






Gong, J., Foo, L. G., Fan, Z., Ke, Q., Rahmani, H., & Liu, J. (2022). DiffPose: Toward More Reliable 3D Pose Estimation. In arXiv [cs.CV] (pp. 13041–13051). arXiv. http://openaccess.thecvf.com/content/CVPR2023/html/Gong_DiffPose_Toward_More_Reliable_3D_Pose_Estimation_CVPR_2023_paper.html
代码地址
DifPose: 迈向更可靠的3D姿态估计
由于固有的模糊性和遮挡,单目3D人体姿态估计是相当具有挑战性的,这经常导致高度的不确定性和不确定性。另一方面,扩散模型最近已经成为从噪声生成高质量图像的有效工具。受到它们能力的启发,我们探索了一种新颖的姿态估计框架(DiffPose),将3D姿态估计形式化为一个反向扩散过程。我们在DiffPose中引入了新颖的设计,以促进3D姿态估计的扩散过程:一种姿态特定的姿态不确定性分布的初始化,基于高斯混合模型的前向扩散过程以及一个上下文条件的反向扩散过程。我们提出的DiffPose在广泛使用的姿态估计基准Human3.6M和MPI-INF-3DHP上明显优于现有方法。项目页面:https://gongjia0208.github.io/Diffpose/。
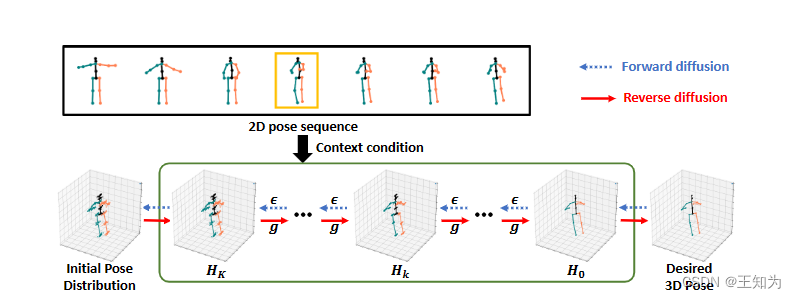
图1. 我们的DiffPose框架概览。在前向过程(用蓝色虚线箭头表示),我们通过在每一步添加噪声ε,逐渐将“ground truth” 3D姿态分布H₀从低不确定性扩散到具有高不确定性的3D姿态分布Hₖ,从而生成中间分布以引导模型训练。在反向过程之前,我们首先从输入中初始化不确定的3D姿态分布Hₖ。然后,在反向过程中(用红色实线箭头表示),我们使用扩散模型g,根据来自2D姿态序列的上下文信息进行条件化,逐步将Hₖ转化为具有低不确定性的3D姿态分布H₀。
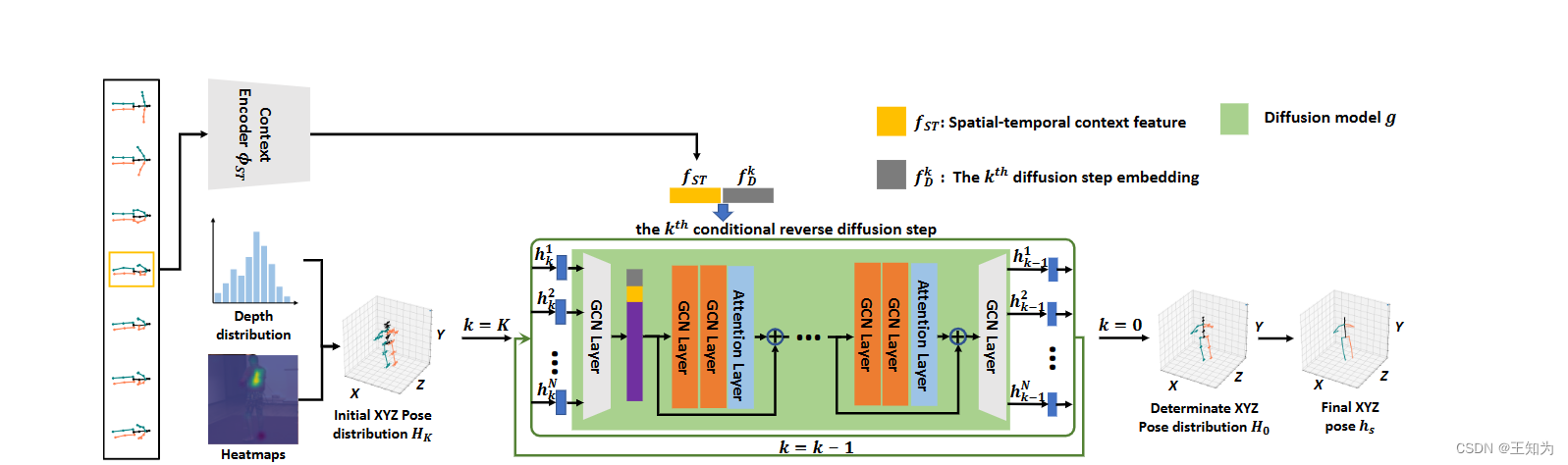
图2. 我们的DiffPose框架在推断过程中的示意图。首先,我们使用上下文编码器 φST 从给定的2D姿态序列中提取空间-时间上下文特征 fST。我们还为每个扩散步骤生成扩散步骤嵌入 fkD。然后,我们使用来自现成的2D姿态检测器的热图和可以从训练集计算或由上下文编码器 φST 预测的深度分布,初始化不确定的姿态分布 Hₖ。接下来,我们从 Hₖ 中采样 N 个噪声姿态 {hiₖ}ᴺᵢ₌₁,这些姿态是执行分布到分布映射所需的。我们将这 N 个姿态传入扩散模型 K 次,其中扩散模型 g 在每一步也受到 fST 和 fkD 的条件影响,以获得代表高质量确定性分布 H₀ 的 {hi₀}ᴺᵢ₌₁。最后,我们使用 {hi₀}ᴺᵢ₌₁ 的均值作为我们最终的3D姿态 hs。
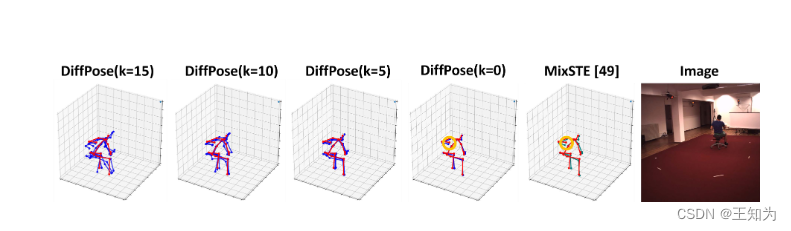
图3. 定性结果。红色的3D姿态对应于地面真相。在遮挡情况下,我们的DiffPose预测的姿态比先前的方法更准确(用橙色圈出)。
















 1227
1227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











