







文章目录
CV — 目标检测:数据增强
一、相关概念
(一) 数据增强
-
数据增强:
- 数据增强(DataAugment)是深度学习中常用的技巧之一,数据增强是目标检测乃至整个深度学习中常用到的提高模型性能的方法,主要用于增加训练数据集,让数据集尽可能的多样化,使得训练的模型具有更强的泛化能力。
- 一方面,数据增强可以增加大量的训练数据量,提高模型的泛化能力;同时,对原始数据的增强也可以看作是引入了噪声,从而可以提升模型的鲁棒性。
-
数据增强分类:
数据增强可以分为两类: 离线增强 和 在线增强。-
离线增强 : 直接对数据集进行处理,数据的数目会变成 增强因子乘以原数据集的数目,这种方法常常用于数据集很小的时候。
-
在线增强 : 这种增强的方法用于,获得 batch 数据之后,然后对这个 batch 的数据进行增强,如 旋转、平移、缩放、裁剪、翻转、 等相应的变化,由于有些数据集不能接受线性级别的增长,这种方法长用于 大的数据集,很多机器学习框架已经支持了这种数据增强方式,并且可以使用 GPU 优化计算。
在线数据增强是指在训练过程中对图像进行各种变换增加图像样本的多样性,你可以通过 增加迭代次数来保证训练的图像数量增加,因为你每次迭代喂进网络的图像都是你增强后的图像,如果增强方法足够丰富,那么每次丢给网络的图像都是不一样的,即间接增加了训练的数据量。
-
-
数据增强主要包括:
- 仿射变换:平移、翻转(flip)、缩放(Scale)、旋转(Rotation)、裁剪(Shear)
- 透视变换:
- 色调变换:对比度、色彩抖动、噪声等
(二) 目标检测数据增强
不同的图像任务中,数据增强的方式也有所不同。相比于图像分类,目标检测中的数据增强需要同时考虑图像和边界框的变换。
在目标检测中,数据增强又分为两个大类:针对图像中的像素,针对整幅图像。
1. 针对像素
- 解释:
主要是改变原图像中像素的值,而不改变图像目标的形状和图像的大小。
经过处理后,图像的饱和度、亮度、明度、颜色通道、颜色空间等会发生发生变化。这类变换不会改变原图中的标注信息,即边界框和类别。 - 方式:
- 随机改变图像亮度:RandomBrightness
- 随机改变对比度、色度、饱和度:PhotometricDistort
- 对比度:RandomContrast
- 色度:RandomHue
- 饱和度:RandomSaturation
- 随机改变颜色通道:RandomLightingNoise
2. 针对图像
- 解释:
针对图像的像素增强不仅需要改变图像本身,还需要考虑标注信息的改变,这里主要指标注的边界框的改变。 - 方式:
- 随机缩放:Expand
- 随机裁剪:RandomSampleCrop
- 随机翻转:RandomMirror
二、数据增强方式
数据增强手段主要有:仿射变换、透视变换、色调变换等等
(一) 仿射变换
-
前言:
在深度学习的数据增强中,我们经常需要对图像进行各种增强操作如:平移、翻转(flip)、缩放(Scale)、旋转(Rotation)、裁剪(Shear) 等,这些其实都是 图像的仿射变换。
待确认:对比度,色彩抖动,噪声 -
仿射变换原理:
-
维基百科定义:
仿射变换(Affine transformation),又称 仿射映射,是指在 几何 中,对一个 向量空间 进行一次 线性变换 并接上一个 平移,变换为另一个向量空间。简单来说,“仿射变换” 就是:“线性变换” + “平移”。
-
示例:
假设有一个向量空间 k:k = (x, y),还有一个向量空间 j:j = (x’, y’),可以通过仿射变换来将 j 变换成 k。
步骤如下:
- 令:j = w * k + b,
分解式:x’ = w00 * x + w01 * y + b0,y’ = w10 * x + w11 * y + b1 - 转换为矩阵的乘法:
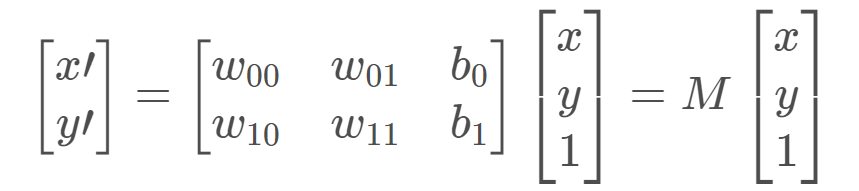
通过 参数矩阵M 就可以实现两个向量空间之间的转换。
- 令:j = w * k + b,
-
总结:在进行仿射变换的时候我们也只需要一个矩阵M就可以实现平移、缩放、旋转和翻转等变换。
-
(三) 色调变换
-
实现手段:
通过在 hsv 色彩空间中,对 h、s、v三个通道增加扰动,来进行色调增强变换 -
代码实现:
def augment_hsv(image, hgain=0.5, sgain=0.5, vgain=0.5): """ HSV color-space augmentation :param image: 待增强的图片 :param hgain: HSV 中的 h 扰动系数,yolov5:0.015 :param sgain: HSV 中的 s 扰动系数,yolov5:0.7 :param vgain: HSV 中的 v 扰动系数,yolov5:0.4 :return: """ if hgain or sgain or vgain: # 随机取-1到1三个实数,乘以 hsv 三通道扰动系数 # r:[1-gain,1+gain] r = np.random.uniform(-1, 1, 3) * [hgain, sgain, vgain] + 1 # random gains image_hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV) # cv2.split:通道拆分 # h:[0~180], s:[0~255], v:[0~255] hue, sat, val = cv2.split(image_hsv) dtype = image.dtype # uint8 x = np.arange(0, 256, dtype=r.dtype) lut_hue = ((x * r[0]) % 180).astype(dtype) lut_sat = np.clip(x * r[1], 0, 255).astype(dtype) lut_val = np.clip(x * r[2], 0, 255).astype(dtype) # cv2.LUT:dst(I) = lut(src(I) + d),d为常数0 / 128 hue = cv2.LUT(hue, lut_hue) sat = cv2.LUT(sat, lut_sat) val = cv2.LUT(val, lut_val) # 通道合并 image_hsv = cv2.merge((hue, sat, val)).astype(dtype) # 将hsv格式转为BGR格式 image_dst = cv2.cvtColor(image_hsv, cv2.COLOR_HSV2BGR) return image_dst else: return image
三、常见数据增强方式
1)随机旋转
随机旋转一般情况下是对输入图像随机旋转[0,360)
2)随机裁剪
随机裁剪是对输入图像随机切割掉一部分
3)色彩抖动
色彩抖动指的是在颜色空间如RGB中,每个通道随机抖动一定的程度。在实际的使用中,该方法不常用,在很多场景下反而会使实验结果变差
4)高斯噪声
是指在图像中随机加入少量的噪声。该方法对防止过拟合比较有效,这会让神经网络不能拟合输入图像的所有特征
5)水平翻转
6)竖直翻转
随机裁剪/随机旋转/水平反转/竖直反转都是为了增加图像的多样性。并且在某些算法中,如faster RCNN中,自带了图像的翻转。
三、经典算法
(一) yolov5
-
参考资料:https://zhuanlan.zhihu.com/p/313650981
-
https://blog.csdn.net/LK007CX/article/details/106940453
-
https://blog.csdn.net/Q1u1NG/article/details/107362572
1. 数据增强步骤
-
数据读取:
- 方式: 一种为 load_mosaic,另外一种:load_image
- load_mosaic:
- mosaic 简单的说就是把四张训练图片缩放拼成一张图
- load_image:
- letterbox:缩放时保持图片的长宽比例,空白部分使用灰色填充
- load_mosaic:
- 方式: 一种为 load_mosaic,另外一种:load_image
-
数据增强:
-
包括 mosaic、augment_hsv、flip(up-down、left-right)
-
random_perspective:
包括:仿射变换、透视变换- 仿射变换:
包括:旋转、平移(√)、缩放(√大小缩放)、裁剪shear(√)
仿射变换矩阵可以由 旋转矩阵、平移矩阵 等组合得到,仿射变换矩阵可以用如下矩阵表示:
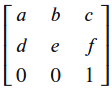
- 仿射变换:
-
色域变换(augment_hsv):
随机改变图片的色调(H),饱和度(S),亮度(V) -
翻转(flip:左右、上下):
-
方式1,numpy:
img = np.fliplr(image) # 水平翻转 img = np.flipud(img) # 上下翻转 -
方式2,opencv:
imgH = cv2.flip(image, 1) # 水平翻转 imgV = cv2.flip(image, 0) # 上下翻转 imgHV = cv2.flip(image, -1) # 既水平又上下
-
-
-
缺少:
- 裁剪:crop
-
1. mosaic
-
简介:
Mosaic 简单的说就是把四张训练图片缩放拼成一张图,Mosaic有利于提升小目标的检测,这是因为一般在数据集中小目标在图片中分布不均匀,这导致在常规的训练中小目标的学习总是不太充分。使用mosaic数据增强后,在遍历每个张图片包含了四张图片具有小目标的可能性就很大了,同时,每张图都有不同程度的缩小,即使没有小目标,通过缩小,原来的目标尺寸也更接近小目标的大小,这对模型学习小目标很有利。
-
代码分析:
dataset.py -> load_mosaic函数
-
效果图:

2. Cutout
-
简介:
Cutout 就是随机选择一个固定大小的正方形区域,然后采用全0填充就OK了,当然为了避免填充0值对训练的影响,应该要对数据进行中心归一化操作,norm到0。
-
代码分析:
-
效果图:

4. 矩形训练
-
简介:
通常yolo算法解决输入图像大小比例不同的方法是直接缩放和填充到固定的大小(letterbox方式),但是这样将导致有很多冗余的信息,会让网络产生很多无意义的候选框。
如图a:矩形训练就是为了减少这些冗余的信息,其实输入的图片不一定需要是正方形,也可以是矩形,只要边长能够整除步长 stride(默认为32) 就行。矩形训练就是将图像resize到变成可以被步长整除并且最接近需要输入的大小,从而实现最小填充,其效果如图b。
(值得一提的是,除了矩形训练,还有矩形推理,也就是在做检测的时候也这样填充,从而加快推理速度,减少推理时间。)
-
代码分析:
Rectangular Training
-
效果图:
(二) ssd
- 参考资料:https://blog.csdn.net/weixin_43593330/article/details/108174095
1. 数据增强步骤
-
数据类型和坐标转换:
-
图片矩阵转化为 浮点型:ConvertFromInts
-
归一化坐标转为绝对化坐标:ToAbsoluteCoords
为下面的几何变换做准备
-
-
像素内容变换(Photometric Distortions):
- 随机改变图像亮度:RandomBrightness
- 随机改变对比度、色度、饱和度:PhotometricDistort
- 对比度:RandomContrast
- 色度:RandomHue
- 饱和度:RandomSaturation
- 随机改变颜色通道:RandomLightingNoise
-
空间几何变换(Geometric Distortions):
- 随机缩放:Expand
- 随机裁剪:RandomSampleCrop
- 随机翻转:RandomMirror
-
坐标转换、缩放及减均值:
- 绝对化坐标转为归一化坐标:ToPercentCoords
- 缩放:Resize(300*300),因为几何变换后图像尺寸改变了
- 减均值:SubtractMeans(104, 117, 123)
-
SSDAugmentation
self.augment = Compose([ ConvertFromInts(), # 图片矩阵转化为 浮点型 ToAbsoluteCoords(), # 归一化坐标转为绝对化坐标 PhotometricDistort(), # 光度扭曲:对比度,hsv Expand(self.mean), # 扩充 RandomSampleCrop(), # 随机样本裁剪 RandomMirror(), # 随机翻转 ToPercentCoords(), # 绝对化坐标转为归一化坐标 Resize(self.size), # resize 到输入尺寸 SubtractMeans(self.mean) # 图片矩阵 减去均值 ])
2. 总结
本文介绍了两类在目标检测中常使用的数据增强的方法,包括 基于像素值 的增强方法和 基于整幅图像 的增强方法。
其中,在基于像素值的增强方法中,要注意对 颜色通道 的转换;在基于整幅图像的增强方法中,要注意对标注 边界框 施以同样的变化。
(三) opencv
- 参考资料:https://blog.csdn.net/mao_hui_fei/article/details/90542891
四、总结
(一) 步骤
-
仿射变换:
-
色调变换:(√)
hsv -
翻转:(√)
-
左右、上下
np.fliplr(img) np.flipud(img)
-
(二) 辅助函数
1. 随机函数
-
random.random():
生成【0,1】之间的实数
-
用法:
if random.random() < hyp['flipud']: img = np.flipud(img)
-
-
np.random.uniform(low=0.0, high=1.0, size=None):
生成【low,high】之间的实数
-
random.uniform(x, y):
随机生成一个实数,它在
[x,y]范围内。
参考文献
- 知乎
- Bubbliiiing:https://blog.csdn.net/weixin_44791964/article/details/105768775















 6574
6574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









