







 T2I-Adapter是一种轻量级网络结构,用于提升文生图模型的可控能力,它作为独立插件与预训练模型结合,不改变原有模型。通过Adapter,可以利用额外的控制信息,如颜色、结构,进行更精细化的生成控制。该方法具有即插即用、简单、灵活和强泛化性的特点。在训练中,仅优化Adapter参数,保持预训练模型参数固定,通过非均匀采样策略提高控制效果。
T2I-Adapter是一种轻量级网络结构,用于提升文生图模型的可控能力,它作为独立插件与预训练模型结合,不改变原有模型。通过Adapter,可以利用额外的控制信息,如颜色、结构,进行更精细化的生成控制。该方法具有即插即用、简单、灵活和强泛化性的特点。在训练中,仅优化Adapter参数,保持预训练模型参数固定,通过非均匀采样策略提高控制效果。

- 论文:T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
- 代码:TencentARC/T2I-Adapter
- 系列文章:
在前面的文章中,我们介绍过了使用ControlNet来控制文生图模型生成图片,今天介绍将要介绍的T2I-Adapter在功能方面完全与ControlNet一样,但是网络结构完全不同,相比起来更加轻量化,并且个人认为 T2I-Adapter 的网络结构更具有代表性,未来在控制方面有更大的概率都会以 T2I-Adapter 的网络结构呈现,即直接将额外的控制信息直接和 text embedding 一起注入到 Unet 中
1. 动机及贡献
文生图模型近年来已经取得巨大进展,能够生成非常逼真的图片,但是完全使用文本来控制模型生成,并不能充分发挥出模型的性能,本文的目的就是想通过其他控制信息来挖掘文生图模型的能力,从而提升模型更加精细化控制的能力。对此,作者提出了一个简单且轻量化的 T2I-Adapter 来对齐模型内部知识和其他额外的控制信号,这样的话,开发者可以根据不同条件训练多个adapter来实现更加丰富的控制。
T2I-Adapter 作为独立于预训练的文生图模型外的控制网络,具有以下优点:
- 即插即用:它不会改变原始的文生图预训练模型(如SD1.5/ SDXL等)的结构和性能,它作为一种插件存在。
- 简单和轻量化:能够以很小的训练代价与已有的预训练文生图模型结合,整个插件模型只有 77M 的参数,大约只占300M的存储空间
- 灵活使用:可以根据不同的控制条件训练各种adapter,包括颜色、复杂结构的控制等,并且多个adapter可以组合使用,实现更复杂的控制
- 泛化性强:经过一次训练,它可被用在各种以相同base模型finetune后的模型上
2. Method
T2I-Adapter 的整体结构如下图所示,它由一个预训练的SD模型和一些adapters组成,这些adapter用于抽取不同控制条件的特征,预训练的SD模型的参数是固定的,它根据输入的文本特征和其他控制条件特征来生成图片。
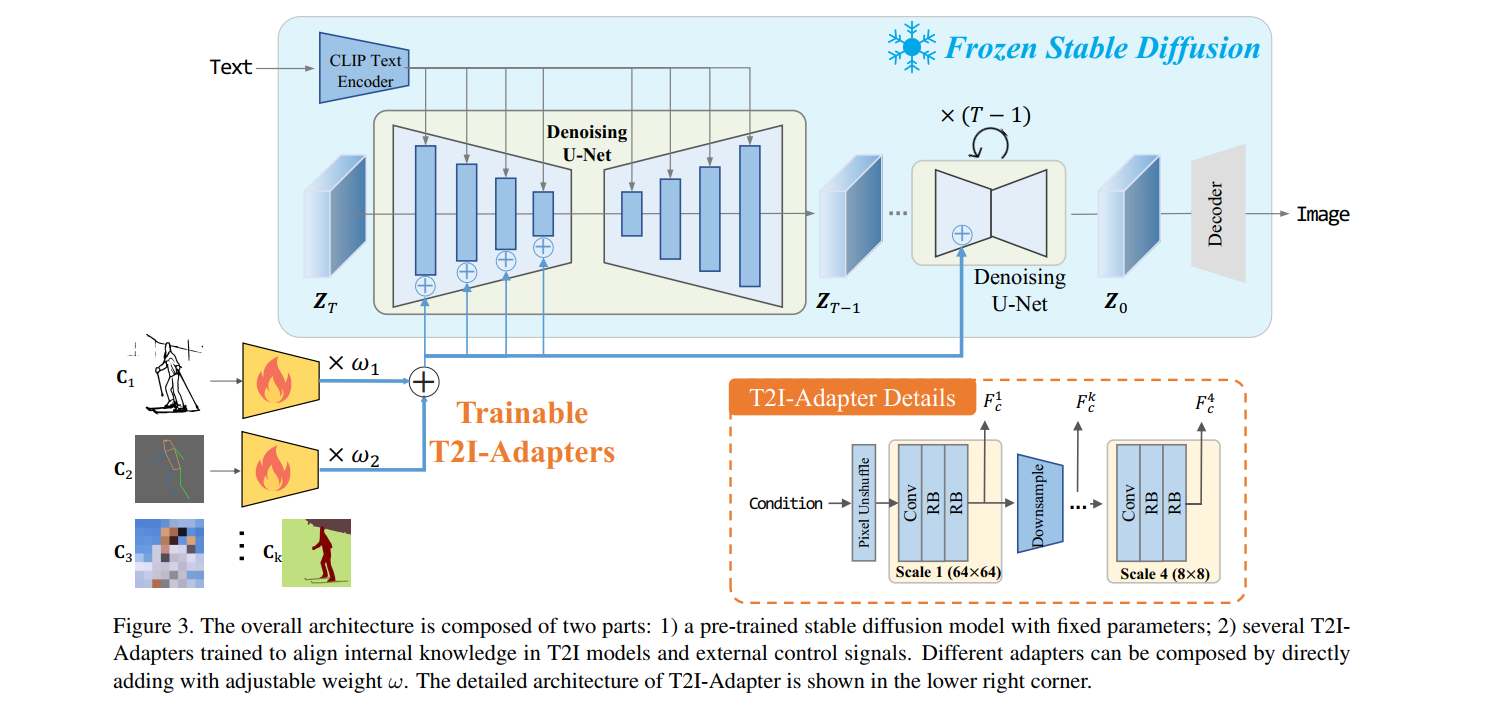
2.1 Adapter 设计
Adapter 设计成了一种轻量化结构,如上图右下角所示,它由4个特征抽取块和3个下采样块组成,控制条件的原始输入分辨率是 512 × 512 512 \times 512 512×512,这里使用了 pixel unshuffle 操作将输入下采样到 64 × 64 64 \times 64 64×64 分辨率。如上图右下角所示,每个scale中包含一个卷积层和两个残差块,来抽取输入条件的特征 F c k F_c^k Fck ,最终构成多个层面的特征 F c = { F c 1 , F c 2 , F c 3 , F c 4 } \mathbf{F}_c=\{\mathbf{F}_c^1,\mathbf{F}_c^2,\mathbf{F}_c^3,\mathbf{F}_c^4\} Fc={ Fc1,Fc2,Fc3,Fc4},注意这里的每个特征 F c \mathbf{F}_c Fc 和输入到Unet中的文本特征 F e n c = { F e n c
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









