










目录
0、摘要
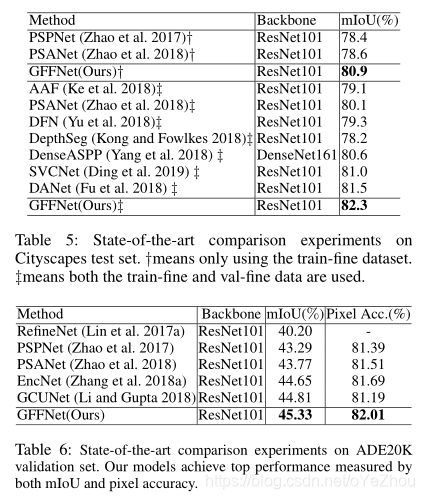
语义分割任务通过密集像素预测来生成对场景的完全理解。DCNN生成的高级特征已被证明在语义分割中的有效性,然而,对于小或窄的这类对细节要求较高的目标来说,低分辨率的高级特征所生成的分割结果往往不够精细。不幸的是,简单融合多级特征的方式又受不同级别特征之间的语义鸿沟的影响。本文提出了一个新的多级特征融合方式,称为门控全融合(Gated Fully Fusion,GFF),利用门控机制以全连接的方式选择性地从多个级别进行特征融合。具体来说,每一层的特征通过语义更强的高层特征和细节更多的低层特征来增强,并使用门来控制有用信息的传播,从而显著降低融合过程中的噪声。此方法在Cityscapes, Pascal Context, COCO-stuff 和 ADE20K四个场景解析数据集上均达到SOTA性能。
1、引言
GFF重点解决的依然是受到语义分割任务中高、低级特征中间的矛盾问题:高级特征具有低分辨率-高语义信息的特点,而低级特征具有高分辨率-低语义信息的特点。
PS:话说该问题已是老生常谈,很多文章都是从某个层面在一定程度上解决这个问题,如:FCN的高级特征上采样和低级特征融合、U-Net和SegNet对Encoder-Decoder中对应层级特征的融合、PSPNet的金字塔池化模块、DeepLab系列中的膨胀卷积和ASPP、GCN中的大卷积核、HRNet的自始至终保持高分辨率,以及基于注意力的Non-local和CCNet等方法。
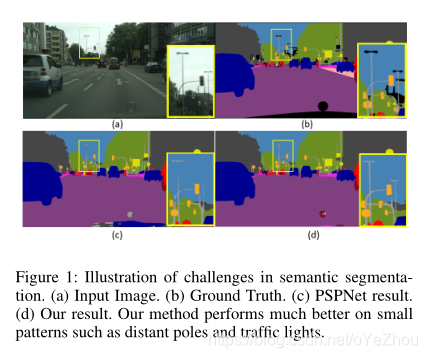
作者指出,简单融合高级、低级特征将会使得有用信息淹没在大量无效信息当中,因而需要更加有效的特征融合方式。本文提出的门控全融合( Gated Fully Fusion,GFF)正是为了提供一种高效的融合机制,其方法是:利用了时间序列信息提取的常用方法——门控机制,逐像素地测量每个特征向量的有用性,并根据有用性的大小,通过这个门来控制信息的传播。每层中的门不仅向其他层发送有用的信息,同时当本层信息无用时也会从其他层接收信息。基于这种门控机制,能够有效减少网络中的信息冗余,从而可以使用全连接的方式进行多级特征融合。基于GFF的方法与PSPNet的方法分割结果对比如图1:
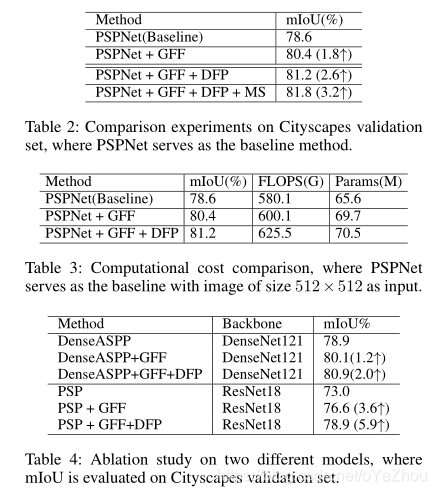
此外,在GFF模块之后,作者还使用了一个称为密集特征金字塔( dense feature pyramid,DFP)的模块来建模上下文信息。具体的,GFF在backbone上运行,以获取更多细节信息;DFP对GFF之后的每层feature map编码上下文信息,以增强上下文建模部分。
总的来说,本文主要贡献有:
- 提出了GFF从多级feature maps生成高分辨率-高级特征;
- 提出DFP增强了多级feature maps的语义表示;
- 对门控机制的正则作用进行了可视化分析;
- 提出的方法达到SOTA;
2、本文方法
作者受上下文建模、多级特征融合、门控机制这些方法启发,提出了本文的GFF、DFP方法,可以在融合多级特征的同时利用了门控机制。
2.1、GFF模块
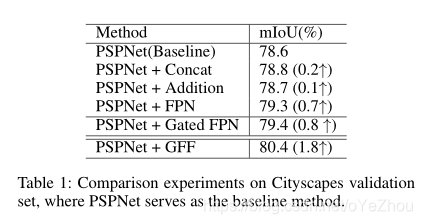
传统的多级特征融合方法有:Concat、Addition、FPN,这些方法都是直接融合特征,而不管信息是否有用,所以融合后的特征就很可能包含大量无用信息。于是,提出了GFF模块利用门控机制在大量无效信息中选择有用的信息。GFF可以测量feature map中每个特征向量的有用性,然后根据测量结果有选择的聚合信息。本文的GFF是基于Addition的融合方式进行的设计,对每个层级 都分配了一个gate map
都分配了一个gate map 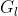 ,GFF的公式如下:
,GFF的公式如下:
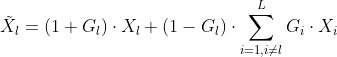
与公式对应的GFF具体设计如图2:
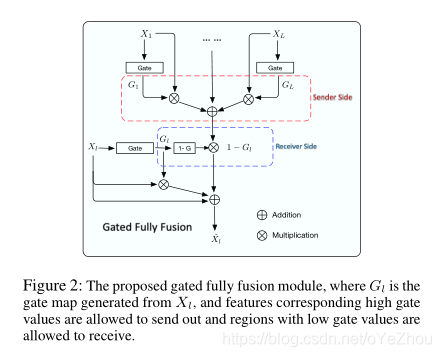
总体来说:对于第层的feature map—— ,生成了gate map——,可以控制高于门限值的特征被允许发送、低于门限值的特征被允许接收。
,生成了gate map——,可以控制高于门限值的特征被允许发送、低于门限值的特征被允许接收。
对于图2的GFF简单解析一下:
包含了两种门控机制:发送端、接收端;
- 发送端(也即
 和
和 的聚合,上述红色虚线框)通过把除了层的其他所有层feature maps中高于门限值的有用信息保留了下来,然后通过addition的方式加在一起;
的聚合,上述红色虚线框)通过把除了层的其他所有层feature maps中高于门限值的有用信息保留了下来,然后通过addition的方式加在一起; - 接收端(也即和的聚合,上述蓝色虚线框)通过
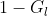 把发送端送过来的信息进行了反向过滤,保留了 层没有的信息(这么做是为了避免信息冗余);
把发送端送过来的信息进行了反向过滤,保留了 层没有的信息(这么做是为了避免信息冗余); - 最后就是把三部分信息(本身的feature maps、通过过滤后中的有用信息、其他所有层(
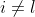 )中与不冗余的信息)通过Addition的方式融合起来,即可得到GFF输出
)中与不冗余的信息)通过Addition的方式融合起来,即可得到GFF输出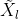 。
。
2.2、DFP模块
上下文信息建模的目的是编码更多的全局信息,这和GFF是正交的,因为GFF是为了backbone信息融合而设计的。因此,就可以在其后增加一些上下文建模的方法,而和GFF互不影响。基于这种想法,作者设计了DFP模块,在PSPNet结构的基础上进行了设计:在PSPNet的PPM的输出以及backbone中GFF的输出之后,使用DFP对其输出进行信息编码,以获取全局上下文信息。
DFP的公式如下:
![y_{i}=H_{i}\left(\left[y_{0}, \tilde{X}_{1}, \ldots, \tilde{X}_{i-1}\right]\right)](https://i-blog.csdnimg.cn/blog_migrate/d2d15bf86c7f9885e7e86fb904fe5e15.gif)
其中, 是PSPNet中的PPM的输出,
是PSPNet中的PPM的输出,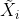 是GFF中第
是GFF中第 个GFF子模块的输出,
个GFF子模块的输出, 是单个卷积层。
是单个卷积层。
DFP的作用,其实就是把PPM的输出和GFF的输出用一个卷积层密集的连接起来,也因此称为Dense Feature Pyramid。
2.3、整体网络结构
整体网络结构是基于以Resnet为backbone的PSPNet设计的,首先在backbone部分添加了GFF模块以控制信息的融合,在PPM之后添加DFP模块以进行上下文信息建模,具体结构如图3所示:
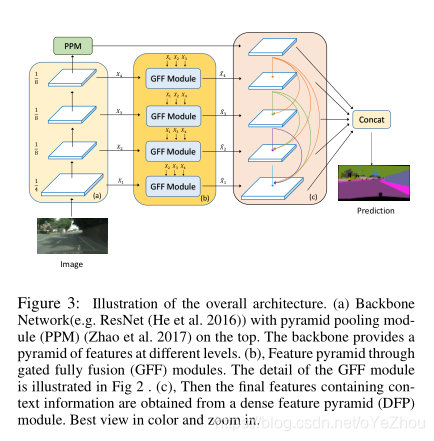
网络结构简单解析一下:
首先,对于backbone的每个level,都接了一个GFF模块,从该level提取出本level的有用信息,以及其他level中包含的本level没有的信息,该过程如图3(b)所示;
然后,将PPM输出和每个GFF模块的输出,送入后续的DFP模块,也即图3(c)的部分,进行密集的上下文融合;
最后,DFP的输出concat起来用于预测分割map;
3、实验结果

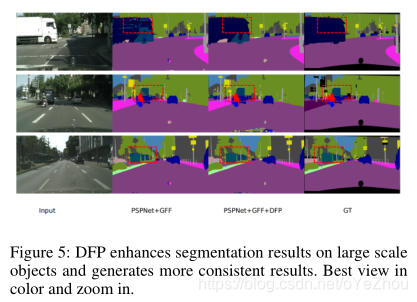
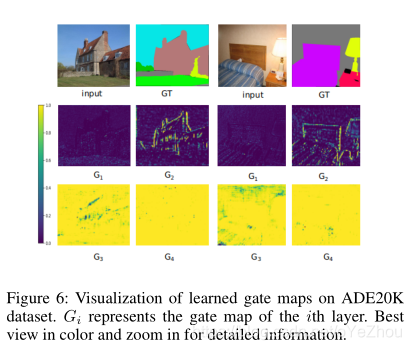
4、写在后面
总的来说,本文提出了GFF和DFP模块,分别进行有效的信息融合与上下文建模。基于PSPNet的结构,添加两种模块提升了网络的分割性能,达到SOTA。
其主要创新还是在于GFF模块,将RNN中的门控机制引入的CV领域,来对信息传播进行控制。这种想法非常新颖,值得借鉴。不得不说,最近RNN和CNN的边界感越来越弱了,各自领域的方法互相渗透融合、采长补短,NLP领域的Transformer、non-local、self-Attention,加上这篇文章的Gates机制,可谓遍地开花。
所以我有了一个异想天开的想法:未来会不会出现一种大一统的方法,实现NLP和CV江湖一统?或许单单是网络结构的创新还不够,如果能够有一种更generalize的优化算法,而不是目前的基于梯度的更新策略,会不会只需要简单的结构就能够完美地优化训练?到时候,或许我们就不需要各种网络结构了~~~


















 306
306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











