









论文标题
VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
论文下载
VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION论文下载
论文作者
Karen Simonyan 和 Andrew Zisserman,隶属于牛津大学工程科学系的视觉几何组。
内容简介
这篇论文深入探讨了卷积神经网络(ConvNets)在大规模图像识别任务中的深度对识别准确性的影响。作者通过构建具有不同深度的网络架构,发现增加网络深度可以显著提高识别准确性。这些发现支持了他们在2014年ImageNet挑战赛中的参赛,取得了定位和分类任务的优异成绩。此外,作者还展示了这些深度网络在其他数据集上的泛化能力,并取得了领先的结果。为了推动深度视觉表示在计算机视觉领域的研究,他们公开了两个最佳的ConvNet模型。
方法详细说明
网络深度的影响:
- 作者通过逐步增加网络深度,使用非常小的(3×3)卷积滤波器,来评估网络深度对图像识别准确性的影响。
- 实验结果表明,将网络深度增加到16-19个权重层可以显著提高先前配置的准确性。
网络架构:
- 网络架构采用小尺寸(3×3)的卷积滤波器,这使得网络可以更深,同时保持较小的参数数量。
- 网络中还包括1×1的卷积滤波器,可以看作是输入通道的线性变换(后跟非线性激活)。
训练和测试:
- 训练时,输入图像被固定为224×224 RGB图像,通过减去训练集上计算的平均RGB值进行预处理。
- 网络通过多个卷积层和最大池化层,最后是三个全连接(FC)层,其中前两层有4096个通道,最后一层进行1000类ILSVRC分类。
激活函数:
所有隐藏层都使用了修正线性单元(ReLU)非线性激活函数。
正则化:
除了一个网络外,其他网络没有使用局部响应归一化(LRN),因为LRN并未在ILSVRC数据集上提高性能,但会增加内存消耗和计算时间。
权重初始化:
对于较浅的网络,使用随机初始化;对于更深的网络,使用预训练的较浅网络的权重进行初始化。
多尺度训练:
在训练过程中,通过随机缩放输入图像来增加训练集的多样性,这被称为尺度抖动。
测试策略:
- 在测试时,将训练好的网络应用于整个缩放后的测试图像,并使用空间平均池化来获得固定大小的类别分数向量。
- 测试时还采用了水平翻转图像的策略,以增强模型的鲁棒性。
结果
ILSVRC-2014挑战赛:
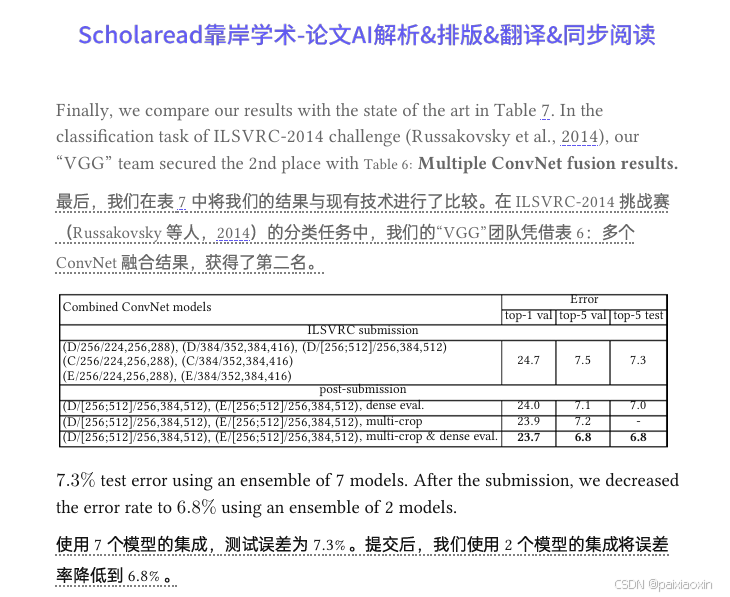
- 他们的团队在定位任务上获得了第一名,在分类任务上获得了第二名。
- 通过融合多个模型的输出,他们进一步降低了测试错误率。
泛化能力:
- 在PASCAL VOC和Caltech数据集上,这些深度网络也显示出良好的泛化能力,并取得了领先的结果。
- 这表明深度网络学习到的特征不仅适用于ILSVRC数据集,还可以迁移到其他图像识别任务中。
结论
这项工作证明了在大规模图像识别任务中,增加卷积网络的深度可以显著提高分类准确性。通过使用传统的ConvNet架构,但深度显著增加,可以达到ImageNet挑战数据集上的最新性能。此外,这些模型在广泛的任务和数据集上表现出良好的泛化能力,证实了深度在视觉表示中的重要性。这项研究不仅推动了深度学习在图像识别领域的应用,也为未来的研究提供了宝贵的资源和启示。
深度学习必读论文合集:
希望这些论文能帮到你!如果觉得有用,记得点赞关注哦~ 后续还会更新更多论文合集!!

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









