









paper:EfficientFormer: Vision Transformers at MobileNet Speed
official implementation:GitHub - snap-research/EfficientFormer: EfficientFormerV2 [ICCV 2023] & EfficientFormer [NeurIPs 2022]
third-party implementation:pytorch-image-models/timm/models/efficientformer.py at main · huggingface/pytorch-image-models · GitHub
出发点
虽然 ViT 模型在计算机视觉任务中取得了显著进展,但由于参数数量巨大和模型设计(如注意力机制)的原因,其推理速度通常比轻量级卷积网络(如 MobileNet)慢许多。因此,在资源受限的硬件(如移动设备)上部署 ViT 具有很大的挑战。
为了使 Transformer 模型能够在移动设备上实现高性能且低延迟的推理,本文研究了现有 ViT 模型的设计缺陷,并提出了一种新的维度一致的纯 Transformer 设计范式。通过延迟驱动的瘦身方法,EfficientFormer 系列模型在性能和速度上都表现出了显著的优势。
方法介绍
On-Device Latency Analysis of Vision Transformers
为了清楚地理解哪些操作和设计选择减慢了边缘设备上的ViTs的推理速度,作者对许多模型和操作进行了全面的延迟分析,如图2所示,由此得出以下观察结果
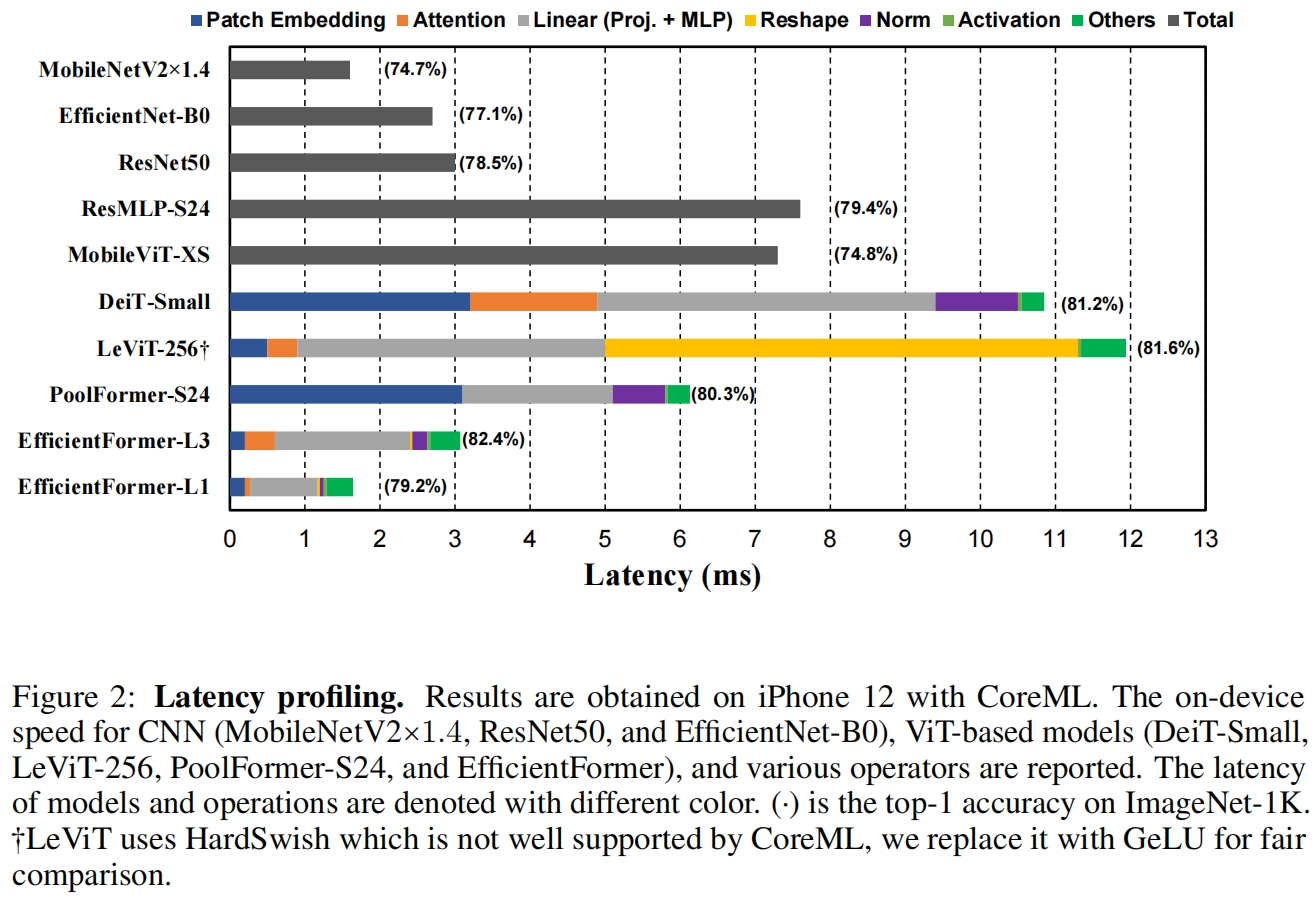
- 具有大的kernel size和stride的patch embedding是移动设备上的速度瓶颈
patch embedding通常通过具有大的卷积核和步长的不重叠的卷积实现,如图2所示,DeiT-S和PoolFormer-S24是有这种patch embedding层的模型,而LeViT-256和EfficientFormer没有,可以看到patch embedding确实是移动设备上的速度瓶颈。大多数编译器都没有很好地支持大核卷积,也无法通过像Winograd这种现有算法来进行加速。但是这种非重叠的patch embedding层可以用一个快速下采样的卷积stem代替,其中包含若干hardware-efficient的3x3卷积。
- 一致的特征维度对于token mixer的选择非常重要。MHSA不一定是速度瓶颈。
最近的工作将基于ViT的模型扩展到由MLP block和未指定具体类型的token mixer组成的MetaFormer结构(具体介绍见MetaFormer(CVPR 2022)-CSDN博客),其中token mixer的选择有很多比如传统的具有全局感受野多头自注意力(Multi-Head Self-Attention, MHSA)、更复杂的shifted window attention或没有可学习参数的operator比如pooling。我们将比较范围缩小到其中两个,池化和MHSA,选择前者因为其简单和效率,后者因为更好的性能。为了了解这两个token mixer的延迟,作者进行了下面两个比较:
- 通过比较PoolFormer-s24和LeViT-256,我们观察到
Reshape操作是LeViT-256的瓶颈。LeViT-256大部分是在4D张量上使用CONV实现的,当将特征传给MHSA时需要频繁的reshape操作,因为attention是在patchified 3D张量上执行的。大量使用reshape操作限制了LeViT在移动设备上的速度。另一方面当网络主要由基于CONV的实现组成时(例如1x1 Conv作为MLP实现,Conv stem用于降采样),pooling自然适合于4D张量。因此PoolFormer的推理速度更快。 - 通过比较DeiT-Small和LeViT-256,如果特征维度是一致的并且不需要reshape,那么MHSA并不会给移动设备带来显著的开销。
本文作者提出了一个维度一致的网络,其中既有4D特征的实现也有3D的MHSA,但低效的频繁reshape操作被抛弃。
- CONV-BN在延迟方面比LN (GN)-Linear更有利,且精度的下降通常可以接受。
选择MLP的具体实现是另外一个基本的设计选择。通常有两个选择:LayerNorm(LN)和3D的线性映射(proj.)以及1x1卷积和BatchNorm(BN)。CONV-BN更有利于延迟因为BN可以融合到前面的卷积中实现加速推理,而动态规划化例如LN和GN在推理阶段仍然那需要收集running statistics从而导致推理速度变慢。从图2中对DeiT-Small和PoolFormer-S24的分析来看,LN的延迟占整个网络的10%-20%。
基于后续消融实验的结果,与GN相比CONV-BN的性能略微降低,但和LN相当。因此本文作者尽可能的使用CONV-BN(在所有潜在的4D特征中)以可以忽略的性能下降来获得延迟上的提升。而在3D特征上使用LN,这与ViT中MHSA最初的设计保持一致并能得到更好的精度。
- 非线性的延迟依赖于硬件和编译器。
最后作者研究了非线性包括GeLU、ReLU和HardSwish。之前的工作表示GeLU在硬件上效率低下推理速度慢,但作者观察到GeLU被iPhone 12很好地支持,并且不比ReLU慢。相反HardSwish的速度非常慢并且编译器可能不支持(LeViT-256用GeLU延迟11.9ms用HardSwish延迟44.5ms)。作者的结论是,非线性应该根据具体的硬件和编译器来选择,本文作者使用GeLU。
Design of EfficientFormer
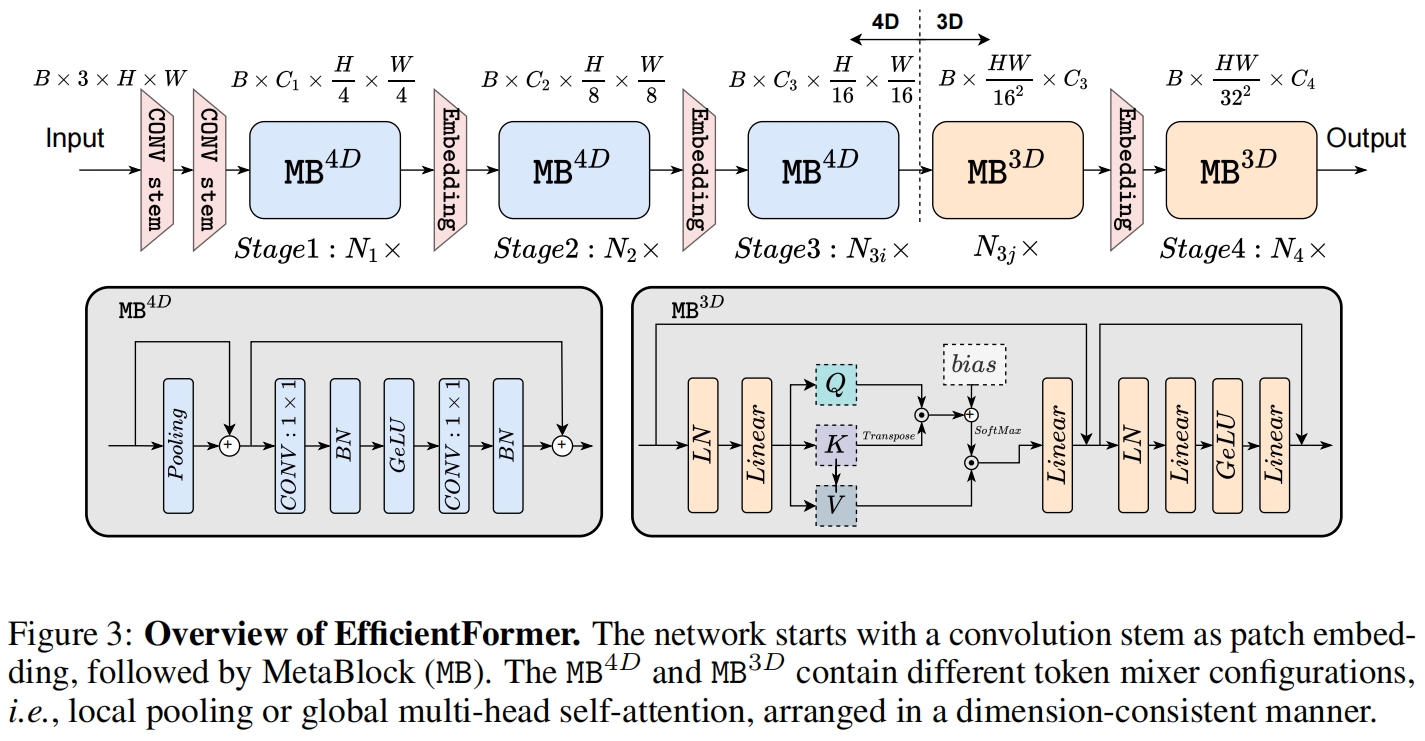
基于延迟的分析,作者提出了EfficientFormer的设计,如图3所示。网络由一个patch embedding和若干meta transformer block组成,表示为MB
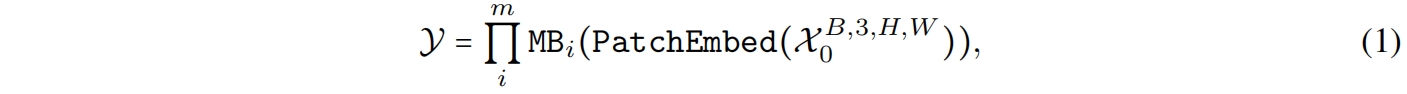
其中 \(\mathcal{X}_0\) 是输入图片,batch size为 \(B\),宽高为 \([H,W]\),\(\mathcal{Y}\) 是期望输出,\(m\) 是block数量(depth)。MB包括未指定的token mixer(Tokenmixer)跟着一个MLP block,表示如下
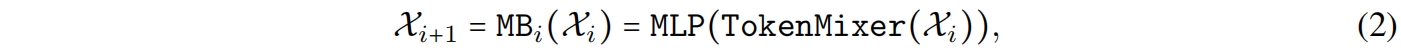
其中 \(\mathcal{X}_{i|i>0}\) 是将要传入 \(i^{th}\) MB的中间特征。我们进一步将Stage(或S)定义为堆叠的若干处理相同大小特征的MetaBlock,比如图3中的 \(N_1\times\) 表示 \(S_1\) 有 \(N_1\) 个MetaBlocks。网络总共包含4个stage,每个stage有一个embedding操作用来映射特征维度并降采样token length,在图3中用Embedding表示。通过上述结构,EfficientFormer是一个完全基于transformer的结构,没有集成MobileNet结构。接下来,我们将深入研究网络设计的细节,特别是架构细节和搜索算法。
Dimension-Consistent Desing
基于之前的观察结果,作者提出了一个维度一致的设计,将网络划分为一个4D分区其中的算子以CONV-net形式(\(MB^{4D}\))执行,和一个3D分区其中在3D张量上进行线性映射和计算attention从而在不牺牲效率的前提下又可以充分利用MHSA的全局建模能力(\(MB^{3D}\)),如图3所示。具体来说网络开始的stage使用4D partition,最后一个stage使用3D partition。注意图3只是一个示例,4D分区和3D分区的具体长度通过架构搜索指定。
首先输入图片经过一个CONV stem处理,其中两个stride=2的3x3卷积作为patch embedding
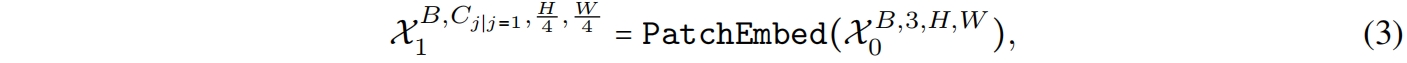
其中 \(C_j\) 是第 \(j\) 个stage的通道数(宽度)。然后网络从一个\(MB^{4D}\)开始,用一个简单的Pool mixer来提取低层特征
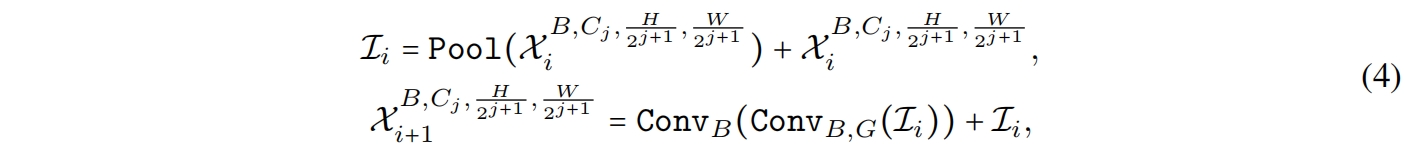
其中 \(Conv_{B,G}\) 指卷积后是否有BN和ReLU。注意这里不像原始的PoolFormer中那样在Pool mixer前使用Group或Layer Norm,因为4D分区是基于CONV-BN的设计,所以这里每个Pool mixer前有一个BN。
在执行完所有的 \(MB^{4D}\) block后,我们执行一次reshaping操作转换特征尺度然后进入3D分区。\(MB^{3D}\) 遵循传统的ViT结构,如图3所示
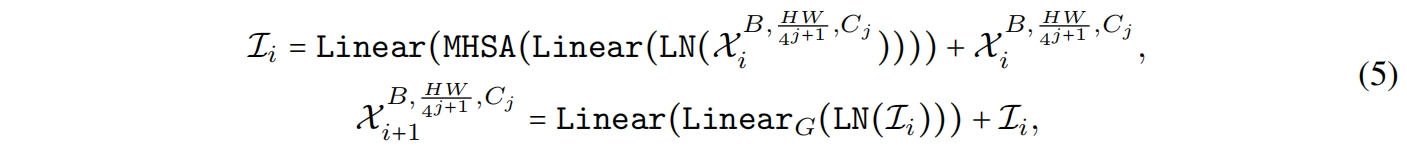
其中 \(Linear_G\) 表示线性层后跟一个GeLU,并且其中

其中 \(Q,K,V\) 表示线性映射学习到的query, key, value,\(b\) 是参数化的attention bias作为position encoding。
Latency Driven Slimming
Design of Supernet. 在维度一致设计的基础上,作者设计了一个supernet来搜索上述网络设计的具体模型(图3就是一个搜索到的具体模型)。为了表示这样一个supernet,作者定义了MetaPath(MP),它表示一个候选block的集和
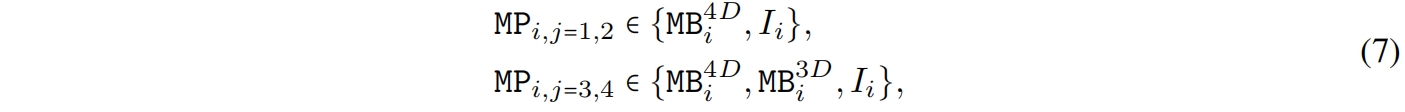
其中 \(I\) 表示identity path,\(j\) 表示第 \(j\) 个stage,\(i\) 表示第 \(i\) 个block。将图3中的MB换成MP就是supernet的图示。
如式(7)所示,supernet的 \(S_1,S_2\) 中block的具体结构可以从 \(MB^{4D}\) 或 \(I\) 中选择,而在 \(S_3,S_4\) 中,block可以从 \(MB^{3D},MB^{4D},I\) 中选择。我们只在后两个stage启用 \(MB^{3D}\) 有两个原因,首先MHSA的计算量和token length呈二次方关系,在早期的stage中使用大大增加计算成本。其次在最后一个stage使用MHSA符合直觉,即网络的早期阶段捕获低级特征,而后期阶段学习长距离依赖。
Searching space. 搜索空间包括每个stage的宽度 \(C_j\),每个stage的block数量即深度 \(N_j\),以及最后 \(\mathbb{N}\) 个block使用 \(MB^{3D}\)。
Searching Algorithm. 以往的硬件感知网络搜索方法通常依赖于在搜索空间中对每个候选对象的硬件部署来获得延迟,这是非常耗时的。本文作者提出了一个简单快速有效的基于梯度的搜索算法来获得一个候选网络,只需要训练supernet一次。该算法有三个主要步骤。
首先我们用Gumbel Softmax sampling训练supernet,得到每个MP中每个block的重要性得分,表示为

其中 \(\alpha\) 评估了MP中每个block的重要性,因为它表示选择一个block的概率。\(\epsilon \sim U(0,1)\) ensures exploration,\(\tau\) 是温度,\(n\) 表示MP中block的类型,即对于 \(S_1,S_2\),\(n\in\{4D,I\}\),对于 \(S_3,S_4\),\(n\in\{4D,3D,I\}\)。通过式(8),相对网络权重和 \(\alpha\) 的导数可以很容易的计算得到。
第二步,我们收集设备上不同宽度(16的倍数)的 \(MB^{3D}\) 和 \(MB^{4D}\) 的延迟来构建一个延迟查找表latency lookup table。
第三步,我们使用查找表评估延迟来对第一步得到的supernet进行network slimming。注意一个典型的基于梯度的搜索算法只是选择 \(\alpha\) 最大的block,这不适合我们因为它不能搜索宽度 \(C_j\)。实际上构建一个multi-width的supernet非常消耗内存甚至无法实现因为在我们的设计中每个MP都有若干分支。所以我们不是直接在复杂的搜索空间中进行搜索,而是在一个single-width的supernet上进行逐步的瘦身。
我们首先定义 \(MP_i\) 的重要性分数,对于 \(S_{1,2}\) 为 \(\frac{\alpha_i^{4D}}{\alpha_i^I}\), 对于 \(S_{3,4}\) 为 \(\frac{\alpha_i^{3D}+\alpha_i^{4D}}{\alpha_i^I}\)。同样,每个阶段的重要性得分也可以通过汇总该阶段内所有MP的得分来获得。通过重要性得分我们定义了包含三个选项的action space:1)对于最不重要的MP选择 \(I\) 2)去除第一个 \(MB^{3D}\) 3)减少最不重要stage的宽度。然后我们通过查找表计算每个action后的延迟,并评估每个action导致的精度下降。最后我们根据per-latency accuracy drop(\(\frac{-\%}{ms}\))来选择action。迭代执行这个过程直到达到目标延迟。
实验结果
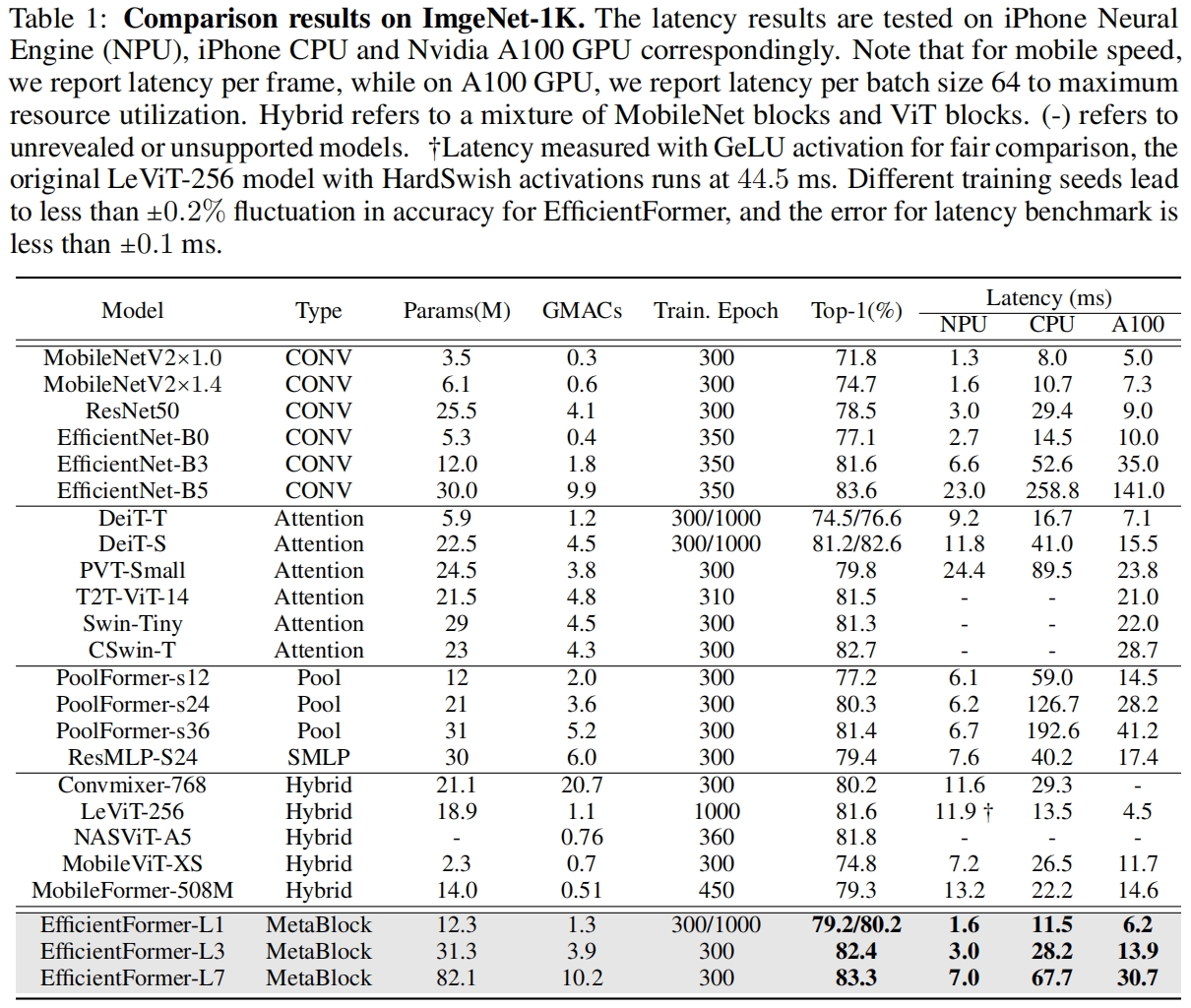
和其它小模型在ImageNet上的结果对比如表1所示,其中包括conv-based轻量模型如MobileNet、transformer-based轻量模型如MobileViT和MobileFormer、以及各种模型的tiny、small版本,可以看到EfficientFormer取到了最好的精度/速度平衡。例如EfficientFormer-L2相比于MobileViT-XS,精度提升了7.6%,延迟还降低了接近60%。
需要注意的是在NPU上EfficientFormer比MobileViT快了一倍还多,但在CPU和A100 GPU上要比MobieViT慢。
这里有个疑问,在MobileViTv2论文中也在iPhone12上评估了延迟,但没说是npu还是cpu,本文EfficientNet-B0在NPU上延迟是2.7ms,而MobileViTv2中的EfficientNet-B0在iphone12上的延迟为1.6ms,如果是npu两者结果不一致,如果是cpu的话cpu的计算速度比npu还快?
代码解析
这里以timm中的实现为例,输入大小为(1, 3, 224, 224),模型选择"efficientformer_l1"。首先patch embedding采用两个stride=2的3x3小卷积代替原来kernel_size=patch_size=stride的大核卷积,提升了patch embedding层在移动设备上的速度。
class Stem4(nn.Sequential):
def __init__(self, in_chs, out_chs, act_layer=nn.ReLU, norm_layer=nn.BatchNorm2d):
super().__init__()
self.stride = 4
self.add_module('conv1', nn.Conv2d(in_chs, out_chs // 2, kernel_size=3, stride=2, padding=1))
self.add_module('norm1', norm_layer(out_chs // 2))
self.add_module('act1', act_layer())
self.add_module('conv2', nn.Conv2d(out_chs // 2, out_chs, kernel_size=3, stride=2, padding=1))
self.add_module('norm2', norm_layer(out_chs))
self.add_module('act2', act_layer())EfficientFormerStage的代码如下,其中downsample对应图3中的三个Embedding,这里是通过一个stride=2的3x3卷积实现的降采样。Metablok2d对应的是图3中的 \(MB^{4D}\),Metablock1d对应的是 \(MB^{3D}\)。其中58行表示从 \(MB^{4D}\) 向 \(MB^{3D}\) 转换,需要将spatial维度展平合并到token num中。
class EfficientFormerStage(nn.Module):
def __init__(
self,
dim,
dim_out,
depth,
downsample=True,
num_vit=1,
pool_size=3,
mlp_ratio=4.,
act_layer=nn.GELU,
norm_layer=nn.BatchNorm2d,
norm_layer_cl=nn.LayerNorm,
proj_drop=.0,
drop_path=0.,
layer_scale_init_value=1e-5,
):
super().__init__()
self.grad_checkpointing = False
if downsample:
self.downsample = Downsample(in_chs=dim, out_chs=dim_out, norm_layer=norm_layer)
dim = dim_out
else:
assert dim == dim_out
self.downsample = nn.Identity()
blocks = []
if num_vit and num_vit >= depth:
blocks.append(Flat())
for block_idx in range(depth):
remain_idx = depth - block_idx - 1
if num_vit and num_vit > remain_idx:
blocks.append(
MetaBlock1d(
dim,
mlp_ratio=mlp_ratio,
act_layer=act_layer,
norm_layer=norm_layer_cl,
proj_drop=proj_drop,
drop_path=drop_path[block_idx],
layer_scale_init_value=layer_scale_init_value,
))
else:
blocks.append(
MetaBlock2d(
dim,
pool_size=pool_size,
mlp_ratio=mlp_ratio,
act_layer=act_layer,
norm_layer=norm_layer,
proj_drop=proj_drop,
drop_path=drop_path[block_idx],
layer_scale_init_value=layer_scale_init_value,
))
if num_vit and num_vit == remain_idx:
blocks.append(Flat())
self.blocks = nn.Sequential(*blocks)
def forward(self, x):
x = self.downsample(x)
if self.grad_checkpointing and not torch.jit.is_scripting():
x = checkpoint_seq(self.blocks, x)
else:
x = self.blocks(x)
return xMetaBlock2d的代码如下,就是一个poolformer,其中token mixer采用了池化操作。
class MetaBlock2d(nn.Module):
def __init__(
self,
dim,
pool_size=3,
mlp_ratio=4.,
act_layer=nn.GELU,
norm_layer=nn.BatchNorm2d,
proj_drop=0.,
drop_path=0.,
layer_scale_init_value=1e-5
):
super().__init__()
self.token_mixer = Pooling(pool_size=pool_size)
self.ls1 = LayerScale2d(dim, layer_scale_init_value)
self.drop_path1 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
# Conv+BN+GELU
self.mlp = ConvMlpWithNorm(
dim,
hidden_features=int(dim * mlp_ratio),
act_layer=act_layer,
norm_layer=norm_layer,
drop=proj_drop,
)
self.ls2 = LayerScale2d(dim, layer_scale_init_value)
self.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x): # (1,48,56,56)
# Pooling(
# (pool): AvgPool2d(kernel_size=3, stride=1, padding=1)
# )
x = x + self.drop_path1(self.ls1(self.token_mixer(x)))
# ConvMlpWithNorm(
# (fc1): Conv2d(48, 192, kernel_size=(1, 1), stride=(1, 1))
# (norm1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (act): GELU()
# (fc2): Conv2d(192, 48, kernel_size=(1, 1), stride=(1, 1))
# (norm2): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# (drop): Dropout(p=0.0, inplace=False)
# )
x = x + self.drop_path2(self.ls2(self.mlp(x)))
return xMetaBlock1d的代码如下,就是一个普通的self-attention。
class MetaBlock1d(nn.Module):
def __init__(
self,
dim,
mlp_ratio=4.,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm,
proj_drop=0.,
drop_path=0.,
layer_scale_init_value=1e-5
):
super().__init__()
self.norm1 = norm_layer(dim)
self.token_mixer = Attention(dim)
self.norm2 = norm_layer(dim)
self.mlp = Mlp(
in_features=dim,
hidden_features=int(dim * mlp_ratio),
act_layer=act_layer,
drop=proj_drop,
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.ls1 = LayerScale(dim, layer_scale_init_value)
self.ls2 = LayerScale(dim, layer_scale_init_value)
def forward(self, x): # (1,49,448)
# Attention(
# (qkv): Linear(in_features=448, out_features=1536, bias=True)
# (proj): Linear(in_features=1024, out_features=448, bias=True)
# )
x = x + self.drop_path(self.ls1(self.token_mixer(self.norm1(x))))
# Mlp(
# (fc1): Linear(in_features=448, out_features=1792, bias=True)
# (act): GELU()
# (drop1): Dropout(p=0.0, inplace=False)
# (norm): Identity()
# (fc2): Linear(in_features=1792, out_features=448, bias=True)
# (drop2): Dropout(p=0.0, inplace=False)
# )
x = x + self.drop_path(self.ls2(self.mlp(self.norm2(x))))
return x















 1204
1204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











