







paper:Learning Deep Features for Discriminative Localization
official implementation:https://github.com/zhoubolei/CAM
一般的分类模型,前面有若干层卷积层,最后一层卷积层的输出接一个全局平均池化层,然后是全连接层,然后通过softmax得到最终输出。假设最后一层卷积层维度为 \(H\times W\times K\),经过全局平局池化后得到一个 \(1\times 1\times K\) 的特征向量,然后经过全连接层 \(W\in \mathbb{R}^{K\times C}\) 输出一个 \(C\) 维的向量,这里 \(C\) 就是实际的类别数。最后输出接softmax得到每一类的概率,取概率最大的类别作为模型预测的类别。
每一个类别的输出对应一组权重系数 \(W_{c}\in \mathbb{R}^{K}\),通过这组权重对global average pooling的输出加权求和得到该类别的输出。CAM的做法是对全局平均池化前的结果进行加权求和,这样最终得到的一个 \(H\times W\times 1\) 的特征图,而不是一个值,如下所示
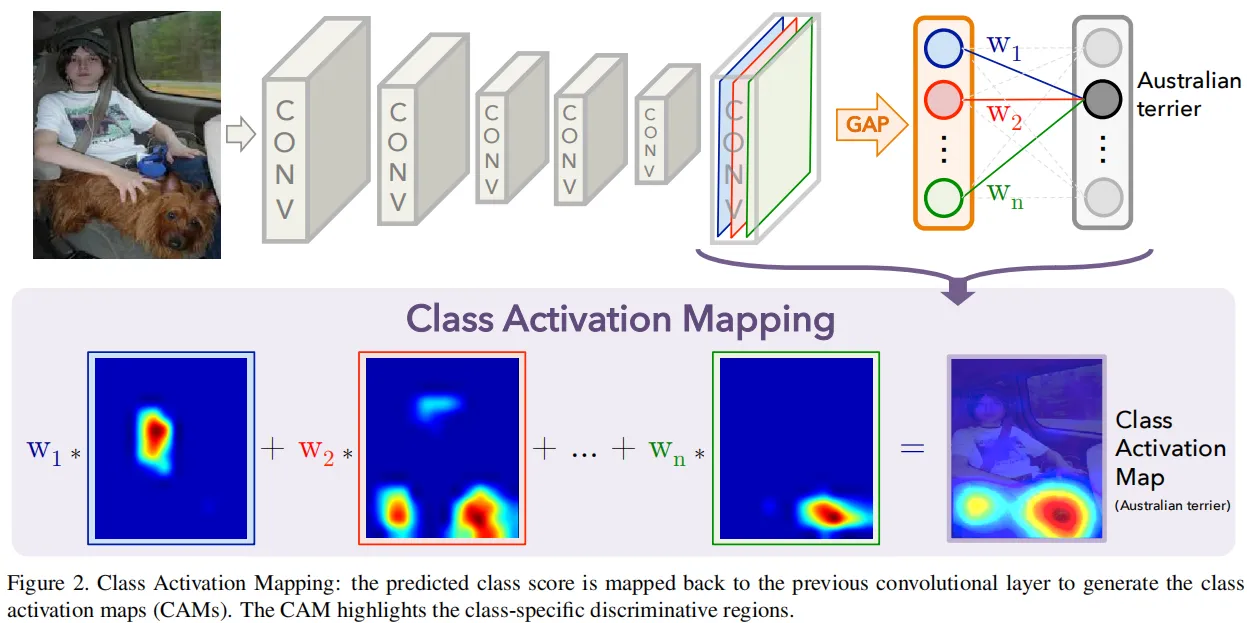
这张类激活热力图(class activation map)中响应高或者说值大的区域对该类别的贡献更大,即突出显示图中哪些区域对该类的识别更重要。
















 1762
1762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











