








本文提供了一个从wider_attribute数据集中提取性别属性的方法;并提供了数据集的下载链接。
目录
1、数据集说明
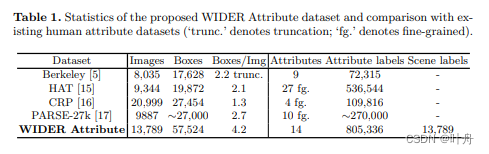
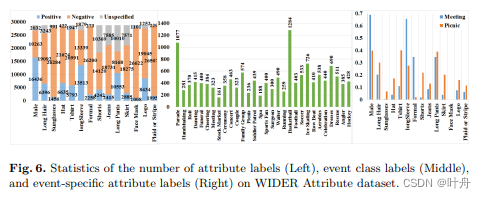
WIDER Attribute是一个大规模的人类属性数据集。它包含属于 30 个场景类别的 13789 个图像,以及 57524 个人体边界框,每个边界框都用 14 个二进制属性进行注释。

数据集一览:



可见,该数据集也是从大图里面标注了人体的边框,并提供了每个人的属性集的。
此外,该数据集相比之前的其他数据集也有一定优势:
数据标注格式为:
{
"images" : [image], # A list of "image" (see below)
"attribute_id_map" : {str : str}, # A dict, mapping attribute_id to attribute_name
"scene_id_map" : {str : str} # A dict, mapping scene_id to scene_name
}
image {
"targets" : [target], # A list of "target" (see below)
"file_name" : str, # Image file name
"scene_id" : int # Scene id
}
target {
"attribute" : [int] # A list of int, the i-th element corresponds to the i-th attribute, and the value could be 1(possitive), -1(negative) or 0 (unspecified)
"bbox" : [x, y, width, height] # Human bounding box
}2、方法
通过以下代码,可以从数据集中解析出每个图片的属性,并根据性别存放到不同文件夹:
"""
parse person's gender from wider_attribute
"""
import os
import cv2
import glob
import json
import numpy as np
def xywh2xyxy(xywh):
x1, y1, w, h = xywh
x2 = x1 + w
y2 = y1 + h
return [int(x1), int(y1), int(x2), int(y2)]
def main(raw_path, new_dataset_path):
classes = ['0_Female', '1_Male']
os.makedirs(new_dataset_path, exist_ok=True)
Male_path = os.path.join(new_dataset_path, '1_Male')
Female_path = os.path.join(new_dataset_path, '0_Female')
os.makedirs(Male_path, exist_ok=True)
os.makedirs(Female_path, exist_ok=True)
anno_files = glob.glob(raw_path + '/annotation/*.json')
for anno_file in anno_files:
print("\n\nProcessing: {}".format(anno_file))
anno = json.load(open(anno_file, 'r'))
images = anno['images']
attribute_id_map = anno['attribute_id_map']
imgs_num = len(images)
for idx, image in enumerate(images):
print("\rdeal: [{}/{}]".format(idx + 1, imgs_num), end='')
file_name = image['file_name']
img_cv = cv2.imread(os.path.join(raw_path, 'Image', file_name))
H, W, _ = img_cv.shape
targets = image['targets']
for t_i, target in enumerate(targets):
attribute = target['attribute']
if attribute[0] == 0:
continue
cls_id = 1 if attribute[0] == 1 else 0
class_name = classes[cls_id]
bbox = target['bbox']
x1, y1, x2, y2 = xywh2xyxy(bbox)
x1, x2 = np.clip([x1, x2], 0, W)
y1, y2 = np.clip([y1, y2], 0, H)
if y2-y1 <= 0 or x2-x1 <= 0:
continue
target_cv = img_cv[y1:y2, x1:x2, :]
# print(target_cv.shape, [x1, y1, x2, y2])
name = os.path.splitext(file_name.split('/')[-1])[0] + '_{}.jpg'.format(t_i)
img_save_to = os.path.join(new_dataset_path, class_name, 'wider_' + name)
write_status = cv2.imwrite(img_save_to, target_cv)
assert write_status, "target image [{}] write error!".format(img_save_to)
if __name__ == '__main__':
raw_path = '../wider_attribute'
new_path = '../datasets/gender_dataset_parse/from_wider'
main(raw_path, new_path)
3、附
下载链接: https://pan.baidu.com/s/1mbxI6npcxsx0FHQh2DV_OQ?pwd=b1xw 提取码: b1xw
4. Citation
@inproceedings{li2016human,
author = {Li, Yining and Huang, Chen and Loy, Chen Change and Tang, Xiaoou},
title = {Human Attribute Recognition by Deep Hierarchical Contexts},
booktitle = {European Conference on Computer Vision},
year = {2016}
}论文:http://personal.ie.cuhk.edu.hk/~ccloy/files/eccv_2016_human.pdf


















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











