






我是在win10环境下。
python 3.12 版本 + pyspark 3.5.x 版本配合有问题
环境、问题现象
python版本:
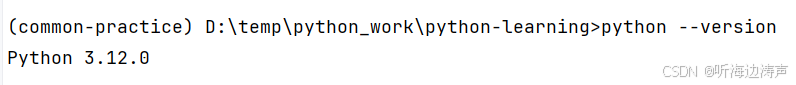
pyspark版本:
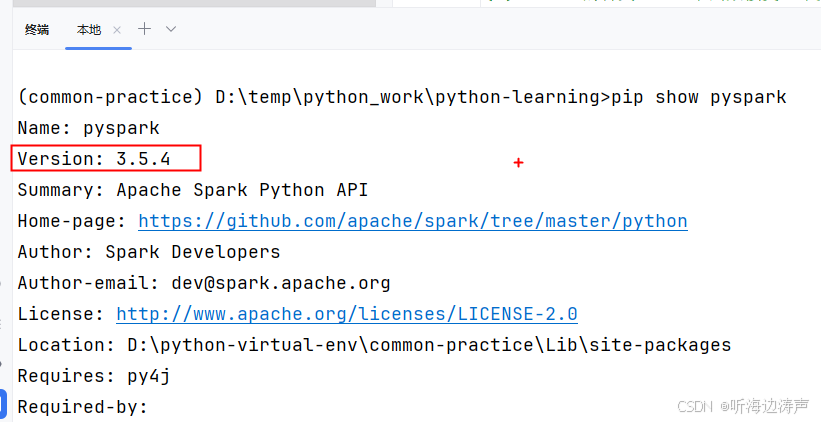
下面的代码执行RDD的map计算:
from pyspark import SparkConf, SparkContext
import os
# 明确设置python解释器的路径
os.environ['PYSPARK_PYTHON'] = 'D:/python-virtual-env/common-practice/Scripts/python.exe'
conf = SparkConf().setMaster('local[*]').setAppName('my_test_spark')
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize([1, 3, 5, 7, 9])
def func(data):
return data * 2
# 通过map方法将所有数据都乘以100
"""
(T) -> U 这是一种泛型表示法,用于描述函数的输入和输出类型。
(T) -> U 的含义是:这个函数接受一个类型为 T 的参数,并返回一个类型为 U 的结果。
(T) -> U 是一个函数类型,表示一个接受 T 类型参数并返回 U 类型结果的函数。
具体来说:
T 表示输入元素的类型,就是RDD中元素的类型。
U 表示输出元素的类型,U 可以与 T 相同,也可以不同。
"""
rdd2 = rdd.map(func)
print(rdd2.collect())
# print(sc.version)
sc.stop()
运行报异常:
D:\python-virtual-env\common-practice\Scripts\python.exe D:\temp\python_work\python-learning\test.py
25/02/20 07:56:32 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
25/02/20 07:56:32 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
25/02/20 07:56:35 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)
org.apache.spark.SparkException: Python worker exited unexpectedly (crashed)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$1.applyOrElse(PythonRunner.scala:612)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$1.applyOrElse(PythonRunner.scala:594)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:38)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:789)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:766)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:525)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at org.apache.spark.InterruptibleIterator.foreach(InterruptibleIterator.scala:28)
at scala.collection.generic.Growable.$plus$plus$eq(Growable.scala:62)
at scala.collection.generic.Growable.$plus$plus$eq$(Growable.scala:53)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:105)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:49)
at scala.collection.TraversableOnce.to(TraversableOnce.scala:366)
at scala.collection.TraversableOnce.to$(TraversableOnce.scala:364)
at org.apache.spark.InterruptibleIterator.to(InterruptibleIterator.scala:28)
at scala.collection.TraversableOnce.toBuffer(TraversableOnce.scala:358)
at scala.collection.TraversableOnce.toBuffer$(TraversableOnce.scala:358)
at org.apache.spark.InterruptibleIterator.toBuffer(InterruptibleIterator.scala:28)
at scala.collection.TraversableOnce.toArray(TraversableOnce.scala:345)
at scala.collection.TraversableOnce.toArray$(TraversableOnce.scala:339)
at org.apache.spark.InterruptibleIterator.toArray(InterruptibleIterator.scala:28)
at org.apache.spark.rdd.RDD.$anonfun$collect$2(RDD.scala:1049)
at org.apache.spark.SparkContext.$anonfun$runJob$5(SparkContext.scala:2433)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:93)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:166)
at org.apache.spark.scheduler.Task.run(Task.scala:141)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$4(Executor.scala:620)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally(SparkErrorUtils.scala:64)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally$(SparkErrorUtils.scala:61)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:94)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:623)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642)
at java.base/java.lang.Thread.run(Thread.java:1623)
Caused by: java.io.EOFException
at java.base/java.io.DataInputStream.readInt(DataInputStream.java:386)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:774)
... 32 more
25/02/20 07:56:35 WARN TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0) (DESKTOP-532H2ON executor driver): org.apache.spark.SparkException: Python worker exited unexpectedly (crashed)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$1.applyOrElse(PythonRunner.scala:612)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$1.applyOrElse(PythonRunner.scala:594)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:38)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:789)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:766)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:525)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at org.apache.spark.InterruptibleIterator.foreach(InterruptibleIterator.scala:28)
at scala.collection.generic.Growable.$plus$plus$eq(Growable.scala:62)
at scala.collection.generic.Growable.$plus$plus$eq$(Growable.scala:53)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:105)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:49)
at scala.collection.TraversableOnce.to(TraversableOnce.scala:366)
at scala.collection.TraversableOnce.to$(TraversableOnce.scala:364)
at org.apache.spark.InterruptibleIterator.to(InterruptibleIterator.scala:28)
at scala.collection.TraversableOnce.toBuffer(TraversableOnce.scala:358)
at scala.collection.TraversableOnce.toBuffer$(TraversableOnce.scala:358)
at org.apache.spark.InterruptibleIterator.toBuffer(InterruptibleIterator.scala:28)
at scala.collection.TraversableOnce.toArray(TraversableOnce.scala:345)
at scala.collection.TraversableOnce.toArray$(TraversableOnce.scala:339)
at org.apache.spark.InterruptibleIterator.toArray(InterruptibleIterator.scala:28)
at org.apache.spark.rdd.RDD.$anonfun$collect$2(RDD.scala:1049)
at org.apache.spark.SparkContext.$anonfun$runJob$5(SparkContext.scala:2433)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:93)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:166)
at org.apache.spark.scheduler.Task.run(Task.scala:141)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$4(Executor.scala:620)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally(SparkErrorUtils.scala:64)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally$(SparkErrorUtils.scala:61)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:94)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:623)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642)
at java.base/java.lang.Thread.run(Thread.java:1623)
Caused by: java.io.EOFException
at java.base/java.io.DataInputStream.readInt(DataInputStream.java:386)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:774)
... 32 more
25/02/20 07:56:35 ERROR TaskSetManager: Task 0 in stage 0.0 failed 1 times; aborting job
Traceback (most recent call last):
File "D:\temp\python_work\python-learning\test.py", line 27, in <module>
print(rdd2.collect())
^^^^^^^^^^^^^^
File "D:\python-virtual-env\common-practice\Lib\site-packages\pyspark\rdd.py", line 1833, in collect
sock_info = self.ctx._jvm.PythonRDD.collectAndServe(self._jrdd.rdd())
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\python-virtual-env\common-practice\Lib\site-packages\py4j\java_gateway.py", line 1322, in __call__
return_value = get_return_value(
^^^^^^^^^^^^^^^^^
File "D:\python-virtual-env\common-practice\Lib\site-packages\py4j\protocol.py", line 326, in get_return_value
raise Py4JJavaError(
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 1 times, most recent failure: Lost task 0.0 in stage 0.0 (TID 0) (DESKTOP-532H2ON executor driver): org.apache.spark.SparkException: Python worker exited unexpectedly (crashed)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$1.applyOrElse(PythonRunner.scala:612)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$1.applyOrElse(PythonRunner.scala:594)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:38)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:789)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:766)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:525)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at org.apache.spark.InterruptibleIterator.foreach(InterruptibleIterator.scala:28)
at scala.collection.generic.Growable.$plus$plus$eq(Growable.scala:62)
at scala.collection.generic.Growable.$plus$plus$eq$(Growable.scala:53)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:105)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:49)
at scala.collection.TraversableOnce.to(TraversableOnce.scala:366)
at scala.collection.TraversableOnce.to$(TraversableOnce.scala:364)
at org.apache.spark.InterruptibleIterator.to(InterruptibleIterator.scala:28)
at scala.collection.TraversableOnce.toBuffer(TraversableOnce.scala:358)
at scala.collection.TraversableOnce.toBuffer$(TraversableOnce.scala:358)
at org.apache.spark.InterruptibleIterator.toBuffer(InterruptibleIterator.scala:28)
at scala.collection.TraversableOnce.toArray(TraversableOnce.scala:345)
at scala.collection.TraversableOnce.toArray$(TraversableOnce.scala:339)
at org.apache.spark.InterruptibleIterator.toArray(InterruptibleIterator.scala:28)
at org.apache.spark.rdd.RDD.$anonfun$collect$2(RDD.scala:1049)
at org.apache.spark.SparkContext.$anonfun$runJob$5(SparkContext.scala:2433)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:93)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:166)
at org.apache.spark.scheduler.Task.run(Task.scala:141)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$4(Executor.scala:620)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally(SparkErrorUtils.scala:64)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally$(SparkErrorUtils.scala:61)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:94)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:623)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642)
at java.base/java.lang.Thread.run(Thread.java:1623)
Caused by: java.io.EOFException
at java.base/java.io.DataInputStream.readInt(DataInputStream.java:386)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:774)
... 32 more
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2856)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2792)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2791)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2791)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1247)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1247)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1247)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:3060)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2994)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2983)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:989)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2393)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2414)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2433)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2458)
at org.apache.spark.rdd.RDD.$anonfun$collect$1(RDD.scala:1049)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:410)
at org.apache.spark.rdd.RDD.collect(RDD.scala:1048)
at org.apache.spark.api.python.PythonRDD$.collectAndServe(PythonRDD.scala:195)
at org.apache.spark.api.python.PythonRDD.collectAndServe(PythonRDD.scala)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:75)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:52)
at java.base/java.lang.reflect.Method.invoke(Method.java:578)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:374)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.base/java.lang.Thread.run(Thread.java:1623)
Caused by: org.apache.spark.SparkException: Python worker exited unexpectedly (crashed)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$1.applyOrElse(PythonRunner.scala:612)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator$$anonfun$1.applyOrElse(PythonRunner.scala:594)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:38)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:789)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:766)
at org.apache.spark.api.python.BasePythonRunner$ReaderIterator.hasNext(PythonRunner.scala:525)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at org.apache.spark.InterruptibleIterator.foreach(InterruptibleIterator.scala:28)
at scala.collection.generic.Growable.$plus$plus$eq(Growable.scala:62)
at scala.collection.generic.Growable.$plus$plus$eq$(Growable.scala:53)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:105)
at scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:49)
at scala.collection.TraversableOnce.to(TraversableOnce.scala:366)
at scala.collection.TraversableOnce.to$(TraversableOnce.scala:364)
at org.apache.spark.InterruptibleIterator.to(InterruptibleIterator.scala:28)
at scala.collection.TraversableOnce.toBuffer(TraversableOnce.scala:358)
at scala.collection.TraversableOnce.toBuffer$(TraversableOnce.scala:358)
at org.apache.spark.InterruptibleIterator.toBuffer(InterruptibleIterator.scala:28)
at scala.collection.TraversableOnce.toArray(TraversableOnce.scala:345)
at scala.collection.TraversableOnce.toArray$(TraversableOnce.scala:339)
at org.apache.spark.InterruptibleIterator.toArray(InterruptibleIterator.scala:28)
at org.apache.spark.rdd.RDD.$anonfun$collect$2(RDD.scala:1049)
at org.apache.spark.SparkContext.$anonfun$runJob$5(SparkContext.scala:2433)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:93)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:166)
at org.apache.spark.scheduler.Task.run(Task.scala:141)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$4(Executor.scala:620)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally(SparkErrorUtils.scala:64)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally$(SparkErrorUtils.scala:61)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:94)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:623)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1144)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:642)
... 1 more
Caused by: java.io.EOFException
at java.base/java.io.DataInputStream.readInt(DataInputStream.java:386)
at org.apache.spark.api.python.PythonRunner$$anon$3.read(PythonRunner.scala:774)
... 32 more
进程已结束,退出代码为 1
尝试其它pyspark版本
我又尝试了pyspark的3.5.1、3.5.2、3.5.3版本,还是报异常。
python 3.10 版本 + pyspark 3.5.x 版本配合可以
python版本:

pyspark版本:
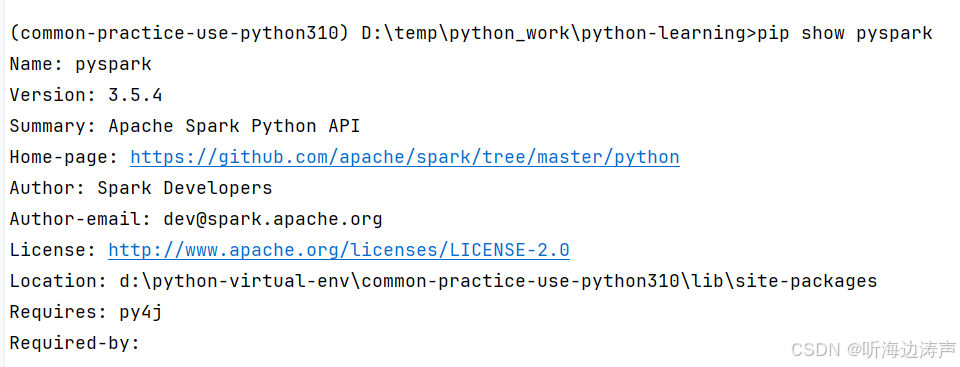
python代码:
from pyspark import SparkConf, SparkContext
import os
# 明确设置python解释器的路径
os.environ['PYSPARK_PYTHON'] = 'D:/python-virtual-env/common-practice-use-python310/Scripts/python.exe'
conf = SparkConf().setMaster('local[*]').setAppName('my_test_spark')
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize([1, 3, 5, 7, 9])
def func(data):
return data * 2
# 通过map方法将所有数据都乘以100
"""
(T) -> U 这是一种泛型表示法,用于描述函数的输入和输出类型。
(T) -> U 的含义是:这个函数接受一个类型为 T 的参数,并返回一个类型为 U 的结果。
(T) -> U 是一个函数类型,表示一个接受 T 类型参数并返回 U 类型结果的函数。
具体来说:
T 表示输入元素的类型,就是RDD中元素的类型。
U 表示输出元素的类型,U 可以与 T 相同,也可以不同。
"""
rdd2 = rdd.map(func)
print(rdd2.collect())
# print(sc.version)
sc.stop()
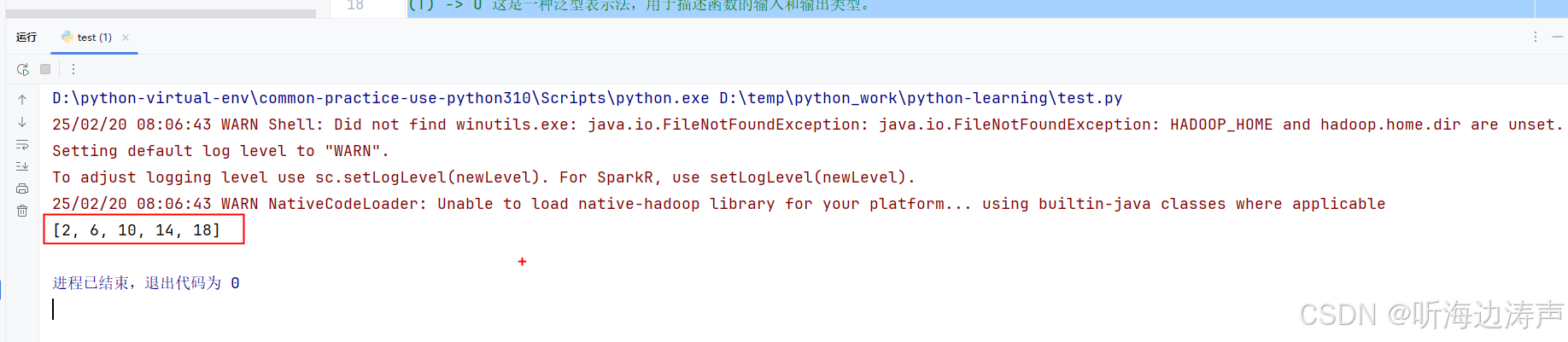
运行输出,可以正常得到结果:
D:\python-virtual-env\common-practice-use-python310\Scripts\python.exe D:\temp\python_work\python-learning\test.py
25/02/20 08:06:43 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
25/02/20 08:06:43 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[2, 6, 10, 14, 18]

















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









