







 本文回顾了2014年至2019年间GAN模型的发展历程,重点介绍了SAGAN、BigGAN、SinGAN、GauGAN、GANILLA及NICE-GAN等模型。涵盖自我注意力机制、光谱归一化、双时间尺度更新规则、截断技巧及稳定性见解等内容。
本文回顾了2014年至2019年间GAN模型的发展历程,重点介绍了SAGAN、BigGAN、SinGAN、GauGAN、GANILLA及NICE-GAN等模型。涵盖自我注意力机制、光谱归一化、双时间尺度更新规则、截断技巧及稳定性见解等内容。
简介
本节是助教主讲GAN的专题回顾,主要内容包括:
·Recap
·SAGAN
·BigGAN
·SinGAN
·GauGAN
·GANILLA
·NICE-GAN
公式输入请参考:在线Latex公式
Recap
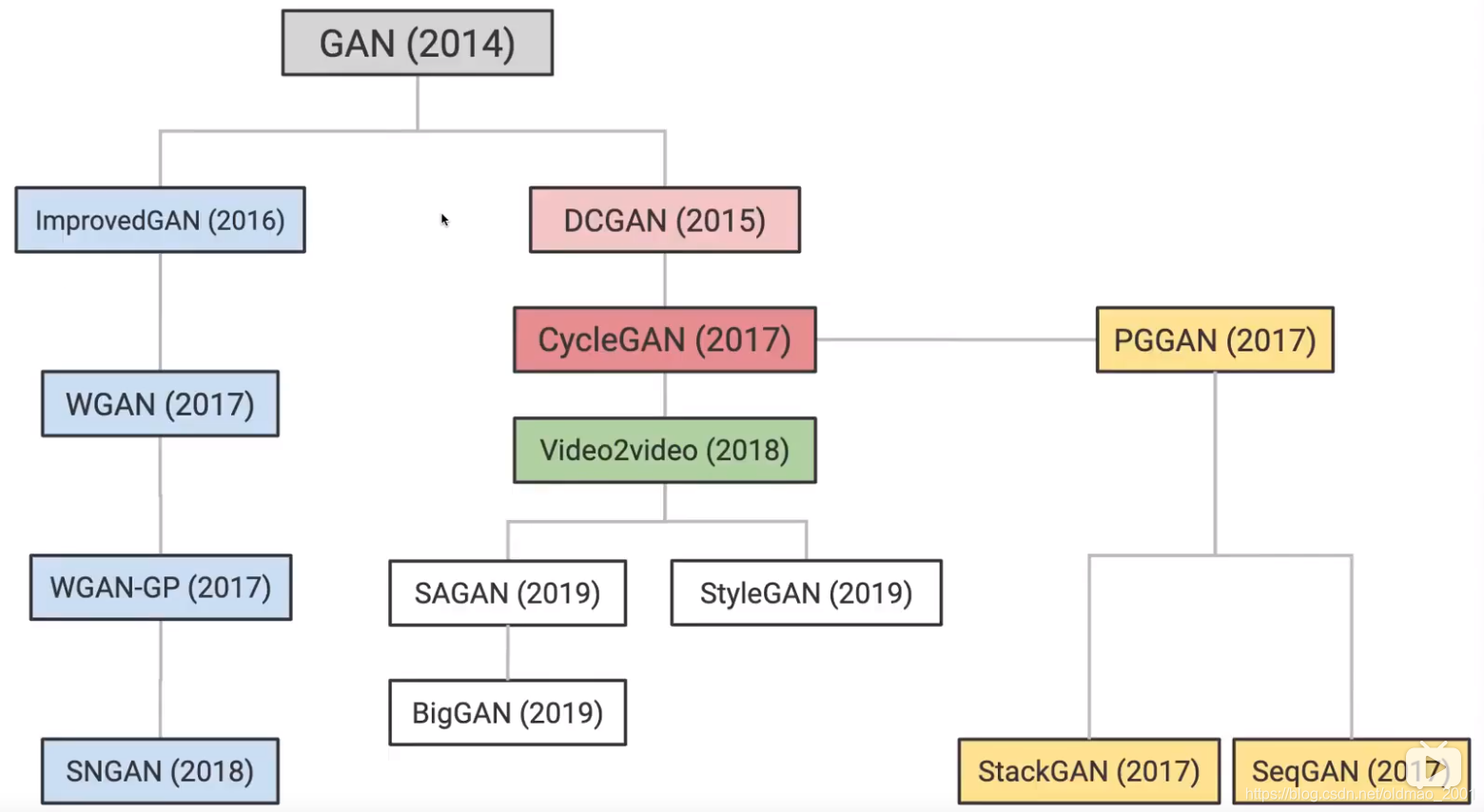
上图涵盖了2014年到2019年GAN模型的发展
其中左边的分支代表模型的稳定度的发展(数学角度)
ImprovedGAN(2016)的作者和GAN(2014)的作者相同,不过ImprovedGAN对原始的GAN做了一些改进。
WGAN(2017)改进了测量两个分布的方式。
WGAN(2017)提出了一种思想,具体实现是在WGAN-GP(2017)
这个分支的终点是SNGAN(2018),从数学上用最完美的方法来解决GAN.
右边的大分支是GAN在CV领域的应用,因此里面大量用到了CNN.
本节讲的是上图中白色框框的三个。外加其他三个。
Self-attention GAN(SAGAN)
·Self-attention
·Spectral normalization (SN) for both G andD
·Imbalanced learning rate for G and D(TTUR)
Zhang H, Goodfellow I, Metaxas D, Odena A. Self-attention generative adversarial networks. arXiv preprint arXiv:1805.08318.2018 May 21.
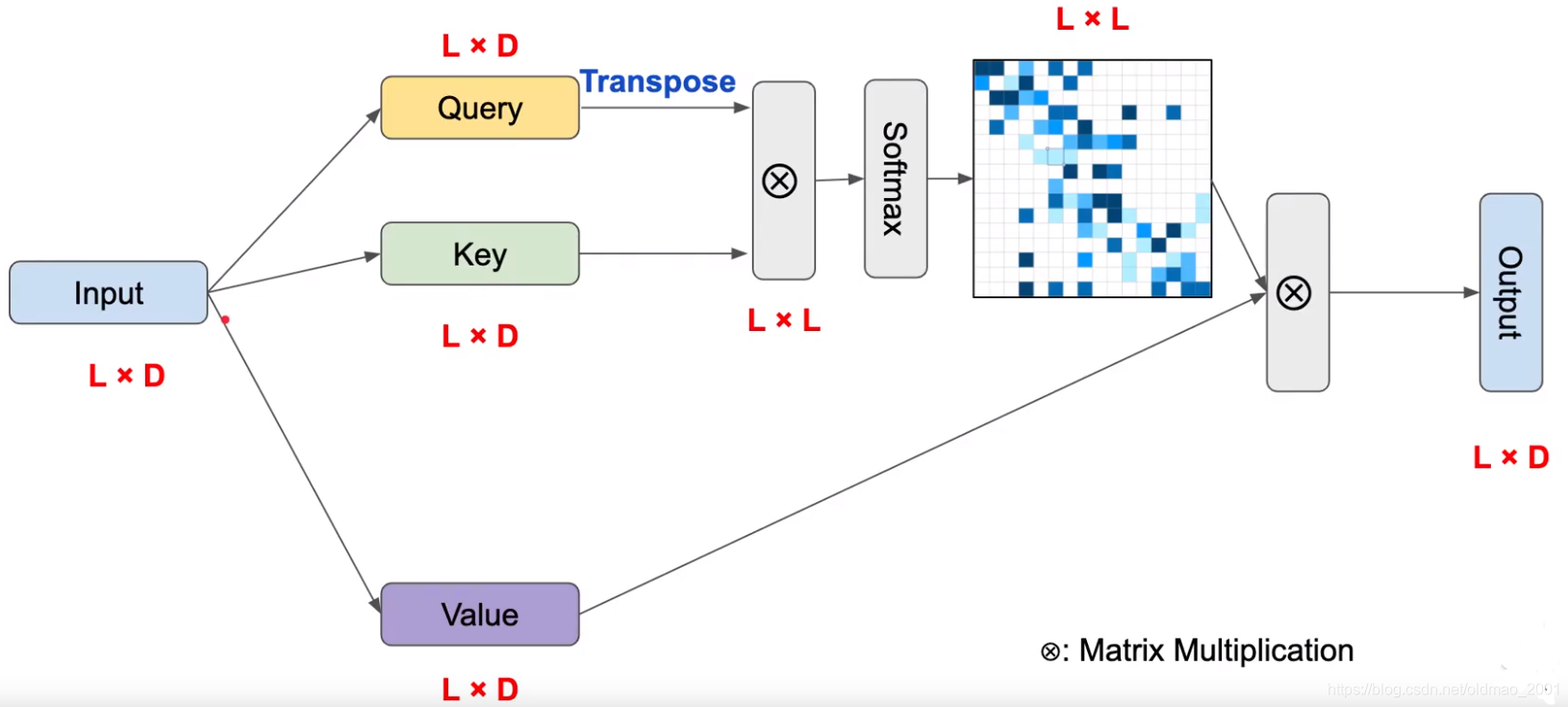
Self-attention
注意看shape.
将input通过(1×1的CNN)转换得到三个和input的大小相同的Query、Key和Value,然后把Query做转置后与Key相乘,然后丢如Softmax分类器得到一个L×L大小的关联矩阵,这个矩阵中的每一行的值之和都为1(Softmax是求概率),上面的颜色深浅代表对第rownum个单词的重要性。最后将关联矩阵和Value做乘法后,通过1×1的CNN转换得到Output。
Spectral normalization (SN)
SAGAN是基于2018年的SNGAN上改进而来的,所以这里先要讲一下SN。
SN这个操作是作用SNGAN在Discriminator上的;而这里的SAGAN模型中,Generator和Discriminator都用到了SN操作。(从实验结果上看效果不错)
在Pytorch中已经有专门的package可以调用。
W
S
N
=
W
σ
(
W
)
,
σ
(
W
)
=
m
a
x
h
:
h
≠
0
∣
∣
W
h
∣
∣
2
∣
∣
h
∣
∣
2
W_{SN}=\cfrac{W}{\sigma (W)},\sigma (W)=\underset{h:h\neq0}{max}\cfrac{||Wh||_2}{||h||_2}
WSN=σ(W)W,σ(W)=h:h=0max∣∣h∣∣2∣∣Wh∣∣2
这里的W就是线性变换,h是奇异值(singular value)
官方例子
>>> m = spectral_norm(nn.Linear(20, 40))
>>> m
Linear(in_features=20, out_features=40, bias=True)
>>> m.weight_u.size()
torch.Size([40])
Two-Timescale Update Rule(TTUR)
对于Generator和Discriminator使用不同大小的LR
原文的数据:
Ir for D:0.0004
Ir for G:0.0001
Heusel,M., Ramsauer,H., Unterthiner,T., Nessler,B., and Hochreiter,S. GANs trained by a two time-scale update rule converge to a local nash equilibrium. In NIPS, pp. 6629-6640,2017.
Visualization of attention maps

可以看到,红色是鸟的身子,绿色是背景,蓝色是鸟尾。
意思就是距离很近不带表相关度很大。
BigGAN
·Based on SAGAN and SN
·Two to four times as many parameters
·Batch size*8
·Truncation Trick
·Some insights about training stability
Brock A, Donahue J, Simonyan K. Large scale gan training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096.2018 Sep 28.
这个模型相当于SAGAN的加强版,是在SAGAN的基础上进行改进。将SAGAN的超参数放大几倍后观察其性能的变化,并提出了一些训练的trick。
Truncation Trick
我们知道,GAN是接收一个分布中sample出来的随机值/向量,根据这个随机值/向量来生成目标图片/对象。
Truncation Trick的思想是设置一个threshold,sample出来的值要小于这个threshold,否则重新sample,这样会使得GAN生成的图片会具有某一特征(在多样性和生成质量上来看)
阈值为2:

阈值为1:

阈值为0.5:

阈值为0.04:

可以看到阈值越小,生成的狗子姿势都差不多,但质量好,阈值越大,生成的质量差,但是姿势不一样。但是这个trick不适用于其他GAN,作者给出一种正则的方式来使得该trick能泛化到其他GAN中。
Some insights about training stability
这块内容是作者关于如何训练这些大数据集的心得体会。
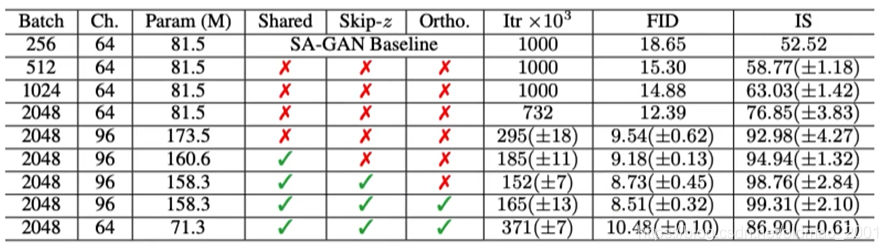
第一列的Batch Size,第二列是Channel,第三列是参数数量
第四列代表不同层之间是否共享参数,第五列代表是否设置了Truncation Trick的阈值
第六列是Truncation Trick中作者提出来的正交Regular
第七列是训练的轮次,小于1000的都是坏掉了,模型越大越容易出结果,但是也越容易坏掉,因此要使用早停机制。
后面两列是评价指标,FID越低越好,IS是越高越好。
SinGAN
·One training data is enough!
·Progressively train
·Many application fields
Shaham TR, Dekel T, Michaeli T. Singan: Learning a generative model from a single natural image. In Proceedings of the IEEE International Conference on Computer Vision 2019(pp. 4570-4580).
如何用一张图片训练GAN。
One training example
原理就是把一张图片切成很多张图片。

变成

Trade-off
·For a 200×200 image:一个200×200的图片
·150×150:~2500,可以切除2500张
·But MNIST(28×28)datatset:~55000
说明光按一种size切不够,因此,可以按不同大小的尺寸进切割,但是切割后,模型不能学习到图片的全局信息,要如何在二者之间进行权衡需要进一步研究。
原文实例

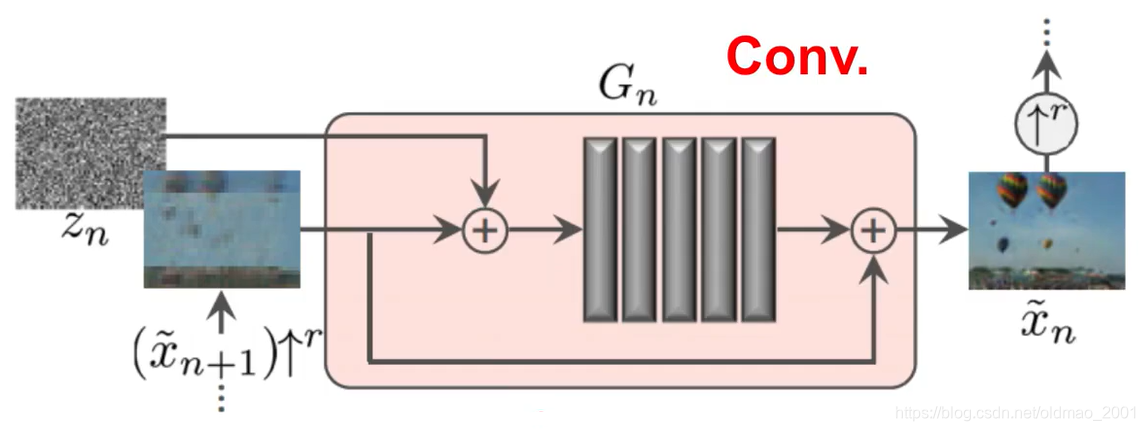
Progressively train
渐进式训练,从大到小。
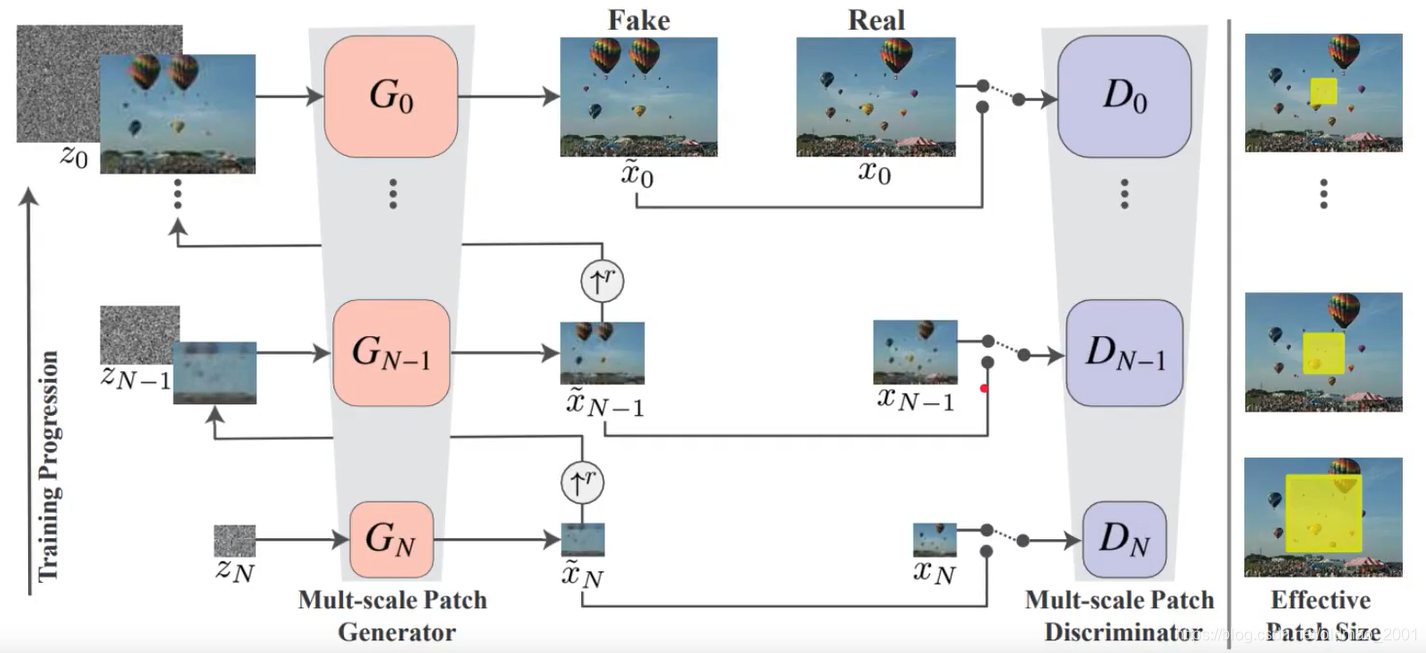
注意左下角的箭头,是从下到上的。
每一层的Generator需要有两个输入(最下面那层除外),那个黑白的noise是独立sample出来的。
上一层Generator需要吃下一层Generator的输出,看箭头,这里大小不一致可以通过upper sampling解决。
真实数据从上到下是用Down Sampling的方式逐层生成的。
最右边的那列图片黄色的实际上相当于CNN中的卷积核,论文用的是11×11大小的卷积核,由于原图片是不断的Down Sampling,所以相对来说卷积核越来越大。
下图是Generator的具体构架
Many application fields
高解析度纹理生成

Paint to image
用最左边的图片训练,给定Input Paint生成对应的图片。
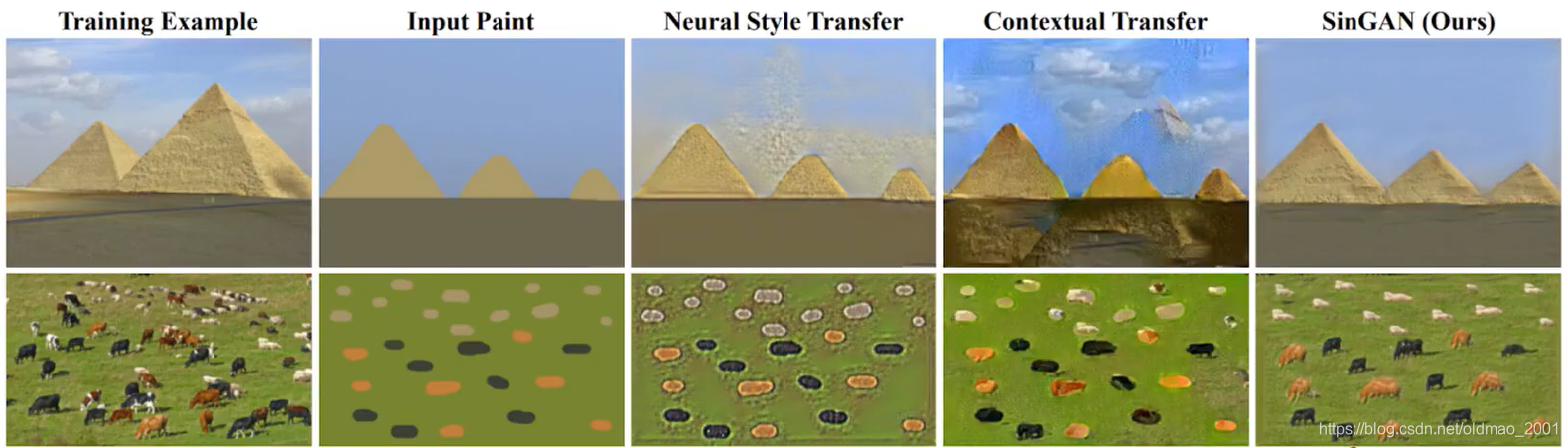
Image editing
修图

Image harmonization
把飞船和海豚融入画风中。

GauGAN
Park T, Liu MY, Wang TC, Zhu JY. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2019(pp.2337-2346).
左上角是定义,X轴是一些合理的构图,Y轴是不同的风格图片

作者还在线弄了一个互动效果,可以实时的画X轴的构图,然后实时生成对应图片。
SPADE
这个SPADE是一种Normalization的方法,它和传统Normalization的方法不一样:
Wu Y, He K. Group normalization. In Proceedings of the European Conference on Computer Vision
(ECCV) 2018 (pp.3-19).
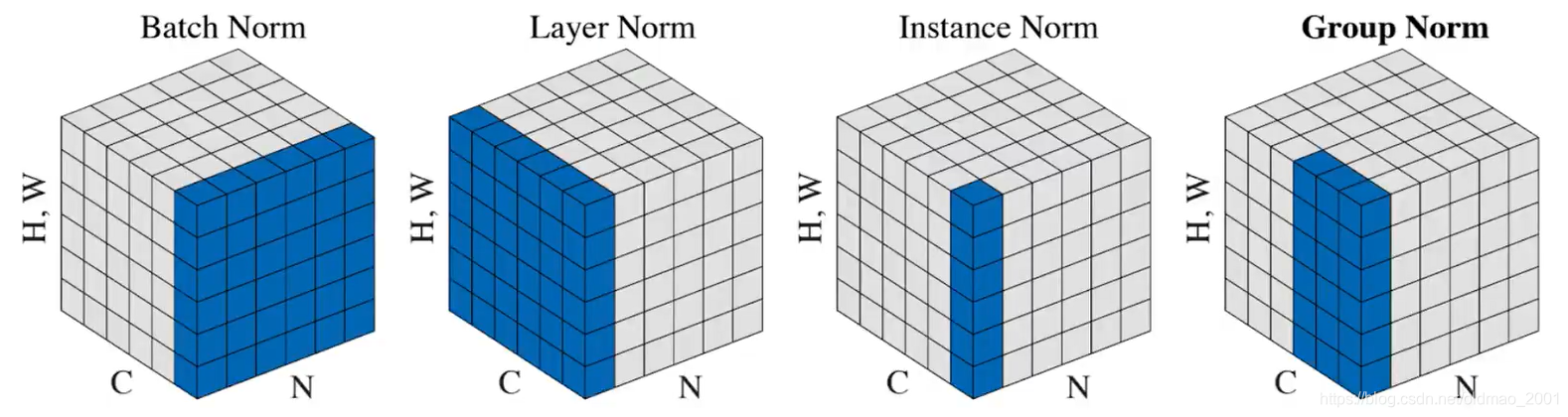
以上传统的Normalization其实都属于Unconditional Normalization,意思是在Normalization过程中需要均值和std两个值,这两个值是在训练万模型后,从training data中学到的。学到的这两个值就存下来了,即使在做测试的时候也不会变化。
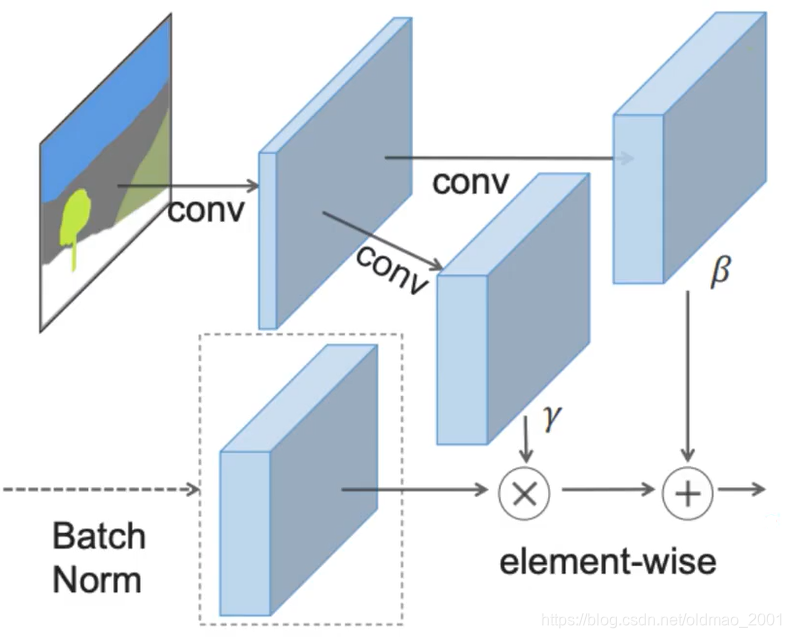
SPADE是属于Conditional Normalization,它会根据输入来变化的Normalization(input dependent),主要是下图中的
γ
,
β
\gamma,\beta
γ,β,分别做乘法和加法操作,每个输入不一样
γ
,
β
\gamma,\beta
γ,β也不一样
具体结构如下:
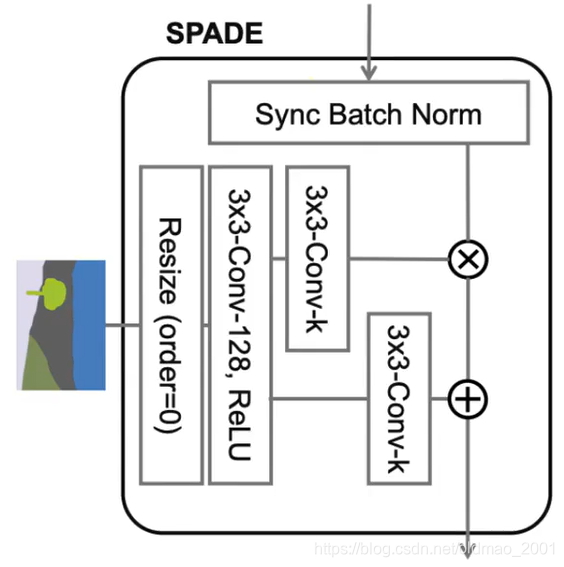
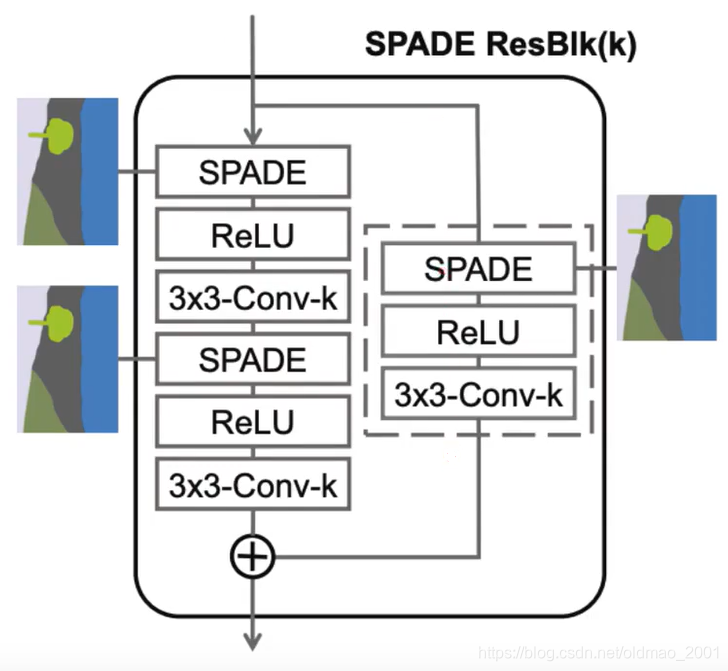
在这个结构里面还有加上了残差模块,就是下图中右边虚线框内的东西。
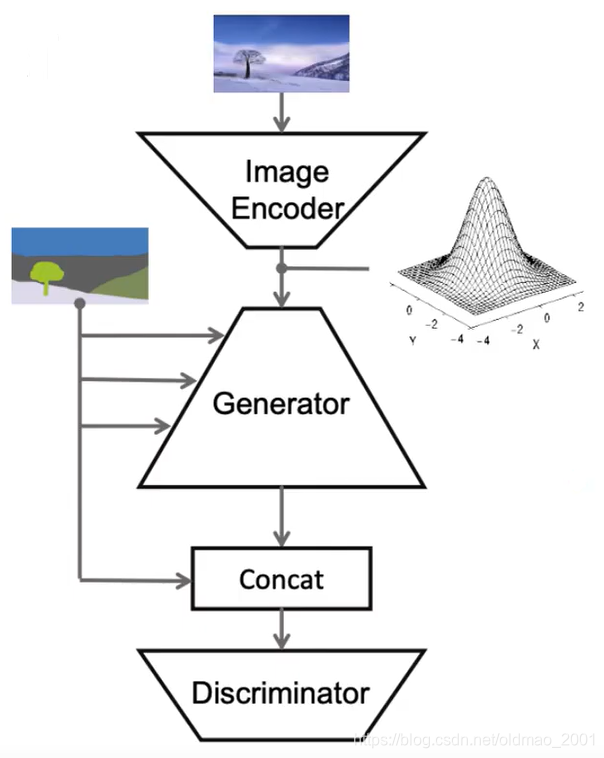
Use encoder(Style)
这里是全局结构,其中的Image Encoder是用来提取要展示的风格特征。例如下图中的风格图片是雪景,以白色和蓝色为主
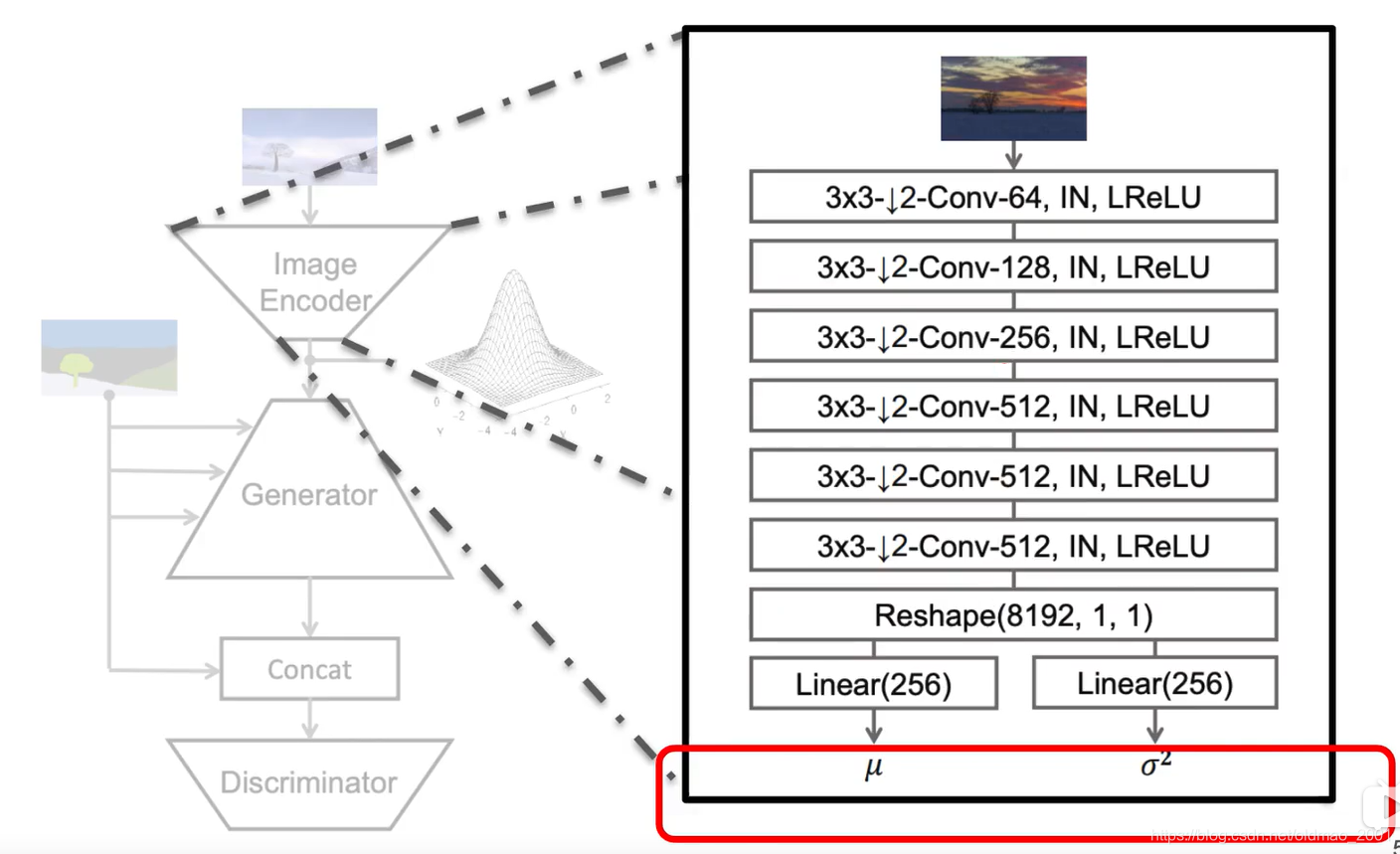
Encoder架构如下:
经过这个架构可以得到一个均值和方差。
均值和方差+右上角的正态分布采样出来的noise+手绘图片构架
Generator构架如下:
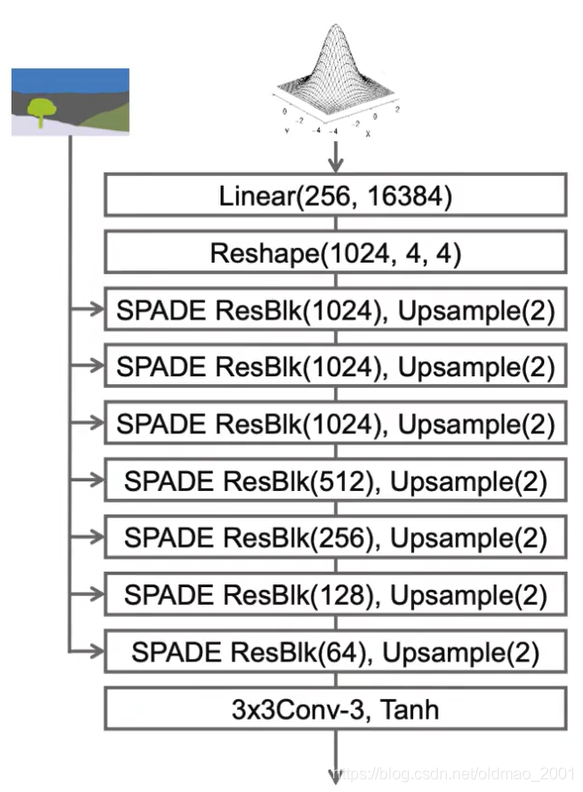
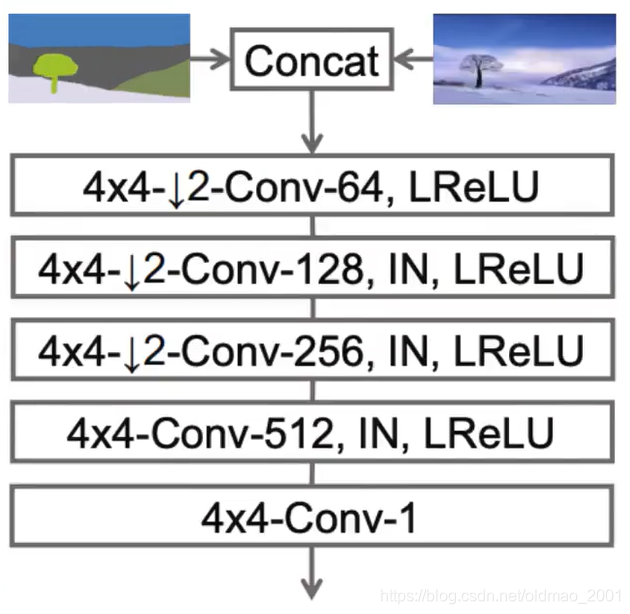
Discriminator构架:
GANILLA
· Unpaired data
· Either Style or Content(e.g. CycleGAN, DualGAN, CartoonGAN)
· Propose an extensive children’s books illustration dataset
Hicsonmez S, Samet N, Akbas E, Duygulu P. GANILLA: Generative adversarial networks for image to illustration translation. Image and Vision Computing.2020 Mar 1;95:103886.
Either Style or Content
论文认为GAN的迁移学习要么是迁移风格,要么是迁移内容,应该可以把二者都做到更好
原来做这个事情的有:CycleGAN,DualGAN,and CartoonGAN

先比较一下Generator:
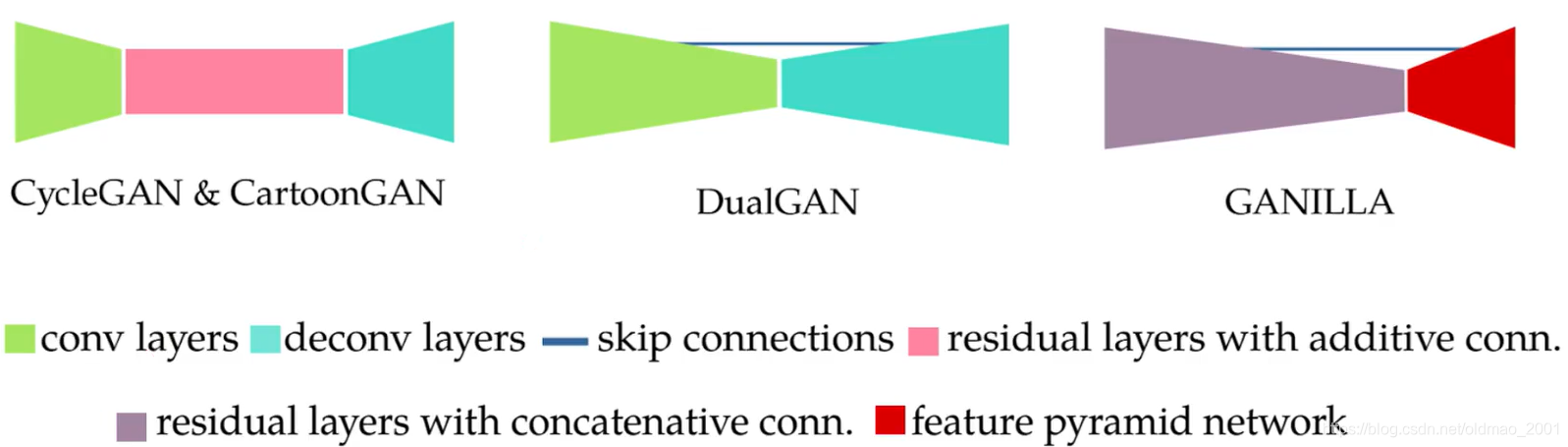
GANILLA的架构还蛮特别,作者注意到,Morphological features: Edge, Shape.通常是在卷积的前端会抽取到,所以这些信息要保留,就要把这些层的输出直接接到后面去,保留形状、线条等信息。
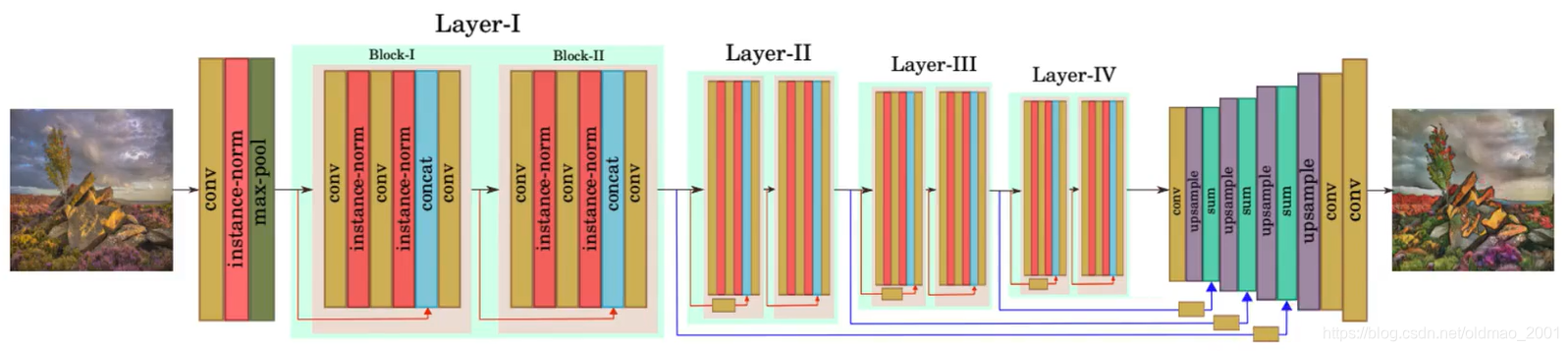
作者还将GANILLA的架构的某一部分替换为一些经典构建,以弄清楚到底是GANILLA的哪一部分对结果在起作用:结论是都很重要。
数据集
论文的另外一个贡献是创建了一个卡通数据集,下面图片前面的字母代表卡通图片的风格。


结果分析
参数量最小,速度也还可以。

从转换的结果来看,DualGAN保留原风格最多,CycleGAN就有点坏了。

下面是宫崎骏风格的转换:

NICE-GAN
·No independent encoder
·Model structure
Chen R, Huang W, Huang B, Sun F, Fang B. Reusing Discriminators for Encoding Towards Unsupervised Image-to-lmage Translation. arXiv preprint arXiv:2003.00273.2020 Feb 29.
No independent encoder
论文提出不需要单独训练Encoder,直接用Discriminator的前半部分来做这个事情,好处就是模型变小了
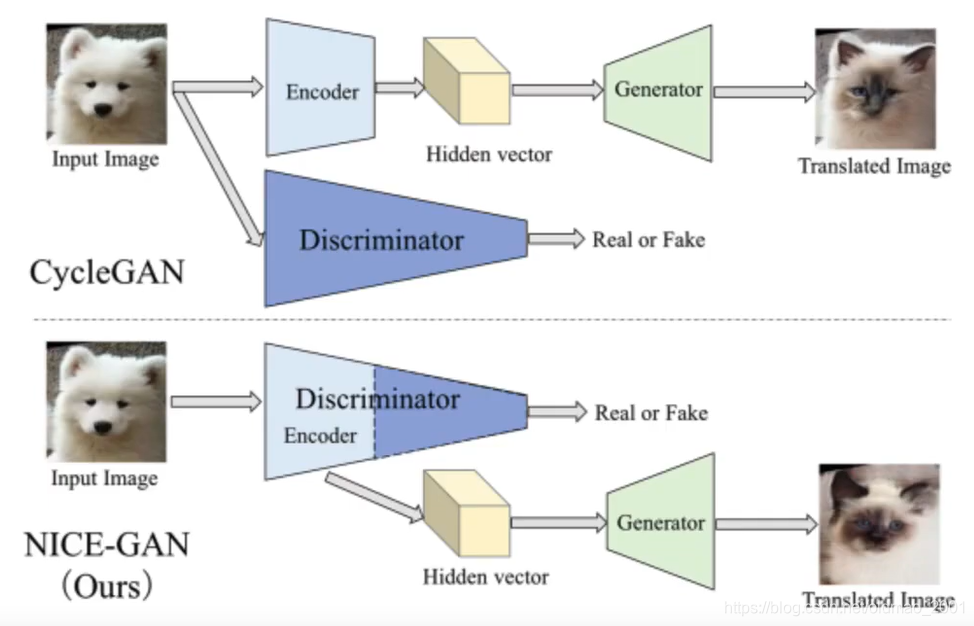
Discriminator能完成这个事情是因为它有两个功能:
·Encoding
·Classifying
Advantages of sharing encoder and D
·No need to train encoder independently
·The encoder is trained more efficiently
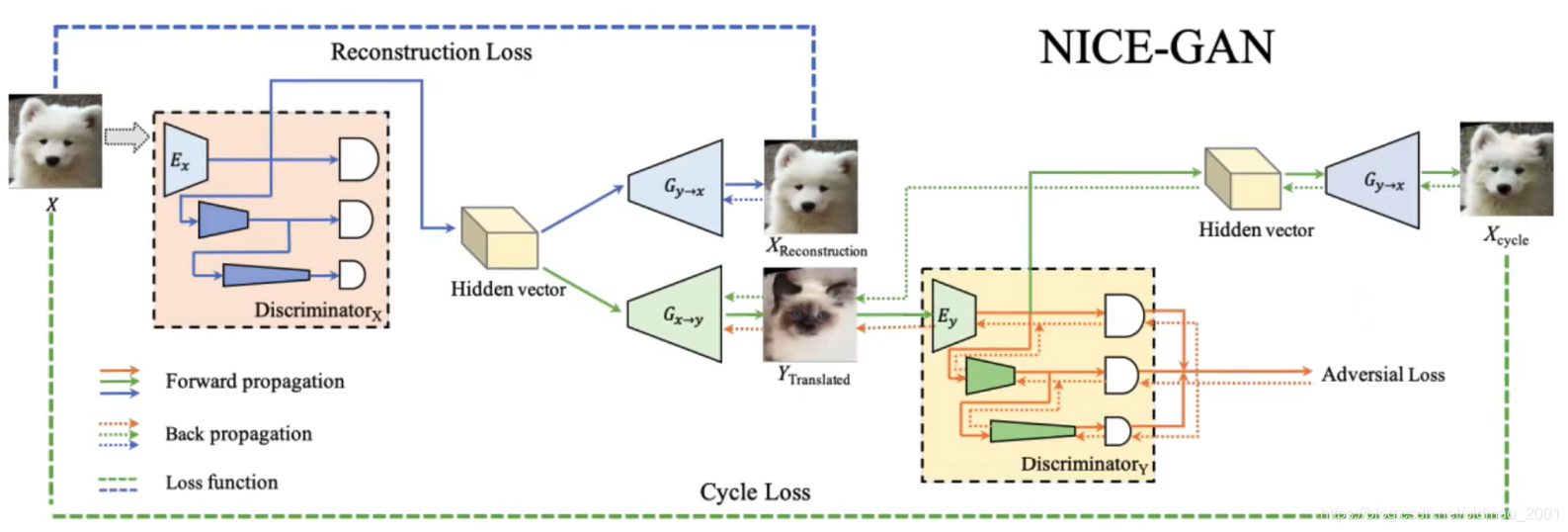
模型构架
结果
第一第二行是猫狗互换
第三第四行是季节互换


小结
·SAGAN(Self-attention)
·BigGAN(旗舰版 SAGAN)
·SinGAN(将一图片切成很多小图片当作训练数据)
·GauGAN(Conditional normalization)
·GANILLA(CycleGAN/DualGAN mega进化、宫崎骏)
·NICE-GAN(Discriminator的前半部当成encoder)


















 2810
2810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











