









该节主要是把《机器学习实战》书上第三章关于决策树的相关代码照样子实现了一遍。对其中一些内容作了些补充,对比ID3与C45区别,同时下载了一个大样本集实验决策树的准确率。
首先,对于决策树的原理,很多很好的博客值得一看:
这两个已经详解了关于决策树的所有,慢慢品读吧。
下面是书上外加添加的部分程序,首先是tree.py里面的程序:
import operator
from math import log
# calculate the data's entropy
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]#load data's label
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2)
return shannonEnt
# spilt the data's axis feature as value
def spiltDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:]) #as a simple
retDataSet.append(reducedFeatVec) #as a total
return retDataSet
# choose the best feature:ID3
def chooseBestFeatureToSplit_ID3(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0;bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = spiltDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
# choose the best feature:C45
def chooseBestFeatureToSplit_C45(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0;bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
splitInfo = 0.0
for value in uniqueVals:
subDataSet = spiltDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
splitInfo -= prob * log(prob,2) #记录分裂信息
infoGain = baseEntropy - newEntropy
gainRatio = infoGain / splitInfo #信息增益率
if (gainRatio > bestInfoGain):
bestInfoGain = gainRatio
bestFeature = i
return bestFeature
# if classList has only one feature,but cannot spilt all
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(),
key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
# create tree
# method = 'ID3' or 'C45'
def createTree(dataSet,labels,method):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
if method == 'ID3':
bestFeat = chooseBestFeatureToSplit_ID3(dataSet)
else:
bestFeat = chooseBestFeatureToSplit_C45(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat]) #delate the 'bestFeat' label
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(spiltDataSet\
(dataSet,bestFeat,value),subLabels,method)
return myTree
# define classify
def classify(inputTree,featLabels,testVec):
firstStr = inputTree.keys()[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
global classLabel
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__=='dict':
classLabel = classify(secondDict[key],featLabels,testVec)
else:
classLabel = secondDict[key]
return classLabel关于程序的讲解,书上说的非常的详细。添加的部分多了个C45算法。决策树从ID3到C45的转变不是很多,从原理上也可以看到,单纯从算法,就是用信息增益率代表信息增益,这一点带来的变化一会做个实验可以看到。
为了使得结果的可视化,书中写了一些画图函数,这里直接搬上来吧,另存在terrPlotter.py中:
import matplotlib.pyplot as plt
#
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
# get the weight anddepth
def getNumLeafs(myTree):
numLeafs = 0
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
#
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args )
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt):#if the first key tells you what feat was split on
numLeafs = getNumLeafs(myTree) #this determines the x width of this tree
#depth = getTreeDepth(myTree)
firstStr = myTree.keys()[0] #the text label for this node should be this
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':#test to see if the nodes are dictonaires, if not they are leaf nodes
plotTree(secondDict[key],cntrPt,str(key)) #recursion
else: #it's a leaf node print the leaf node
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #no ticks
#createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0;
plotTree(inTree, (0.5,1.0), '')
plt.show()使用的时候加载进去,然后在决策树训练好以后,直接treePlotter.createPlot(Tree)就可以了,至于画图的中间计算过程,有兴趣可以再慢慢研究。
好了有了这些可以进行实验了。首先实验一个小样本的决策树(也是书上的样本),下载地址:
http://archive.ics.uci.edu/ml/datasets/Lenses
为了和后面对比,这里得到样本就是这样的(24个样本,4维特征,分成三类(最后一列)):

写一个这样的主程序:
import tree
import treePlotter
fr = open('lenses.txt')
lenses=[inst.strip().split('\t') for inst in fr.readlines()]
lensesLabels=['age','prescript','astigmatic','tearRate','add']
lensesTree = tree.createTree(lenses,lensesLabels,'ID3')
treePlotter.createPlot(lensesTree)可以看到结果是这样的:
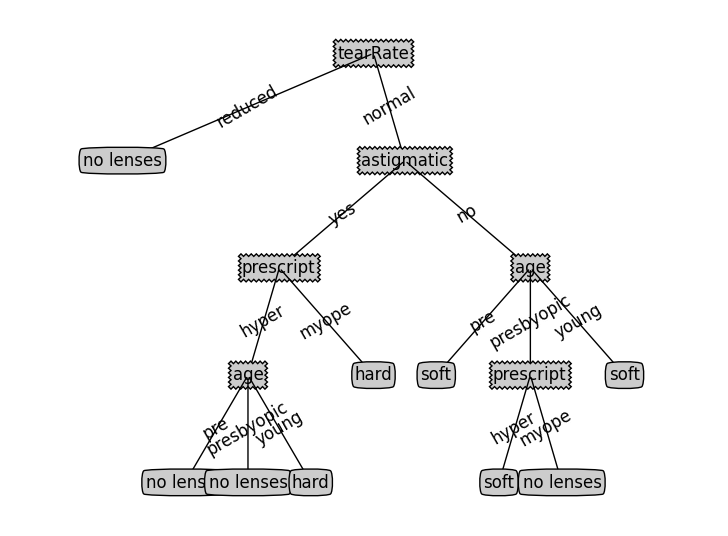
下面来说说使用C45,那么为什么需要C45算法?使用C45算法的目的是去除某些特征划分的太细太纯。由于信息增益选择分裂属性的方式会倾向于选择具有大量值的属性(即自变量),如对于客户ID,每个客户ID对应一个满意度,即按此变量划分每个划分都是纯的(即完全的划分,只有属于一个类别),客户ID的信息增益为最大值1。但这种按该自变量的每个值进行分类的方式是没有任何意义的。为了克服这一弊端,才采用信息增益率来选择分裂属性。
比如这里我们对上述的数据集再加一维特征,这个特征值对于每个样本都不一样,我们就用数字1-24来表示吧,加以后的数据另存为lensesC.txt以后,在分别用ID3和C45去实验看看,加后的数据是这样的:

import tree
import treePlotter
fr = open('lensesC.txt')
lenses=[inst.strip().split('\t') for inst in fr.readlines()]
lensesLabels=['age','prescript','astigmatic','tearRate','num']
lensesTree = tree.createTree(lenses,lensesLabels,'ID3')
treePlotter.createPlot(lensesTree)那么ID3的结果:
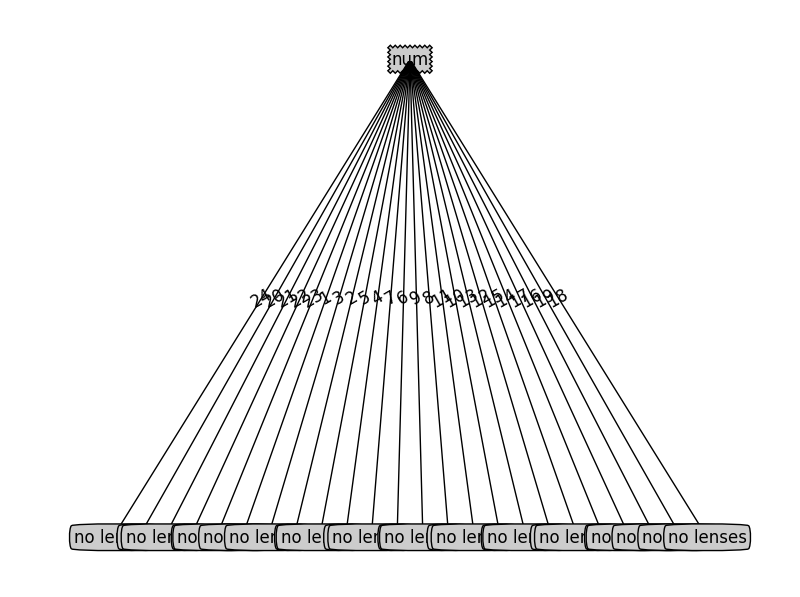
修改lensesTree = tree.createTree(lenses,lensesLabels,’C45’)得到C45的结果:
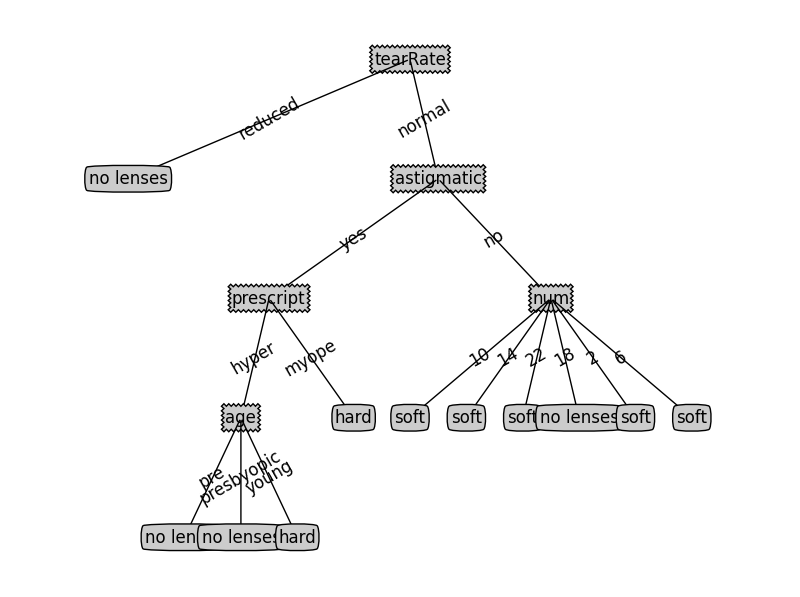
很显然,C45似乎更符合实际。
下面来使用决策树算法进行一个分类预测,样本我们选择大一些的,维数多一些的,需要说明的是,这里的算法只适用于所有特征都是离散量化的,不能有连续的特征,如果有,需要删掉这一维数据或者自己去把它进行离散化,离散化的方法很多,比如对于连续的数据,可以设置一个阈值,然后将大于该阈值的设置为统一的一个值,小于该阈值的设置为一个值,这样就把连续的变量变成了一个离散的变量,变量包含两个值。下面是含有8维数据的12000多个样本集,每一维都是离散的,免去转换的痛苦,数据下载地址:
http://archive.ics.uci.edu/ml/datasets/Nursery
下载完,另存为txt放到工作目录下,然后我们就可以实验了。这里我们可以规定训练集与样本集了。为了保证随机性,我们随机将其中的一部分选择作为训练集来构造决策树,再用剩下的测试集去测试准确率,至于怎么去划分类,在tree.py中也有一个classify函数去实现。现在我们选择2000个样本试试:
import tree
import treePlotter
from numpy import *
# 将字符型运算统一,否则会出现错误
import sys
reload(sys)
sys.setdefaultencoding('utf8')
fr = open('data_nursery.txt')
data = [inst.strip().split(',') for inst in fr.readlines()]
choose = random.permutation(len(data)) #随机排序
test1 = []
test2 = []
# 选择训练集样本个数
choose_num = 2000
for i in range(choose_num):
temp = data[choose[i]]
test1.append(temp)
for i in range(len(data)-choose_num):
temp = data[choose[choose_num+i]]
test2.append(temp)
lensesLabels=['parents','has_nurs','form','childreb','housing','finance','social','health']
lensesTree = tree.createTree(test1,lensesLabels,'ID3')
#calculate the accuracy
true_num = 0
lensesLabels=['parents','has_nurs','form','childreb','housing','finance','social','health']
for test_vector in test2:
classLabel = tree.classify(lensesTree,lensesLabels,test_vector)
if classLabel == test_vector[-1]:
true_num += 1
accuracy = float(true_num)/len(test2)
print 'The classify accuracy is: %.2f%%'%(accuracy * 100)
treePlotter.createPlot(lensesTree)得到的一个结果:
The classify accuracy is: 91.09%
由于维数太多,画出来的图难以显示清楚,就不贴出来了。因为训练样本的随机选择,每次计算的结果不一样。这种决策树还有许多优化的地方,比如修枝剪枝操作会使得决策树不至于过拟合等等,还有待改进。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









