







 本文详细探讨了GPU显存、算力和带宽的基础知识,并着重分析了在深度学习中,batch size的变化如何影响显存占用。通过实例解析,揭示了模型参数、输入输出和优化器在不同batch size下的显存消耗,指出训练速度不仅受限于显存,还与GPU算力相关。
本文详细探讨了GPU显存、算力和带宽的基础知识,并着重分析了在深度学习中,batch size的变化如何影响显存占用。通过实例解析,揭示了模型参数、输入输出和优化器在不同batch size下的显存消耗,指出训练速度不仅受限于显存,还与GPU算力相关。
 最近在训练模型的时候突然被问到如下几个看似简单,实则一点也不难的问题
最近在训练模型的时候突然被问到如下几个看似简单,实则一点也不难的问题
- 在显存充足的情况下增加 batch size 大小会加快训练吗?
- 扩大 batch size 占用的显存是如何变化的,显存是线性增加吗?
- 扩大 batch size 后是哪些因素导致了显存占用增加?
前两个问题有过训练模型经验的都知道增加batch size并不会一直能加快训练,而扩大batch size也和显存占用不成线性关系。而对第三个问题被问到的一瞬间确实没有反应过来,因此便有了这篇文章。本文将对以上三个问题进行详细分析
1. GPU 基础
1.1 显存
此处不多说,就是GPU的内存,越大越好,下面展示一些GPU的显存大小
| GPU型号 | 显存大小 |
|---|---|
| 1060 | 6G |
| 1080 | 8G |
| T4 | 16G |
| V100 | 32G |
| A100 | 80G |
显存分析
在深度学习中常用的数值类型是float32,一个字节8位,float32数值类型占用4个字节。如果现在有一个1000x1000的矩阵,存储类型为float32,那么占用的显存差不多就是
1000 × 1000 × 4 = 4 × 1 0 6 B ≈ 4000 K B ≈ 4 M B 1000 \times 1000 \times 4 = 4 \times 10^6 B \approx 4000KB \approx 4MB 1000×1000×4=4×106B≈4000KB≈4MB
注意此处为了计算方便使用了1000进制,实际上为1024
前面介绍的 Stable Diffusion XL 的Unet参数量为2.6B(26亿),那么其占用显存计算如下(假设按 float32 存储):
26 × 1 0 8 × 4 = 104 × 1 0 8 B ≈ 10.4 G B 26\times 10^8 \times 4 = 104 \times 10^8 B \approx 10.4 GB 26×108×4=104×108B≈10.4GB
1.2 算力
GPU计算单元类似于CPU中的核,用来进行数值计算。衡量计算量的单位是flop: the number of floating-point multiplication-adds,即浮点数先乘后加算一个flop。
1*2+3 1 flop
1*2 + 3*4 + 4*5 3 flop
算力用于衡量GPU的计算能力,计算能力越强大,速度越快。衡量计算能力的单位是flops,即每秒能执行的flop数量。
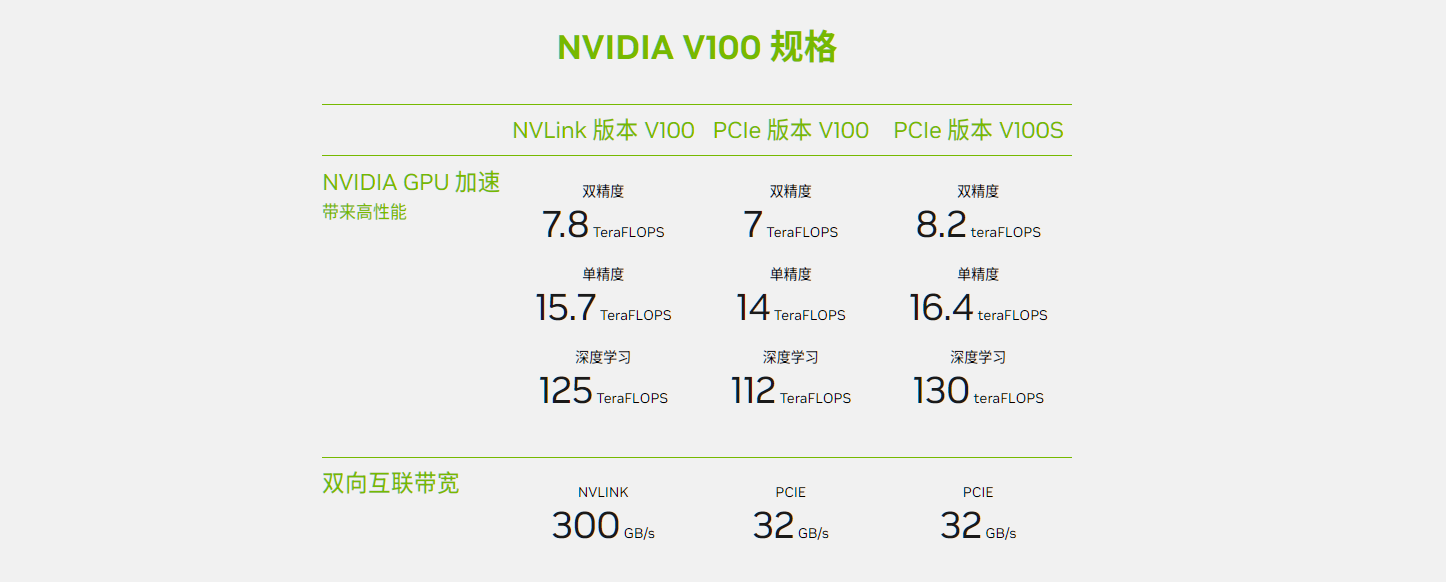
下图展示了V100的算力,其中TFLOPS是teraFLOPS的缩写,等于每秒一万亿( 1 0 12 10^{12} 1012) 次的浮点运算。常见的单位还有PFLOPS(petaFLOPS)等于每秒一千万亿( 1 0 15 10^{15} 1015)次的浮点运算
下图展示了大模型训练常用的GPU A100算例

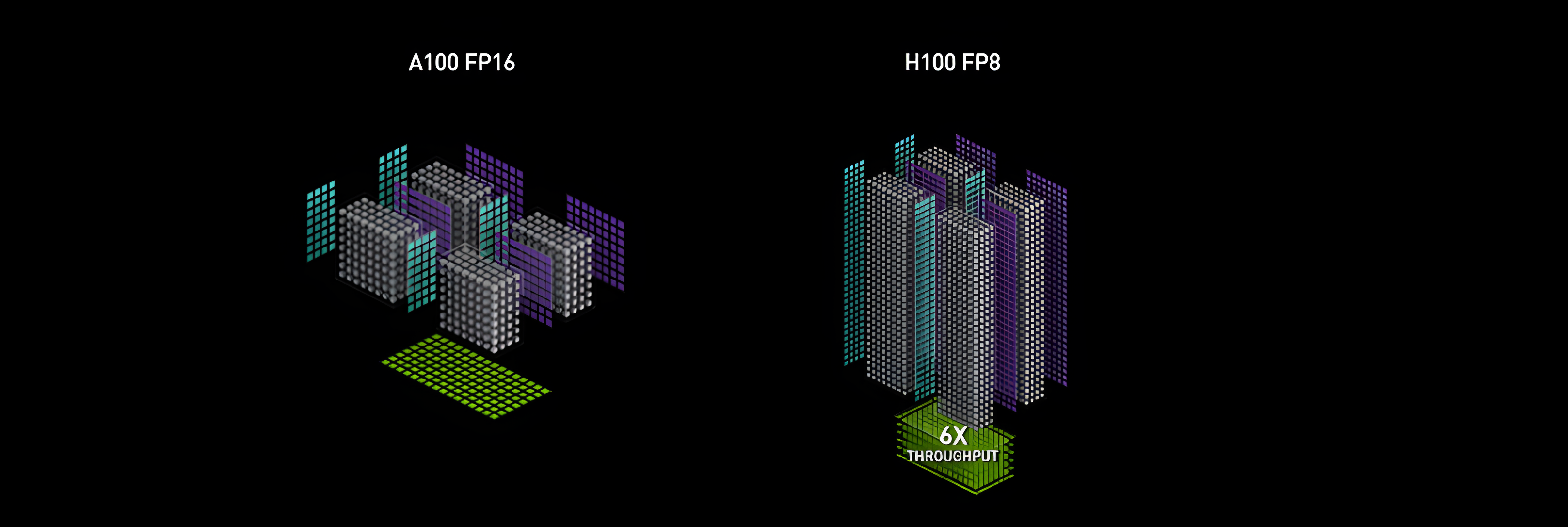
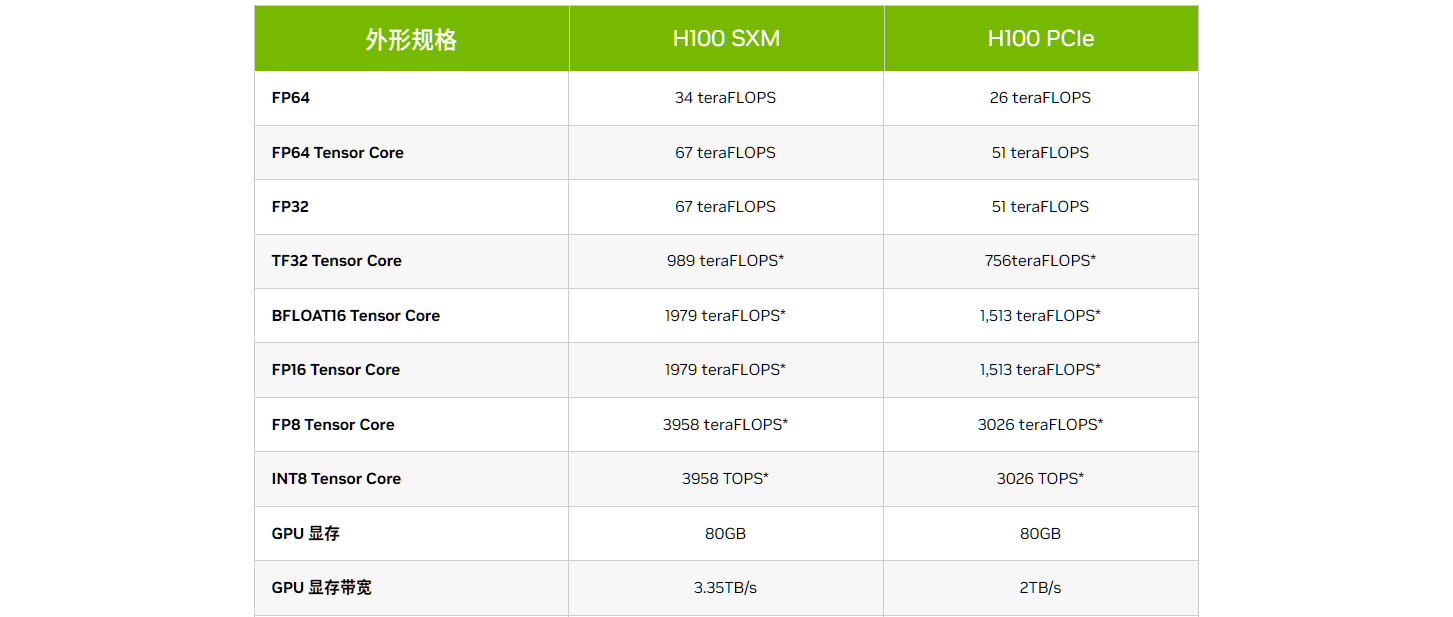
下图展示了最强GPU H100的算力,在双精度情况下基本是V100的5倍。
1.3 带宽
显存和算力是GPU最重要的两个指标,另外一个重要指标就是带宽了。 带宽主要用在分布式训练中通信,带宽小将限制训练速度。
2. 神经网络显存占用
下文将以如下式所示的全连接网络为例进行讲解,其中 X ∈ R n × m X \in R^{n\times m} X∈Rn
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4255
4255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









