







文章目录
介绍
元学习Meta learning = 学习如何去学习Learn to learn
和Life-long方法有所不一样:
| 方法 | 区别 |
|---|---|
| Life-long | one model for all the tasks |
| Meta | How to learn a new model |

从过去的任务中学习到一些经验,在新的任务上学得更快(不是更好)

公式输入请参考:在线Latex公式
Meta Learning概念
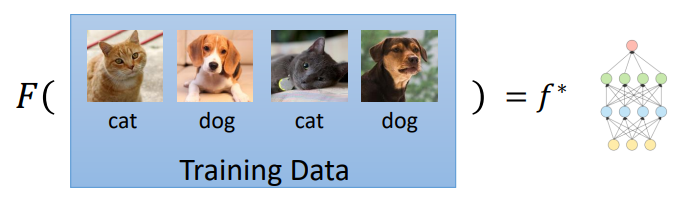
机器学习:用Training Data训练由我们设计的Learning Algorithm,得到一个最优算法 f ∗ f^* f∗,可以用来完成相应的任务(猫狗识别)

也就是:Machine Learning ≈ 根据数据找一个函数 f 的能力

原学习:用
D
t
r
a
i
n
D_{train}
Dtrain训练由我们设计的F,可以得到一个完成相应任务的
f
∗
f^*
f∗,怎么感觉和上面没什么区别?

其实不一样,Meta Learning≈ 根据数据找一个找一个函数 f 的函数 F 的能力。
机器学习中是知道函数f,而是训练函数f的参数;
绪论里面的图:

元学习是不知道函数f,而是训练函数F找到f(含参数)。
把上图中的function 代换为 F就变成了元学习

Meta Learning的三板斧
第一板
• Define a set of learning algorithm
以基于GD优化的算法为例,下图中的每一步的gradient
g
g
g其实不一样

对于上图中有很多东西都是我们人来定义的,具体看下图中红色框框,网络构建是我们定义的,初始值是我们定义的,定义的lr不一样,更新的结果也不一样。
红框中如果我们定义不同的东西,实际上就是不同的算法。我们的想法是让机器来帮助我们设计这些东西。

第二板
Defining the goodness of a function F
在机器学习中衡量一个函数f的好坏是用一组testing data来进行测试,那么要知道一个生成函数的函数F的好坏当然是要准备一把函数来进行测试咯。


从这里可以看到机器学习和元学习在数据上有所不一样:
机器学习的数据:
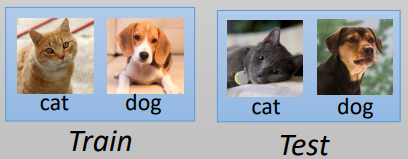
元学习的数据:

这里要说明:
- 由于元学习有多个任务,每个任务如果有很多数据,那么训练时间会很长很长,因此,元学习中每个任务的数据不会很多,所以元学习也叫few-shot learning,为了和机器学习区分开,训练和测试数据分别叫Support set和Query set。
- 和机器学习一样,当我们的元学习中的训练任务很多的时候,我们可以将其中一部分切出来作为验证任务:validation tasks。
- 元学习中的testing task可以和training task一样,也可以不一样。
第三板
• Defining the goodness of a function
F
F
F
完成了N个任务后,可以计算F的loss
L
(
F
)
=
∑
n
=
1
N
l
n
L(F)=\sum_{n=1}^Nl^n
L(F)=n=1∑Nln
我们就是要找到一个
F
∗
F^*
F∗,使得L最小。
F
∗
=
a
r
g
min
F
L
(
F
)
F^*=arg\underset{F}{\text{min}}L(F)
F∗=argFminL(F)
找到之后:

Meta Learning实例:Omniglot
https://github.com/brendenlake/omniglot
• 1623 characters,部分字符:

• Each has 20 examples

把这个学习过程看做是:N-ways K-shot classification,意思是 In each training and test tasks, there are N classes, each has K examples.
例如:20 ways 1 shot就是有20个类别,每个类别只有一个example。

具体做法:
• Split your characters into training and testing characters
• Sample N training characters, sample K examples from each sampled characters → one training task
• Sample N testing characters, sample K examples from each sampled characters → one testing task
Techniques Today
• MAML
• Chelsea Finn, Pieter Abbeel, and Sergey Levine, “Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks”, ICML, 2017

• Reptile
• Alex Nichol, Joshua Achiam, John Schulman, On FirstOrder Meta-Learning Algorithms, arXiv, 2018
MAML
MAML主要是关注初始化参数
ϕ
\phi
ϕ的选择(所有task的Network Structure都是一样的)。其损失函数为:
L
(
ϕ
)
=
∑
n
=
1
N
l
n
(
θ
^
n
)
L(\phi)=\sum_{n=1}^Nl^n(\hat\theta^n)
L(ϕ)=n=1∑Nln(θ^n)
其中:
θ
^
n
\hat\theta^n
θ^n: model learned from task n,
θ
^
n
\hat\theta^n
θ^n depends on
ϕ
\phi
ϕ
l
n
(
θ
^
n
)
l^n(\hat\theta^n)
ln(θ^n):loss of task n on the testing set of task n
这里补充下后面一节中助教的讲解:
MAML的框架是两层的循环嵌套,外面这层是更新MAML模型的参数
ϕ
\phi
ϕ,然后里面这层是更新任务的参数
θ
^
n
\hat\theta^n
θ^n,当然这个内部循环只更新一次(实际是两次)。

使用Gradient Descent来最小化
L
(
ϕ
)
L(\phi)
L(ϕ)
ϕ
←
ϕ
−
η
▽
ϕ
L
(
ϕ
)
\phi\leftarrow\phi-\eta\triangledown_{\phi}L(\phi)
ϕ←ϕ−η▽ϕL(ϕ)
这里要和transfer learning中的pre-train model的损失函数进行区分:
L
(
ϕ
)
=
∑
n
=
1
N
l
n
(
ϕ
)
L(\phi)=\sum_{n=1}^Nl^n(\phi)
L(ϕ)=n=1∑Nln(ϕ)
可以看到transfer learning是用现有的模型去计算Loss(看模型的当前表现)
而MAML是用
ϕ
\phi
ϕ训练之后的模型来计算Loss(看模型潜力)
用图形来表示二者的区别吧
MAML vs transfer learning
对于transfer learning,我们寻找在所有task都最好的
ϕ
\phi
ϕ,但并不能保证把
ϕ
\phi
ϕ拿去训练以后会得到最好的
θ
n
\theta^n
θn,例如下图中
ϕ
\phi
ϕ在task 2上得到最好的结果,但是拿到task 1上却只能得到一个局部最小值。

对于MAML,我们不在意
ϕ
\phi
ϕ 在 training task 上表现如何,我们在意用
ϕ
\phi
ϕ 训练出来的
θ
n
\theta^n
θn
表现如何,例如下图中的
ϕ
\phi
ϕ,在task 1和task 2上目前表现并不是最好的,但是在task 1上,如果顺着左边的黑色箭头梯度下降,最终可以得到
θ
^
1
\hat \theta^1
θ^1;在task 2上,如果顺着右边的黑色箭头梯度下降,最终可以得到
θ
^
2
\hat \theta^2
θ^2。这两个都是最好的结果。

MAML的trick

在上面讲的MAML更新参数的过程中,一般只会更新一次:
θ
^
=
ϕ
−
ϵ
▽
ϕ
l
(
ϕ
)
\hat \theta=\phi-\epsilon\triangledown_{\phi}l(\phi)
θ^=ϕ−ϵ▽ϕl(ϕ)
原因如下:
• Fast … Fast … Fast …更新次数少,速度就快,因为MAML跑一轮需要几个小时。
• Good to truly train a model with one step. 就用一次更新就可以达到最佳作为目标来训练。
• When using the algorithm, still update many times.实作的时候在测试过程中可以更新个几次,没毛病。
• Few-shot learning has limited data.MAML对应的数据比较少,多次更新容易过拟合。
MAML Toy Example
Each task:
• 给定一个正弦函数
y
=
a
sin
(
x
+
b
)
y=a\text{sin}(x+b)
y=asin(x+b)作为target function;
• 从正弦函数中采样K个点作为样本;
• 用这K个样本来估计target function。

Model Pre-training做出的结果如下图所示:由于Model Pre-training是在所有task都最好的初始化
ϕ
\phi
ϕ,这里所有的正弦函数叠起来就是一条直线,所以它初始就是直线。

MAML的结果就很不错:

Warning of Math
先把手上的公式整理出来,GD更新公式为:
ϕ
←
ϕ
−
η
▽
ϕ
L
(
ϕ
)
(1)
\phi\leftarrow\phi-\eta\triangledown_{\phi}L(\phi)\tag1
ϕ←ϕ−η▽ϕL(ϕ)(1)
其中损失函数为每个任务的
l
l
l累加
L
(
ϕ
)
=
∑
n
=
1
N
l
n
(
θ
^
n
)
(2)
L(\phi)=\sum_{n=1}^Nl^n(\hat\theta^n)\tag2
L(ϕ)=n=1∑Nln(θ^n)(2)
其中参数
θ
^
n
\hat\theta^n
θ^n的计算公式为一步更新:
θ
^
=
ϕ
−
ϵ
▽
ϕ
l
(
ϕ
)
(3)
\hat \theta=\phi-\epsilon\triangledown_{\phi}l(\phi)\tag3
θ^=ϕ−ϵ▽ϕl(ϕ)(3)
先来整理计算公式1中的梯度优化项,把公式2代入公式1的梯度优化项中,并且把梯度放到求和函数里面去:
▽
ϕ
L
(
ϕ
)
=
▽
ϕ
∑
n
=
1
N
l
n
(
θ
^
n
)
=
∑
n
=
1
N
▽
ϕ
l
n
(
θ
^
n
)
\triangledown_{\phi}L(\phi)=\triangledown_{\phi}\sum_{n=1}^Nl^n(\hat\theta^n)=\sum_{n=1}^N\triangledown_{\phi}l^n(\hat\theta^n)
▽ϕL(ϕ)=▽ϕn=1∑Nln(θ^n)=n=1∑N▽ϕln(θ^n)
下面来看梯度
▽
ϕ
l
(
θ
^
)
\triangledown_{\phi}l(\hat\theta)
▽ϕl(θ^)的求法,实际上是对每一项求偏导:
▽
ϕ
l
(
θ
^
)
=
[
∂
l
(
θ
^
)
/
∂
ϕ
1
∂
l
(
θ
^
)
/
∂
ϕ
2
⋮
∂
l
(
θ
^
)
/
∂
ϕ
i
⋮
]
\triangledown_{\phi}l(\hat\theta)=\begin{bmatrix}\partial l(\hat\theta)/\partial \phi_1 \\ \partial l(\hat\theta)/\partial \phi_2 \\ \vdots \\ \partial l(\hat\theta)/\partial \phi_i \\ \vdots \end{bmatrix}
▽ϕl(θ^)=⎣⎢⎢⎢⎢⎢⎢⎡∂l(θ^)/∂ϕ1∂l(θ^)/∂ϕ2⋮∂l(θ^)/∂ϕi⋮⎦⎥⎥⎥⎥⎥⎥⎤
初始化参数
ϕ
i
\phi_i
ϕi是通过很多个
θ
^
\hat\theta
θ^来影响
l
(
θ
^
)
l(\hat\theta)
l(θ^):

根据链式法则:
∂
l
(
θ
^
)
∂
ϕ
i
=
∑
j
∂
l
(
θ
^
)
∂
θ
^
j
∂
θ
^
j
∂
ϕ
i
(4)
\cfrac{\partial l(\hat\theta)}{\partial \phi_i}=\sum_j\cfrac{\partial l(\hat\theta)}{\partial \hat\theta_j}\cfrac{\partial \hat\theta_j}{\partial \phi_i}\tag4
∂ϕi∂l(θ^)=j∑∂θ^j∂l(θ^)∂ϕi∂θ^j(4)
上式中
∂
l
(
θ
^
)
∂
θ
^
j
\cfrac{\partial l(\hat\theta)}{\partial \hat\theta_j}
∂θ^j∂l(θ^)很好计算,根据损失函数l的形式直接求即可,例如l如果是交叉熵,就用交叉熵求偏导即可。重点来看后面这项:
∂
θ
^
j
∂
ϕ
i
\cfrac{\partial \hat\theta_j}{\partial \phi_i}
∂ϕi∂θ^j
根据公式3可知,
θ
^
\hat\theta
θ^是一个向量,所以我们可以找其中一个分量:
θ
^
j
\hat\theta_j
θ^j,由公式3可得:
θ
^
j
=
ϕ
j
−
ϵ
▽
ϕ
j
l
(
ϕ
)
=
ϕ
j
−
ϵ
∂
l
(
ϕ
)
∂
ϕ
j
(5)
\hat\theta_j=\phi_j-\epsilon\triangledown_{\phi_j}l(\phi)=\phi_j-\epsilon\cfrac{\partial l(\phi)}{\partial\phi_j}\tag5
θ^j=ϕj−ϵ▽ϕjl(ϕ)=ϕj−ϵ∂ϕj∂l(ϕ)(5)
对公式5中求
ϕ
i
\phi_i
ϕi的偏导:
当
i
≠
j
i\neq j
i=j时
∂
θ
^
j
∂
ϕ
i
=
−
ϵ
∂
l
(
ϕ
)
∂
ϕ
i
∂
ϕ
j
\cfrac{\partial \hat\theta_j}{\partial \phi_i}=-\epsilon\cfrac{\partial l(\phi)}{\partial\phi_i\partial\phi_j}
∂ϕi∂θ^j=−ϵ∂ϕi∂ϕj∂l(ϕ)
当
i
=
j
i= j
i=j时
∂
θ
^
j
∂
ϕ
i
=
1
−
ϵ
∂
l
(
ϕ
)
∂
ϕ
i
∂
ϕ
j
\cfrac{\partial \hat\theta_j}{\partial \phi_i}=1-\epsilon\cfrac{\partial l(\phi)}{\partial\phi_i\partial\phi_j}
∂ϕi∂θ^j=1−ϵ∂ϕi∂ϕj∂l(ϕ)
算二次偏导很麻烦,原论文提出忽略二次偏导项:
当
i
≠
j
i\neq j
i=j时
∂
θ
^
j
∂
ϕ
i
=
−
ϵ
∂
l
(
ϕ
)
∂
ϕ
i
∂
ϕ
j
≈
0
(6)
\cfrac{\partial \hat\theta_j}{\partial \phi_i}=-\epsilon\cfrac{\partial l(\phi)}{\partial\phi_i\partial\phi_j}\approx 0\tag6
∂ϕi∂θ^j=−ϵ∂ϕi∂ϕj∂l(ϕ)≈0(6)
当
i
=
j
i= j
i=j时
∂
θ
^
j
∂
ϕ
i
=
1
−
ϵ
∂
l
(
ϕ
)
∂
ϕ
i
∂
ϕ
j
≈
1
(7)
\cfrac{\partial \hat\theta_j}{\partial \phi_i}=1-\epsilon\cfrac{\partial l(\phi)}{\partial\phi_i\partial\phi_j}\approx 1\tag7
∂ϕi∂θ^j=1−ϵ∂ϕi∂ϕj∂l(ϕ)≈1(7)
把公式6和公式7代入公式4,由于当
i
≠
j
i\neq j
i=j时,
∂
θ
^
j
∂
ϕ
i
=
0
\cfrac{\partial \hat\theta_j}{\partial \phi_i}=0
∂ϕi∂θ^j=0,所以求和的时候只用考虑
i
=
j
i= j
i=j的情况,即公式4可以写为:
∂
l
(
θ
^
)
∂
ϕ
i
=
∑
j
∂
l
(
θ
^
)
∂
θ
^
j
∂
θ
^
j
∂
ϕ
i
≈
∂
l
(
θ
^
)
∂
θ
^
i
(8)
\cfrac{\partial l(\hat\theta)}{\partial \phi_i}=\sum_j\cfrac{\partial l(\hat\theta)}{\partial \hat\theta_j}\cfrac{\partial \hat\theta_j}{\partial \phi_i}\approx\cfrac{\partial l(\hat\theta)}{\partial \hat\theta_i}\tag8
∂ϕi∂l(θ^)=j∑∂θ^j∂l(θ^)∂ϕi∂θ^j≈∂θ^i∂l(θ^)(8)
利用公式8的估计,梯度矩阵就变成了:
▽
ϕ
l
(
θ
^
)
=
[
∂
l
(
θ
^
)
/
∂
ϕ
1
∂
l
(
θ
^
)
/
∂
ϕ
2
⋮
∂
l
(
θ
^
)
/
∂
ϕ
i
⋮
]
=
[
∂
l
(
θ
^
)
/
∂
θ
^
1
∂
l
(
θ
^
)
/
∂
θ
^
2
⋮
∂
l
(
θ
^
)
/
∂
θ
^
i
⋮
]
=
▽
θ
^
l
(
θ
^
)
\triangledown_{\phi}l(\hat\theta)=\begin{bmatrix}\partial l(\hat\theta)/\partial \phi_1 \\ \partial l(\hat\theta)/\partial \phi_2 \\ \vdots \\ \partial l(\hat\theta)/\partial \phi_i \\ \vdots \end{bmatrix}=\begin{bmatrix}\partial l(\hat\theta)/\partial \hat\theta_1 \\ \partial l(\hat\theta)/\partial \hat\theta_2 \\ \vdots \\ \partial l(\hat\theta)/\partial \hat\theta_i \\ \vdots \end{bmatrix}=\triangledown_{\hat\theta}l(\hat\theta)
▽ϕl(θ^)=⎣⎢⎢⎢⎢⎢⎢⎡∂l(θ^)/∂ϕ1∂l(θ^)/∂ϕ2⋮∂l(θ^)/∂ϕi⋮⎦⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎡∂l(θ^)/∂θ^1∂l(θ^)/∂θ^2⋮∂l(θ^)/∂θ^i⋮⎦⎥⎥⎥⎥⎥⎥⎤=▽θ^l(θ^)
最后我们的梯度优化项就变成了:
▽
ϕ
L
(
ϕ
)
=
▽
ϕ
∑
n
=
1
N
l
n
(
θ
^
n
)
=
∑
n
=
1
N
▽
ϕ
l
n
(
θ
^
n
)
=
∑
n
=
1
N
▽
θ
^
n
l
n
(
θ
^
n
)
\triangledown_{\phi}L(\phi)=\triangledown_{\phi}\sum_{n=1}^Nl^n(\hat\theta^n)=\sum_{n=1}^N\triangledown_{\phi}l^n(\hat\theta^n)=\sum_{n=1}^N\triangledown_{\hat\theta^n}l^n(\hat\theta^n)
▽ϕL(ϕ)=▽ϕn=1∑Nln(θ^n)=n=1∑N▽ϕln(θ^n)=n=1∑N▽θ^nln(θ^n)
MAML – Real Implementation
先要有一个初始化参数,然后把一个任务task看做是一个sample,当然可以用多个任务组成mini-batch,然后做GD,这里不用batch,而是用SGD:
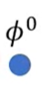
先取一个任务m(Sample a training task m),然后更新参数得到
θ
^
m
\hat\theta^m
θ^m
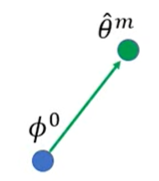
虽然说好只更新一次,但是这里还是更新两次:

这里我们计算
θ
^
m
\hat\theta^m
θ^m的偏导,取其方向作为
ϕ
0
\phi^0
ϕ0的梯度更新方向:

这里需要注意,同向的绿色和蓝色箭头不一定等长,因为LR可能不一样。
然后取一个任务n(Sample a training task n)同样用
ϕ
1
\phi^1
ϕ1计算出
θ
^
n
\hat\theta^n
θ^n以及
θ
^
n
\hat\theta^n
θ^n的下一次梯度方向

取其方向作为
ϕ
1
\phi^1
ϕ1的梯度更新方向:
这里需要注意,同向的黄色和蓝色箭头不一定等长,因为LR可能不一样。

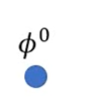
再次对比transfer learning的Model Pre-training在实现上和MAML有什么不一样:
现有一个初始化参数:
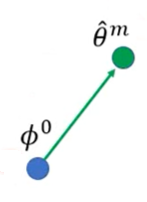
然后计算
θ
^
m
\hat\theta^m
θ^m
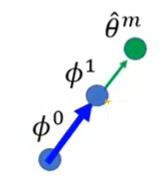
然后沿着绿色箭头更新
ϕ
0
\phi^0
ϕ0
然后不断重复:

MAML 应用:Translation
Meta-Learning for Low-Resource Neural Machine Translation
18 training tasks: 18 different languages translating to English
2 validation tasks: 2 different languages translating to English
实验结果中用的是BLEU来做评估,横轴是数据量,当然数据量越大效果越好。
Baseline是多任务学习。
先看验证集结果,罗马语翻译为英文

测试任务结果,法语翻译英文

Reptile(简单介绍)
https://openai.com/blog/reptile/
现有初始化参数
ϕ
0
\phi^0
ϕ0
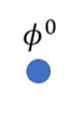
取一个任务m(Sample a training task m),Reptile没有规定只能更新一次参数,因此:

从
ϕ
0
\phi^0
ϕ0到
θ
^
m
\hat\theta^m
θ^m方向就是
ϕ
0
\phi^0
ϕ0更新的方向:

计算出
ϕ
1
\phi^1
ϕ1后,取一个任务n(Sample a training task n)同样用
ϕ
1
\phi^1
ϕ1计算出
θ
^
n
\hat\theta^n
θ^n并更新多次,取
ϕ
1
\phi^1
ϕ1到
θ
^
n
\hat\theta^n
θ^n的方向作为
ϕ
1
\phi^1
ϕ1的更新方向:

把pre-train,MAML,Reptile都放在一起看下有什么区别:
下面
g
1
g_1
g1是pre-train的更新方向
g
2
g_2
g2是MAML的更新方向
g
1
+
g
2
g_1+g_2
g1+g2是Reptile的更新方向,当然还可以更新更多次

实验结果比较:

MAML和Reptile其实不分上下,但是最下面那个蓝色是Transfer learning。
More about Meta Learning
上面讲的MAML和Reptile都是关于用Meta Learning来找初始化参数这个事情,那我们在介绍Meta Learning的时候还有很多红色框框,这些也是可以用Meta Learning来进行研究如何学习的。
不过弹幕提示:只有初始化参数这里可以用GD
下图是用network来设计Architecture & Activation,以及如何更新参数。
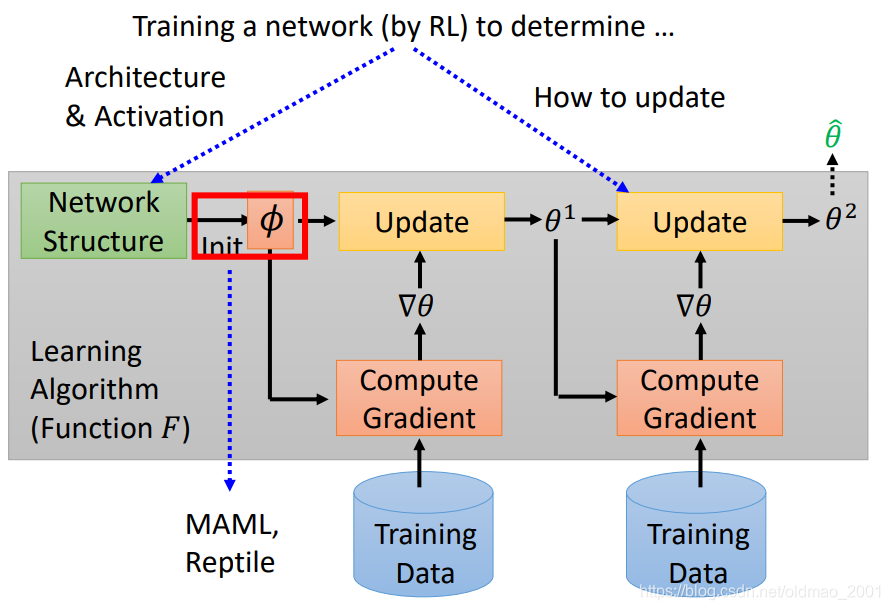
下面套娃预警:
We learn the initialization parameter
ϕ
\phi
ϕ by gradient descent.
What is the initialization parameter
ϕ
0
\phi^0
ϕ0 for initialization parameter
ϕ
\phi
ϕ?

How about learning algorithm beyond gradient descent?
















 1274
1274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











