models/nvidia

技术特点
英伟达近期推出了全新开源模型 NV-Embed,旨在提升解码器 LLM 的嵌入能力,使其成为更强大的通用嵌入模型。NV-Embed 结合了独特的架构设计和训练方法,在性能上取得了突破性的进展,主要体现在以下几个方面:
-
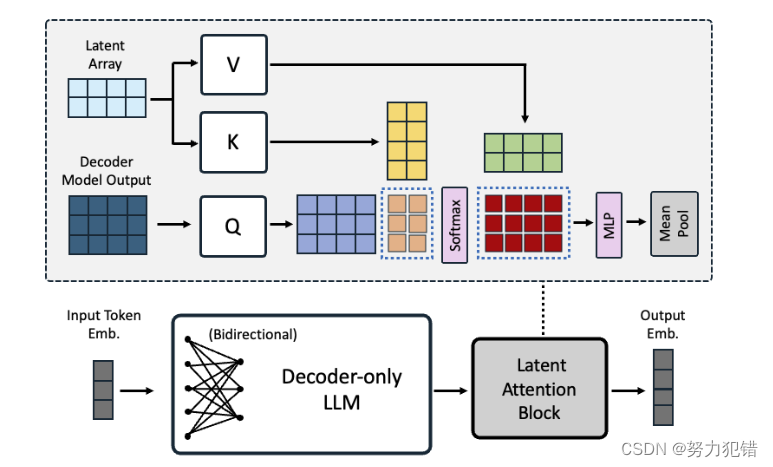
双向注意力: 传统解码器 LLM 为了预测下一个词,采用了因果注意力机制,限制了模型对整个文本的理解能力。NV-Embed 巧妙地移除了因果注意力机制,采用双向注意力机制,使模型能够同时关注文本中的所有词语,从而提升文本表示的质量。
-
潜在注意力层: 为了更有效地对文本进行池化,获取更具表达力的文本表示,NV-Embed 引入了潜在注意力层。该层通过与可训练的潜在数组进行交叉注意力,对文本序列进行重新编码,并通过多层感知器 (MLP) 进一步优化表示。
-
两阶段指令微调: 为了使模型在检索和非检索任务 (例如分类、聚类) 上都表现出色,NV-Embed 采用了两阶段指令微调方法。第一阶段,模型在检索数据集上进行对比训练,利用批内负样本和人工筛选的困难负样本进行优化。第二阶段,将精心选择的非检索数据集加入到第一阶段的训练数据中,并关闭批内负样本训练。这种策略不仅提高了非检索任务的准确性,也意外地增强了检索性能。
性能表现
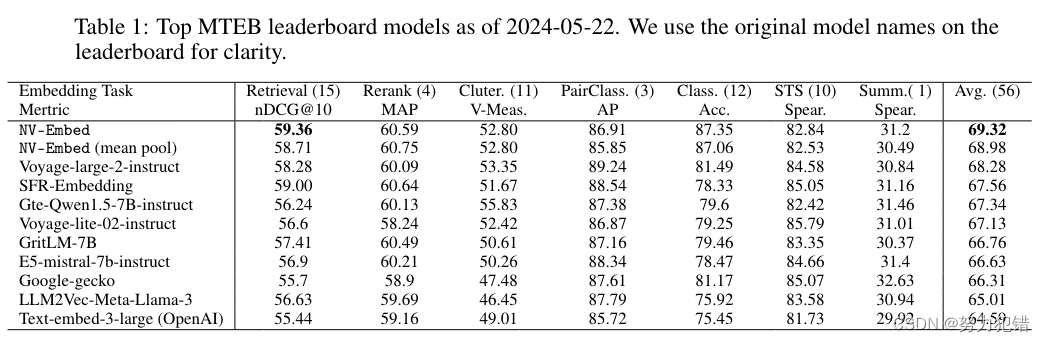
NV-Embed 模型在 MTEB (Massive Text Embedding Benchmark) 上取得了令人瞩目的成绩。该基准包含 56 项任务,涵盖了信息检索、重排序、分类、聚类和语义文本相似度等多种任务。NV-Embed 在这 56 项任务中获得了 69.32 的总分,排名第一,超越了包括 E5-mistral-7b-instruct、SFR-Embedding、Voyage-large-2-instruct 等在内的所有领先模型。值得注意的是,NV-Embed 在 BEIR (Benchmark for Information Retrieval) 基准测试 (包含 MTEB 中的 15 个检索任务) 上也获得了最高分 59.36。
应用场景
NV-Embed 拥有强大的文本嵌入能力,能够在各种自然语言处理任务中发挥作用,例如:
-
信息检索: 更精准地找到与用户查询相关的文档。
-
问答系统: 提升问答模型的理解能力,生成更准确的答案。
-
语义相似度计算: 更精确地判断两个文本之间的语义关系。
-
文本分类: 将文本准确地分类到相应的类别中。
-
聚类分析: 将文本按照语义进行分组。
总结
NV-Embed 是一种基于双向注意力的解码器 LLM 嵌入模型,它融合了创新的架构设计和训练方法,在 MTEB 和 BEIR 基准测试中取得了突破性的成绩。NV-Embed 的开源发布,为研究人员和开发者提供了一个强大的文本嵌入工具,推动着文本嵌入模型的进一步发展和应用。
模型下载
Huggingface模型下载
https://huggingface.co/nvidia/NV-Embed-v1
AI快站模型免费加速下载
https://aifasthub.com/models/nvidia

















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









