









http://blog.csdn.net/pipisorry/article/details/23538535
监督学习及其目标函数
损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示。
损失函数是经验风险函数的核心部分,也是结构风险函数重要组成部分。
模型的结构风险函数包括了经验风险项和正则项,通常可以表示成如下式子(一般来说,监督学习可以看做最小化下面的目标函数):
式子左边表示经验风险函数,损失函数是其核心部分;式子右边是正则项。式子整体是结构风险函数,其由经验风险函数和正则项组成。
其中,第一项L(yi,f(xi;w)) 衡量我们的模型(分类或者回归)对第i个样本的预测值f(xi;w)和真实的标签yi之前的误差。因为我们的模型是要拟合我们的训练样本的,所以我们要求这一项最小。即前面的均值函数表示的是经验风险函数,L代表的是损失函数;
但正如上面说言,我们不仅要保证训练误差最小,我们更希望我们的模型测试误差小,所以我们需要加上第二项,也就是对参数w的规则化函数Ω(w)去约束我们的模型尽量的简单。即后面的Φ是正则化项(regularizer)或者叫惩罚项(penalty term),它可以是L1,也可以是L2,或者其他的正则函数。规则项参考[最优化方法:范数和规则化regularization]。
整个式子表示的意思是找到使目标函数最小时的θ值。机器学习的大部分带参模型都和这个不但形似,而且神似,其实大部分无非就是变换这两项而已。
损失函数/loss函数
不同的loss函数,具有不同的拟合特性。对于第一项Loss函数,如果是Square loss,那就是最小二乘;如果是Hinge Loss,那就是著名的SVM;如果是exp-Loss,那就是 Boosting;如果是log-Loss,那就是Logistic Regression;等等。
loss函数一般都是通过mle推导出来的。使用最大似然来导出代价函数的方法的一个优势是,它减轻了为每个模型设计代价函数的负担。明确一个模型p(y | x)则自动地确定了一个代价函数log p(y | x)。[深度学习]
Note: lz: Loss functions一般指一个样本的;而cost functions指N个样本的。但是有时是混用的。
回归问题的损失函数
回归模型中的三种损失函数包括:均方误差(Mean Square Error)、平均绝对误差(Mean Absolute Error,MAE)、Huber Loss。
平方损失函数(最小二乘法, Ordinary Least Squares )
最小二乘法是线性回归的一种,OLS将问题转化成了一个凸优化问题。在线性回归中,它假设样本和噪声都服从高斯分布(根据中心极限定理),最后通过极大似然估计MLE可以推导出最小二乘式子,即平方损失函数可以通过线性回归在假设样本是高斯分布的条件下推导得到。
最小二乘的基本原则是:最优拟合直线应该是使各点到回归直线的距离和最小的直线,即平方和最小。换言之,OLS是基于距离的,而这个距离就是我们用的最多的欧几里得距离。选择使用欧式距离作为误差度量呢(即Mean squared error, MSE),主要是因为:简单,计算方便;欧氏距离是一种很好的相似性度量标准;在不同的表示域变换后特征性质不变。
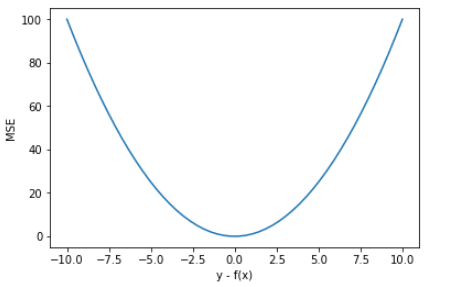
MSE的优缺点
优点:MSE 曲线的特点是光滑连续、可导,便于使用梯度下降算法,是比较常用的一种损失函数。而且,MSE 随着误差的减小,梯度也在减小,这有利于函数的收敛,即使固定学习因子,函数也能较快取得最小值。
缺点:如果样本中存在离群点,MSE 会给离群点赋予更高的权重,但是却是以牺牲其他正常数据点的预测效果为代价,这最终会降低模型的整体性能。即使用 MSE 损失函数,受离群点的影响较大。
平方损失(Square loss)的标准形式
当样本个数为n时,此时的损失函数变为:
Y-f(X)表示的是残差,而我们的目的就是最小化目标函数值,也就是最小化残差的平方和(residual sum of squares,RSS)。
而在实际应用中,通常会使用均方差(MSE)作为一项衡量指标,即MSE=1/n*L。
上面提到了线性回归,这里额外补充一句,我们通常说的线性有两种情况,一种是因变量y是自变量x的线性函数,一种是因变量y是参数α的线性函数。在机器学习中,通常指的都是后一种情况。
最小二乘法解线性回归
解上面的纯属回归也有解析方法,直接通过数学求解参数值。
首先构建Design matrix



Note: 用这种方法时不需要feature scaling。
[Linear Regression with Multiple Variables多变量线性规划 (Week 2) ]
最小二乘解

[矩阵分析与应用-张]
绝对值损失函数:平均绝对误差(Mean Absolute Error,MAE)
平均绝对误差指的就是模型预测值 f(x) 与样本真实值 y 之间距离的平均值。其公式如下所示:
![]()
损失函数的图形:
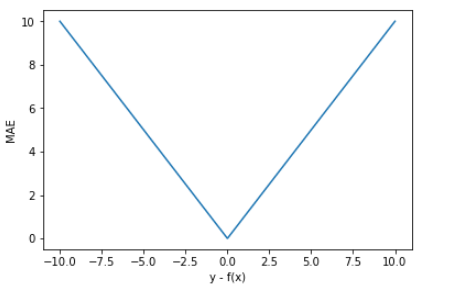
MAE优缺点
MAE 的曲线呈 V 字型,连续但在 y-f(x)=0 处不可导,计算机求解导数比较困难。而且 MAE 大部分情况下梯度都是相等的,这意味着即使对于小的损失值,其梯度也是大的。这不利于函数的收敛和模型的学习。
优点就是 MAE 对离群点不那么敏感,更有包容性。因为 MAE 计算的是误差 y-f(x) 的绝对值,无论是 y-f(x)>1 还是 y-f(x)<1,没有平方项的作用,惩罚力度都是一样的,所占权重一样。
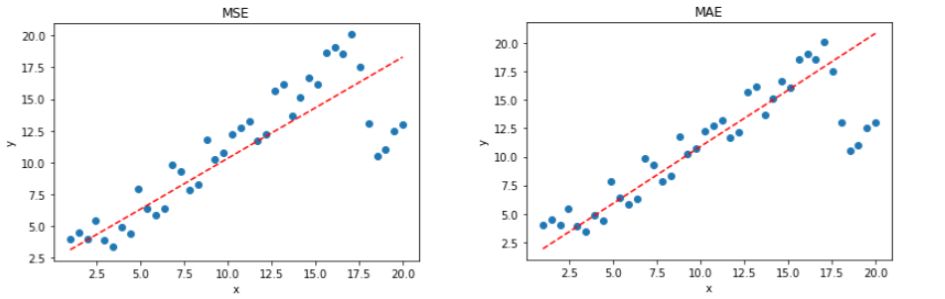
选择 MSE 还是 MAE 呢?
实际应用中,我们应该选择 MSE 还是 MAE 呢?从计算机求解梯度的复杂度来说,MSE 要优于 MAE,而且梯度也是动态变化的,能较快准确达到收敛。但是从离群点角度来看,如果离群点是实际数据或重要数据,而且是应该被检测到的异常值,那么我们应该使用MSE。
另一方面,离群点仅仅代表数据损坏或者错误采样,无须给予过多关注,那么我们应该选择MAE作为损失。
Huber Loss
Huber Loss 是对二者的综合,包含了一个超参数 δ。δ 值的大小决定了 Huber Loss 对 MSE 和 MAE 的侧重性,当 |y−f(x)| ≤ δ 时,变为 MSE;当 |y−f(x)| > δ 时,则变成类似于 MAE,因此 Huber Loss 同时具备了 MSE 和 MAE 的优点,减小了对离群点的敏感度问题,实现了处处可导的功能。
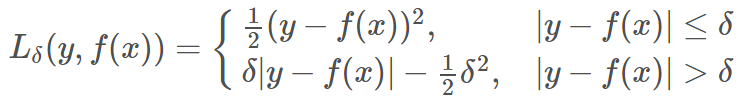
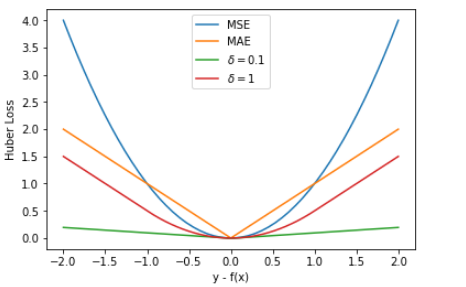
Huber Loss优缺点
Huber Loss 在 |y−f(x)| > δ 时,梯度一直近似为 δ,能够保证模型以一个较快的速度更新参数。当 |y−f(x)| ≤ δ 时,梯度逐渐减小,能够保证模型更精确地得到全局最优值
使用 Huber Loss 作为激活函数,对离群点仍然有很好的抗干扰性,这一点比 MSE 强。
分类问题的损失函数
point wise
MSE、MAE
当然前面回归模型的loss函数,如MSE、MAE,也是可以用在分类上的,只是一个截断的MSE、MAE。
log对数损失函数(逻辑回归)
log损失的基本形式为:log(1+exp(−m))
在逻辑回归的推导中,它假设样本服从伯努利分布(0-1分布),然后求得满足该分布的似然函数,接着取对数求极值等。
但是逻辑回归并没有求似然函数的极值,而是把极大化当做是一种思想,进而推导出它的经验风险函数为:最小化负的似然函数(即max F(y, f(x)) —-> min -F(y, f(x)))。从损失函数的视角来看,它就成了log损失函数了。Log损失log(1+exp(−m)) 是0-1损失函数的一种代理函数。
log损失函数的标准形式:交叉熵
L(Y,P(Y|X))=−logP(Y|X)
取对数是为了方便计算极大似然估计,因为在MLE中直接求导比较困难,所以通常都是先取对数再求导找极值点。损失函数L(Y, P(Y|X))表达的是样本X在分类Y的情况下,使概率P(Y|X)达到最大值(换言之,就是利用已知的样本分布,找到最有可能(即最大概率)导致这种分布的参数值)。因为log函数是单调递增的,所以logP(Y|X)也会达到最大值,因此在前面加上负号之后,最大化P(Y|X)就等价于最小化L了。
对于Logistic回归分类器(二分类)p(y|x;w)可以表示为:
p(y∣x;w)=σ(wTx)^y * (1−σ(wTx))^(1−y)
为了求解其中的参数w,通常使用极大似然估计的方法。
log loss推导过程如下:
1、似然函数
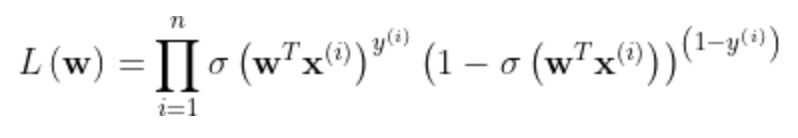
其中,σ(x)=1/(1+exp(−x)
2、log似然
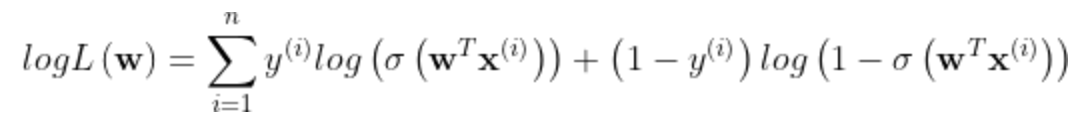
3、需要求解的是使得log似然取得最大值的w。
将其改变为最小值,可以得到如下的形式:
即 J(θ)=![]()
或者
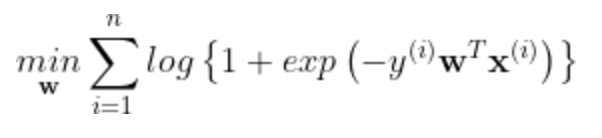
logistic的损失函数表达式

蓝色线代表logistic regression, 紫洋红色线代表SVM;
PDF参考一下:Lecture 6: logistic regression.pdf。
[Sigmod/Softmax变换_sigmoid求原函数-CSDN博客]
交叉熵损失函数Cross-Entropy
![]()
![]()
单个样本label=1时的图像
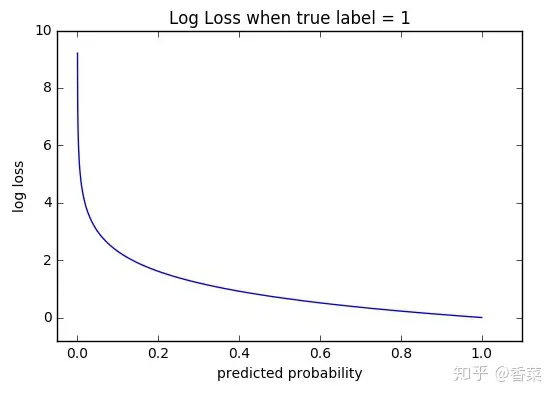
可以看出,该函数是凸函数,求导时能够得到全局最优值。
Softmax loss
logits就是神经网络模型中的 W * X矩阵,注意不需要经过sigmoid,即为未通过激活函数的原始输出。Tensorflow "with logit": The input_vector/logit is not normalized and can scale from [-inf, inf].
[What is the meaning of the word logits in TensorFlow?]
softmax归一化计算
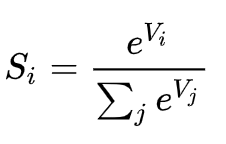
Softmax loss

Softmax loss是由softmax和交叉熵(cross-entropy loss)loss组合而成,所以全称是softmax with cross-entropy loss。
在caffe,tensorflow等开源框架的实现中,直接将两者放在一个层中,而不是分开不同层,可以让数值计算更加稳定,因为正指数概率可能会有非常大的值。
当cross entropy的输入P是softmax的输出时,cross entropy等于softmax loss。即假如log loss中的p的表现形式是softmax概率的形式,那么交叉熵loss就是softmax loss,所以说softmax loss只是交叉熵的一个特例。
令z是softmax层的输入,f(z)是softmax的输出,则
![]()
单个像素i的softmax loss等于cross-entropy error如下

softmax loss的变种和改进
soft softmax
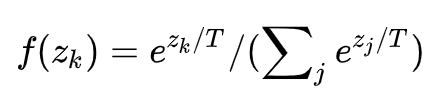
当T=1时,就是softmax的定义,当T>1,就称之为soft softmax,T越大,因为Zk产生的概率差异就会越小。文【2】中提出这个是为了迁移学习,生成软标签,然后将软标签和硬标签同时用于新网络的学习。
Large-Margin Softmax Loss
softmax loss擅长于学习类间的信息,因为它采用了类间竞争机制,它只关心对于正确标签预测概率的准确性,忽略了其他非正确标签的差异,导致学习到的特征比较散。
举个例子吧。假设一个5分类问题,然后一个样本I的标签y=[0,0,0,1,0],也就是说样本I的真实标签是4,假设模型预测的结果概率(softmax的输出)p=[0.1,0.15,0.05,0.6,0.1],可以看出这个预测是对的,那么对应的损失L=-log(0.6),也就是当这个样本经过这样的网络参数产生这样的预测p时,它的损失是-log(0.6)。那么假设p=[0.15,0.2,0.4,0.1,0.15],这个预测结果就很离谱了,因为真实标签是4,而你觉得这个样本是4的概率只有0.1(远不如其他概率高,如果是在测试阶段,那么模型就会预测该样本属于类别3),对应损失L=-log(0.1)。那么假设p=[0.05,0.15,0.4,0.3,0.1],这个预测结果虽然也错了,但是没有前面那个那么离谱,对应的损失L=-log(0.3)。
[卷积神经网络系列之softmax,softmax loss和cross entropy的讲解_softmax层_AI之路的博客-CSDN博客]
作者的实现是通过一个LargeMargin全连接层+softmax loss来共同实现,可参考代码。
softmax loss的实现
同样,multi-label是一定不能使用交叉熵作为loss函数的。因为如果是多目标问题,经过softmax就不会得到多个和为1的概率,而且label有多个1也无法计算交叉熵,因此这个函数只适合单目标的二分类或者多分类问题。并且它只计算了某个类别标签为1时的loss及梯度,而忽略了为0时的loss,而每个输出又相互独立,不像softmax函数那样有归一化的限制。
合页损失函数Hinge Loss(SVM)
SVM的损失函数是hinge损失函数。
在线性支持向量机中,最优化问题可以等价于下列式子:
下面来对式子做个变形,令:![]() ,于是,原式就变成了:
,于是,原式就变成了:
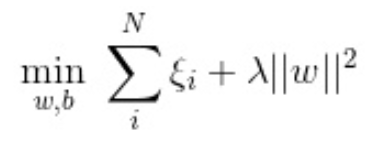
如若取λ=12C,式子就可以表示成:
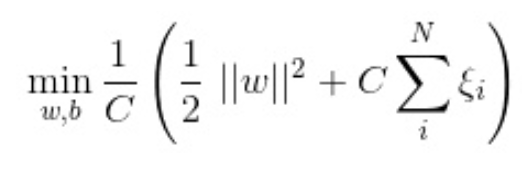
可以看出,该式子与下式非常相似:
前半部分中的l就是hinge损失函数,而后面相当于L2正则项。
Hinge 损失函数的标准形式
L(y)=max(0,1−yỹ ),y=±1
或者表示为[ 1 - t(wx + b) ]+

可以看出,当|y|>=1时,L(y)=0。[Hinge-loss]
核函数
在libsvm中一共有4中核函数可以选择,对应的是-t参数分别是:0-线性核;1-多项式核;2-RBF核;3-sigmoid核。
[functions - How do you minimize "hinge-loss"? - Mathematics Stack Exchange]
感知损失(感知机算法)
感知损失是Hinge损失的一个变种,感知损失的具体形式如下:max(0,−m) 。运用感知损失的典型分类器是感知机算法。
感知机算法的损失函数
感知机算法只需要对每个样本判断其是否分类正确,只记录分类错误的样本,其损失函数为:
minw,b[−∑i=1ny(i)(wTx(i)+b)]
两者的等价
对于感知损失:max(0,−m)
或者表示为[ - t(wx + b) ]+
优化的目标为:
minw[∑i=1nmax(0,−fw(x(i))y(i))]
在上述的函数fw(x(i))中引入截距b,即:
fw,γ(x(i))=wTx(i)+b
上述的形式转变为:
minw,b[∑i=1nmax(0,−(wTx(i)+b)y(i))]
对于max函数中的内容,可知:
max(0,−(wTx(i)+b)y(i))⩾0
对于错误的样本,有:
max(0,−(wTx(i)+b)y(i))=−(wTx(i)+b)y(i)
类似于Hinge损失,令下式成立:
max(0,−fw,b(x)y)=minξξ
约束条件为:
ξ⩾−fw,b(x)y
则感知损失变成:
minξ[∑i=1nξi]
即为:
minw,b[−∑i=1ny(i)(wTx(i)+b)]
Hinge损失对于判定边界附近的点的惩罚力度较高,而感知损失只要样本的类别判定正确即可,而不需要其离判定边界的距离,这样的变化使得其比Hinge损失简单,但是泛化能力没有Hinge损失强。
指数损失函数(Adaboost)
学过Adaboost算法的人都知道,它是前向分步加法算法的特例,是一个加和模型,损失函数就是指数函数。
在Adaboost中,经过m此迭代之后,可以得到 fm(x) :
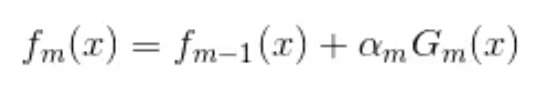
Adaboost每次迭代时的目的是为了找到最小化下列式子时的参数α和G:
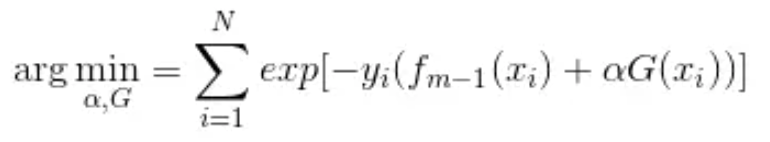
指数损失函数(exp-loss)的标准形式

(lz感觉就像是soft版本的hinge loss)
可以看出,Adaboost的目标式子就是指数损失,在给定n个样本的情况下,Adaboost的损失函数为:
Note: 为什么adaboost的loss是指数损失?假设是指数损失,最小化f^t+1(第一个公式),求alpha_m的值刚好就是adaboost中alpha_m更新方式。
在AdaBoost中,数据权重的更新方式为:
u(t+1)nu(t+1)nu(T+1)n∑n=1Nu(T+1)n=u(t)n◊−yngt(xn)=u(t)nexp(−ynαtgt(xn))=1Nexp(−yn∑t=1Tαtgt(xn))=1N∑n=1Nexp(−yn∑t=1Tαtgt(xn))
AdaBoost的训练的目标就是减少∑Nn=1u(T+1)n,因此其风险函数为:
1N∑n=1Nexp(−yn∑t=1Tαtgt(xn))
关于Adaboost的推导,可以参考Wikipedia:AdaBoost或者《统计学习方法》P145。
0-1损失函数
01 loss是最本质的分类损失函数,但是这个函数不易求导,在模型的训练不常用,通常用于模型的评价。0-1损失是一个非凸的函数,在求解的过程中,存在很多的不足,通常在实际的使用中将0-1损失函数作为一个标准,选择0-1损失函数的代理函数(如log损失函数,hinge损失函数(0-1损失函数的上界))作为损失函数。the zero-one loss is what you actually want in classification. Unfortunately it is non-convex and thus not practical since the optimization problem becomes more or less intractable。
在分类问题中,可以使用函数的正负号来进行模式判断,函数值本身的大小并不是很重要,0-1损失函数比较的是预测值fw(x(i))与真实值y(i)的符号是否相同,0-1损失的具体形式如下:
L01(m)={0 if m⩾0 ;1 if m<0}
以上的函数等价于下述的函数:
12(1−sign(m))
0-1损失并不依赖m值的大小,只取决于m的正负号。
带噪学习|不完美场景下的损失函数
设计 loss function 的思路:
GCE损失:Generalized Cross Entropy Loss
AAAI2017 Robust Loss Functions under Label Noise for Deep Neural Networks已经证明选取mean absolute error (MAE)可以有效抑制噪声数据,但MAE存在收敛速度慢、训练困难的问题。即MAE 以均等分配的方式处理各个 sample,而 CE(cross entropy)会向识别困难的 sample 倾斜(这也是CCE相比MAE训练速度更快的原因),因此针对 noisy label,MAE 比 CE 更加鲁棒,但是 CE 的准确度更高,拟合也更快。
CCE和MAE的梯度计算:

从CCE的梯度中可看出,每个样本有一个权重![]()
样本越难学习,f值(模型输出)越小,权重更高,因此CCE偏向困难样本,这也是CCE相比MAE训练速度更快的原因,但在带噪数据中,往往噪声数据的f值更小,因此CCE会在噪声数据上overfitting。
Lq Loss:
q是超参数,介于(0,1]之间,当q等于1时,Lq Loss就是MAE,当q趋近0时,Lq loss是CCE,因此本文提出的Lq loss是CCE和MAE的泛化。
进一步优化参考[NIPS2018 Generalized Cross Entropy Loss for ...with Noisy Labels]
peer loss
ICML'20[Peer loss functions: learning from noisy labels without knowing noise rates]
![]()

为什么 peer loss 可以很好地解决 noisy label 问题?为了方便,这里先把 l1、l2 都定义成 CE loss,那么在第一项,它表现的像 positive learning,因为它就是一个传统的 CE function,而在第二项,它像 negative learning,也就是在标记错的时候,比如把狗标成汽车,如果用 positive learning 进行学习的话那就出现问题了,它是随机从一个 label 中进行抽取,希望让模型学到它不是一个鸟,狗不是一个鸟。
samples selection 和 label correction思路:
NeurlPS 2018 上的这篇论文 (Co-teaching: Robust Training of Deep Neural Networks with Extremely Noisy Labels) 就是关于 Co-teaching 的。它的基本假设是认为 noisy label 的 loss 要比 clean label 的要大,于是它并行地训练了两个神经网络 A 和 B,在每一个 Mini-batch 训练的过程中,每一个神经网络把它认为 loss 比较小的样本,送给它其另外一个网络,这样不断进行迭代训练。
[腾讯优图:带噪学习和协作学习,不完美场景下的神经网络优化策略 | 机器之心]
不平衡分类问题的损失函数
Normalized Cross-Entropy
在Facebook的paper中,模型使用NE(Normalized Cross-Entropy)进行评价,或者叫做 Normalized Entropy, 计算公式如下

where pi is the estimated P(yi=1)and p=∑yi/N is the "average" probability over the training set.
- p代表平均经验CTR
- NE等于预测的log loss除以background CTR的熵,使得NE对background CTR不敏感
- NE越小模型性能越好
[Normalized Cross Entropy - Cross Validated]
[http://quinonero.net/Publications/predicting-clicks-facebook.pdf]
分母就是平均的损失,平均的损失实际上就等于整个数据集的entropy,所以叫normalized entropy,这种是消除了不平衡数据集的影响。
Normalized Cross-Entropy相对于Cross-Entropy的优势在于它可以在不同类别之间进行有效的比较。Cross-Entropy是一种度量两个概率分布之间差异的方法,但是如果不同类别之间的样本数量不平衡,那么Cross-Entropy就会偏向于数量较大的类别。通过归一化,Normalized Cross-Entropy可以消除这种偏差,从而更准确地衡量模型的性能。[monica]
实现[TensorFlow:交叉熵损失函数_tensorflow 交叉熵损失_-柚子皮-的博客-CSDN博客]
带权重交叉熵损失函数
对于准确率要求有限的情况下,如何定向的提升模型的召回率。
业务场景:业务部门对于假阴性和假阳性的容忍度是不同的,对于假阴性更为敏感,可以容忍一部分假阳性的存在。如果所有的阳性都可以检测出来,可以容忍准确率低一些。

recall = tp/(tp+fn),要使recall变大,假阳性fn要变小,所以fn惩罚要变更大。
从损失函数下手,让假阴性的惩罚比假阳性的惩罚更大,在binary crossentropy 两项前面加上不同的权重(下面的loss中w1增大为w0的5倍左右)。
loss变成以下形式:
![]()
其中w1 和 w0 分别代表了当前数据的实际标签为1或 0时候的损失函数权重。
相反的,如果模型想要增大精度,可以设置loss中w0增大为w1的5倍左右。
[【算法实验】使用带权重交叉熵损失函数定向提升模型的召回率]
平衡交叉熵函数balanced cross entropy
基于样本非平衡造成的损失函数倾斜,一个直观的做法就是在损失函数中添加权重因子,提高少数类别在损失函数中的权重,平衡损失函数的分布。
如在二分类问题中,添加权重参数 α
![]()
α = n/(m+n)
其中m为正样本个数,n为负样本个数,N为样本总数,m+n=N。
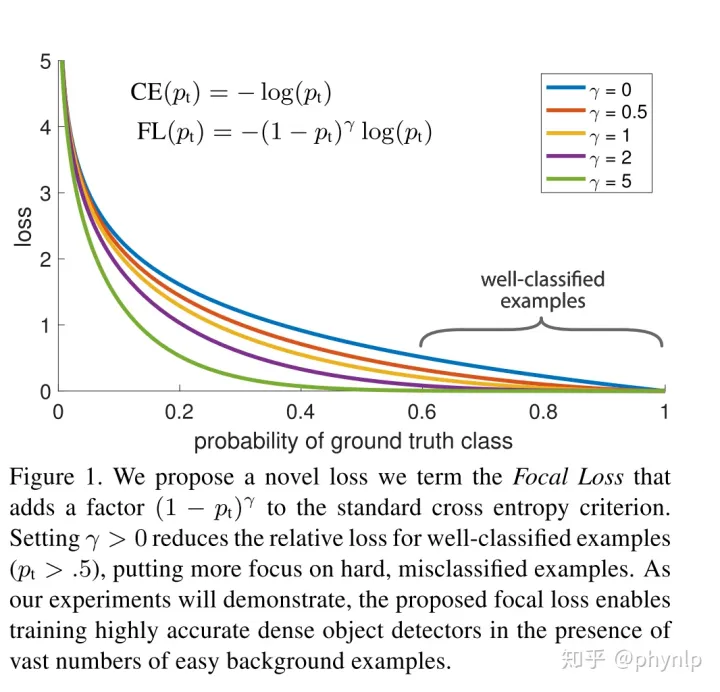
focal loss
从交叉熵损失函数出发,主要是为了解决难易样本数量不平衡(注意,有区别于正负样本数量不平衡)的问题。
focal loss的具体形式为:
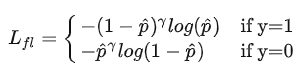

focal loss相比交叉熵多了一个modulating factor即 (1−p_t)^γ。对于分类准确的样本 p_t→1 ,modulating factor趋近于0。对于分类不准确的样本 1−p_t→1 ,modulating factor趋近于1。即相比交叉熵损失,focal loss对于分类不准确的样本,损失没有改变,对于分类准确的样本,损失会变小。 整体而言,相当于增加了分类不准确样本在损失函数中的权重。
p_t也反应了分类的难易程度, p_t 越大,说明分类的置信度越高,代表样本越易分; p_t 越小,分类的置信度越低,代表样本越难分。因此focal loss相当于增加了难分样本在损失函数的权重,使得损失函数倾向于难分的样本,有助于提高难分样本的准确度。
直觉上来讲样本非平衡造成的问题就是样本数少的类别分类难度较高。因此从样本难易分类角度出发,使得loss聚焦于难分样本,解决了样本少的类别分类准确率不高的问题,当然难分样本不限于样本少的类别,也就是focal loss不仅仅解决了样本非平衡的问题,同样有助于模型的整体性能提高。
当参数变化后,可能会使原先易训练的样本 p_t 发生变化,即可能变为难训练样本。当这种情况发生时,可能会造成模型收敛速度慢,正如苏剑林在他的文章中提到的那样。
为了防止难易样本的频繁变化,应当选取小的学习率。防止学习率过大,造成 w 变化较大从而引起 p_t 的巨大变化,造成难易样本的改变。
同时解决正负难易问题公式
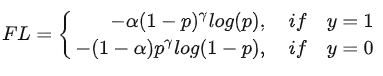
实验表明γ 取2, α 取0.25的时候效果最佳。
这样一来,训练过程关注对象的排序为正难>负难>正易>负易。
focal loss与交叉熵的对比
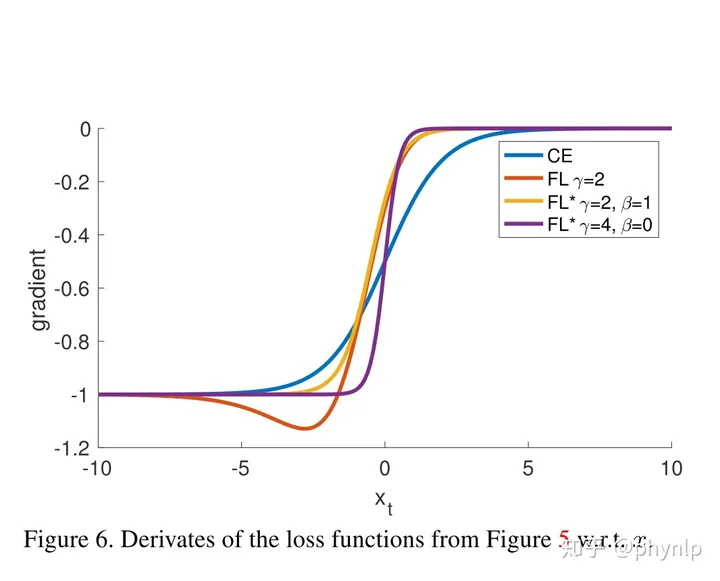
focal loss vs balanced cross entropy
focal loss相比balanced cross entropy而言,二者都是试图解决样本不平衡带来的模型训练问题,后者从样本分布角度对损失函数添加权重因子,前者从样本分类难易程度出发,使loss聚焦于难分样本。
[5分钟理解Focal Loss与GHM——解决样本不平衡利器 - 知乎]
代码实现
[mmdetection/blob/main/mmdet/models/losses/focal_loss.py]
[GitHub - Hsuxu/Loss_ToolBox-PyTorch: PyTorch Implementation of Focal Loss]
GHM(gradient harmonizing mechanism)
Gradient Harmonized Single-stage Detector",AAAI2019,是基于Focal loss的改进:让模型过多关注那些特别难分的样本肯定是存在问题的,样本中有离群点(outliers),可能模型已经收敛了但是这些离群点还是会被判断错误;Focal loss的超参很难调。
Focal Loss是从置信度p的角度入手衰减loss,而GHM是一定范围置信度p的样本数量的角度衰减loss。
文章先定义了一个梯度模长g:g = torch.abs(pred.sigmoid().detach() - target)
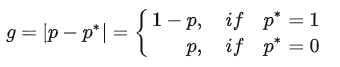
至于为什么叫梯度模长,因为g是从交叉熵损失求梯度得来的。
g正比于检测的难易程度,g越大则检测难度越大。
Note: 从# 计算梯度模长g = torch.abs(pred.sigmoid().detach() - target)的代码看出,梯度模长d就是预测和实际的差异,差异过大和过小分别可能表示数据有问题或者太容易。应该关注下差异大但是没那么大的吧,有点类似hard negtive的意思。
梯度模长与样本数量的关系

可以看到,梯度模长接近于0的样本数量最多,随着梯度模长的增长,样本数量迅速减少,但是在梯度模长接近于1时,样本数量也挺多。
GHM的想法是,我们确实不应该过多关注易分样本,但是特别难分的样本(outliers,离群点)也不该关注啊!
这些离群点的梯度模长d要比一般的样本大很多,如果模型被迫去关注这些样本,反而有可能降低模型的准确度!况且,这些样本的数量也很多!
梯度密度

因此梯度密度的物理含义是:单位梯度模长g部分的样本个数。
对于每个样本,把交叉熵CE×该样本梯度密度的倒数即可!
用于分类的GHM损失
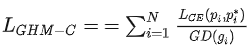
N是总的样本数量。
抑制的效果
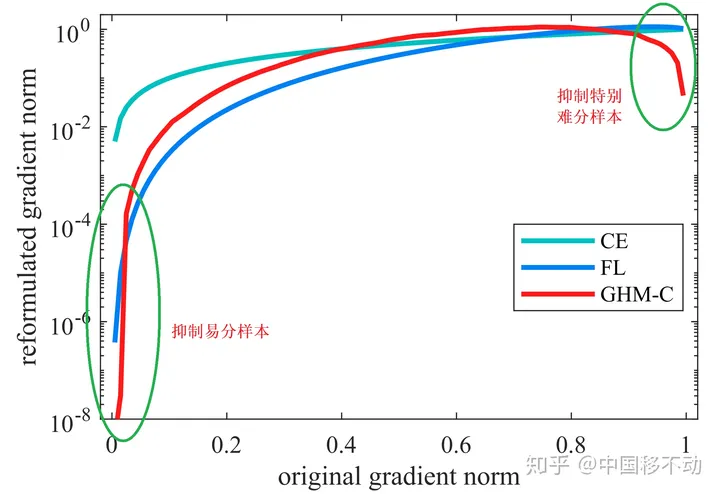
GHM之所以效果更好,不仅仅因为对easy example做了loss上的抑制,同时对very hard example也起到了一定的忽略作用。文中把这些very hard examples定义为离群点outliers,这些outliers在模型的不断拟合过程中一直为very hard examples,如果模型强行的去拟合这些outliers,反而会起到适得其反的效果,这也就是为什么也要抑制这些very hard examples的原因之一。
[5分钟理解Focal Loss与GHM——解决样本不平衡利器 - 知乎]
召回粗排分类问题的损失函数loss function
极大似然通用公式

sampled softmax loss

这种loss将召回看成一个超大规模的多分类问题,优化的目标是使user选中item+的概率最高。
user选中item+的概率=![]() ,其中|I|代表整个item候选集。
,其中|I|代表整个item候选集。
为使以上概率达到最大,要求分子,即user与item+的匹配度,尽可能大;而分母,即user与除item+之外的所有item的匹配度之和,尽可能小。体现出上文所说的“不与label比较,而是匹配得分相互比较”的特点。
但是,由于计算分配牵扯到整个候选item集合,计算量大到不现实。所以实际优化的是sampled softmax loss,即从中随机采样若干item-,近似代替计算完整的分母。
![]()
Note: 推导类似“nce”。1−σ(s)=σ(−s)。
nce(sampled softmax loss的二维版本?)

Margin hinge loss / triplet loss
Margin hinge loss/Pairwise Hinge Loss:
优化目标是:user与正样本item的匹配程度,要比,user与负样本item的匹配程度,高出一定的阈值。![]()
loss=max(0,margin-<u,d+>+<u,d->)
即同一个用户与“正文章”(点击过的文章)的匹配度<u,d+>,要比用户与“负文章”(怎么选择负文章就是召回的关键)的匹配度<u,d->高于一定的阈值
triplet loss:其实就是将Hinge Loss相似度变成相反的距离
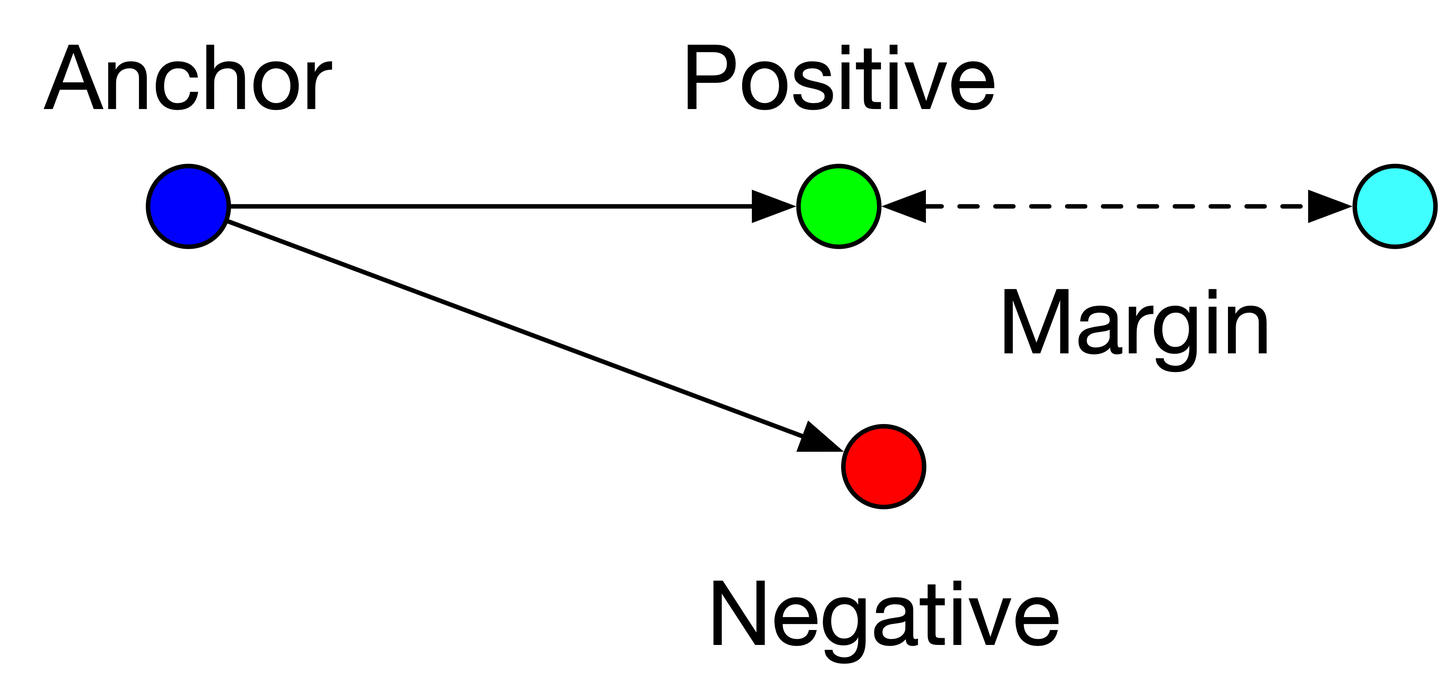
损失函数公式: L=max(d(a, p) - d(a,n)+margin,0)
输入是一个三元组,包括锚(Anchor)示例、正(Positive)示例、负(Negative)示例,通过优化锚示例与正示例的距离小于锚示例与负示例的距离,实现样本之间的相似性计算。
a:anchor,锚示例;p:positive,与a是同一类别的样本;n:negative,与a是不同类别的样本;margin是一个大于0的常数(作用是太弱的负样本产生的大loss就别参加更新了,没意思)。最终的优化目标是拉近a和p的距离,拉远a和n的距离。
样本可以分为三类:
- easy triplets: L=0 ,即 d(a,p)+margin < d(a,n) ,这种情况不需要优化,天然a和p的距离很近,a和n的距离很远,如下图
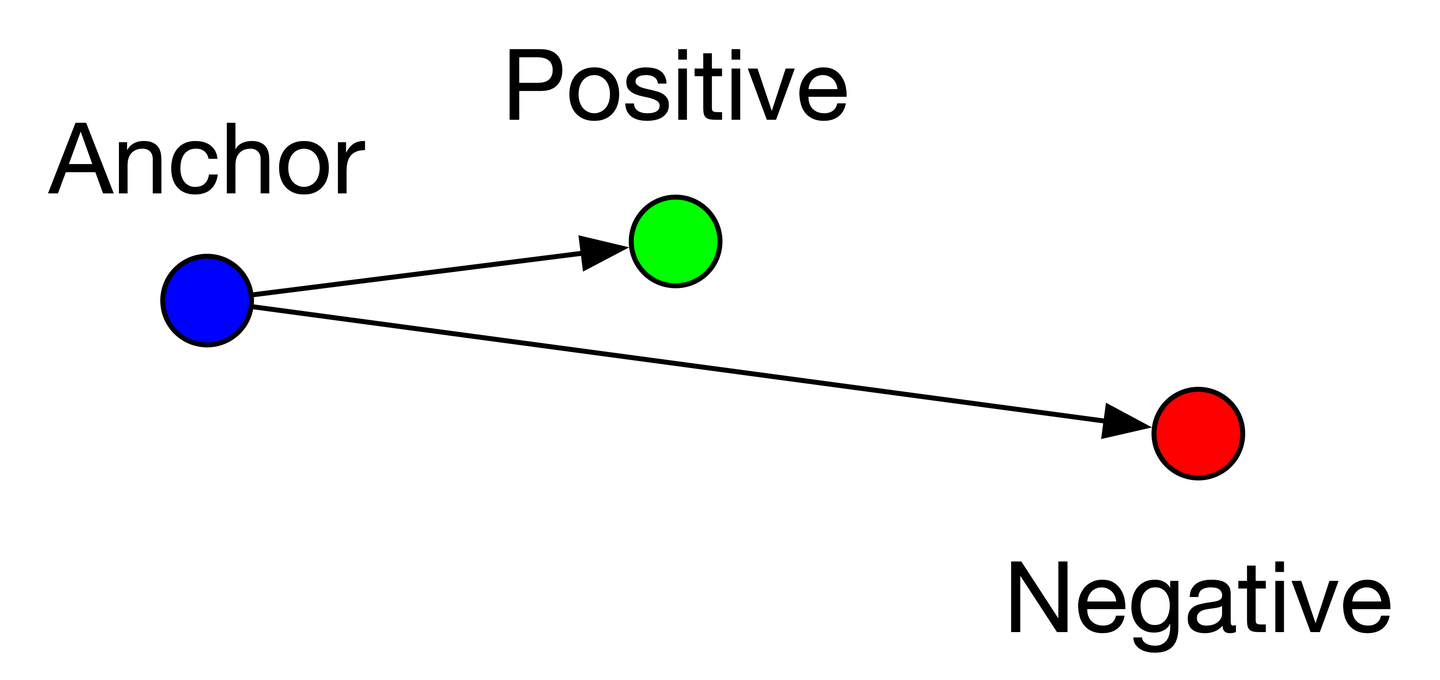
easy triplets示例
- hard triplets: L>margin ,即 d(a,n)>d(a,p) ,a和n的距离近,a和p的距离远,这种情况损失最大,需要优化,如下图

hard triplets示例
- semi-hard triplets: L<margin ,即 d(a,p)<d(a,n)<d(a,p)+margin ,即a和p的距离比a和n的距离近,但是近的不够多,不满足margin,这种情况存在损失,但损失比hard triplets要小,也需要优化,如下图
semi-hard triplets示例
为什么要设置margin?
- 避免模型走捷径,将negative和positive的embedding训练成很相近,因为如果没margin,triplets loss公式就变成了 L=max(d(a,p)-d(a,n),0) ,那么只要 d(a,p)=d(a,n) 就可以满足上式,也就是锚点a和正例p与锚点a和负例n的距离一样即可,这样模型很难正确区分正例和负例。
- 设定一个margin常量,可以迫使模型努力学习,能让锚点a和负例n的distance值更大,同时让锚点a和正例p的distance值更小。
- 由于margin的存在,使得triplets loss多了一个参数,margin的大小需要调参。如果margin太大,则模型的损失会很大,而且学习到最后,loss也很难趋近于0,甚至导致网络不收敛,但是可以较有把握的区分较为相似的样本,即a和p更好区分;如果margin太小,loss很容易趋近于0,模型很好训练,但是较难区分a和p。
triplets loss该如何构造训练集?
首先能看到,对于triplet loss的损失公式,要有3个输入,即锚点a,正例p和负例n。对于样本来讲,有3种,即easy triplets、hard triplets和semi-hard triplets。
理论上讲,使用hard triplets训练模型最好,因为这样模型能够有很好的学习能力,但由于margin的存在,这类样本可能模型没法很好的拟合,训练比较困难;其次是使用semi-hard triplet,这类样本是实际使用中最优选择,因为这类样本损失不为0,而且损失不大,模型既可以学习到样本之间的差异,又较容易收敛;至于easy triplet,损失为0,不用拿来训练。
针对不同的业务,其实构造的原则也不一样,比如人脸识别场景,样本的选择应该满足 d(a,p) 和 d(a,n) 尽可能接近,其实就是选择semi-hard triplets样本,这样一来,损失函数的公式不容易满足,也就意味着损失值不够低,模型必须认真训练和更新自己的参数,从而努力让 d(a,n) 的值尽可能变大,同时让 d(a,p) 的值尽可能变小。
针对搜索引擎场景,比如dssm,正样本是用户query搜索点击的doc做正例,负例是采用随机采样的策略,一般随机采样的策略是不可控的,既可能采样到easy triplet,又可能采样到hard triple,要看采样的池子怎么确定。
Facebook最近提出的EBR也指出,在随机采样的策略上,要增加semi-hard triplets,选取搜索曝光页面第101~500,也就是让模型看到这些模糊的样本,有些相似但没那么相似,这样模型才能更好的学习到样本之间的差异。
什么时候用triplet Loss,什么时候用softmax 呢?
在淘宝 EBR - MGDSPR中提到,使用triplet loss 这种pairwise 作为训练目标,使训练和测试行为不一致。在推理的过程中,模型需要为候选集选择Top-K items 作为召回。要求有全局比较的能力,然而 triplet loss 只能进行局部比较,而softmax 赋予模型全局比较的能力,此外,triplet loss 引入的margin 对performance 有重大的影响,所以使用softmax 为训练目标,没有额外的超参数同时实现更好的收敛和更好的performance。并且传统的softmax 是一个计算昂贵的partition 函数,与items 数量呈线性比例,所以在实践中使用sampled softmax(softmax 的无偏近似值)
[再思考双塔 Embedding-based Retrieval 工业界比对 - 知乎]
bpr loss
BPR(Bayesian Personalized Ranking)损失函数最初是由 Steffen Rendle 等人在论文 BPR: Bayesian Personalized Ranking from Implicit Feedback 中提出的。基本思想是:给定一个用户和两个物品,模型需要将用户更喜欢的物品排在用户更不喜欢的物品之前,从而学习到用户的个性化偏好。即计算"给user召回时,将item+排在item-前面的概率",
![]()
因为<user, item+, item->的ground-truth label永远是1,所以将其喂入binary cross-entropy loss的公式,就有
![]()

对比来看:1 margin hinge loss多出一个超参margin需要调节,Hinge loss中,<u,d+>-<u,d->大于margin后,对于loss的贡献减少为0。而BPR则没有针对<u,d+>-<u,d->设定上限,鼓励优势越大越好。如果数据很稀疏(比如成单[相比点击]),可能用bpr就比margin hinge好点,这时正比负好一点很可能是随机事件导致,而不是真好,所以需要更重视正比负好较多的? 2 展开来看本质就是sampled softmax。
[sampled softmax loss 和 margin hinge loss 以及 BPR Loss]
Pairwise分类问题的损失函数
排序模型中的负样本一般都是“真负”样本,label的准确性允许我们使用pointwise loss追求“绝对准确性”。
但是在召回场景下,绝大多数item从未给user曝光过,我们再从中随机采样一部分作为负样本,这个negative label是存在噪声的。在这种情况下,再照搬排序使用binary cross-entropy loss追求“预估值”与“label”之间的“绝对准确性”,就有点强人所难了。所以,召回算法往往采用Pairwise LearningToRank(LTR),建模“排序的相对准确性”。
sampled softmax loss
见上
margin hinge loss
见上
BPR Loss
见上
Loss函数总结
- squared loss方便求导,缺点是当分类正确的时候随着ys的增大损失函数也增大。
- cross entropy方便求导,逼近01 loss。
- Hinge Loss当ys≥1,损失为0,对应分类正确的情况;当ys<1时,损失与ys成正比,对应分类不正确的情况(软间隔中的松弛变量)。
- exponential loss方便求导,逼近01 loss。
- squared loss, cross entropy,exponential loss以及hinge loss的左侧都是凸函数,方便求导有利于优化问题的求解;同时这些loss函数都是01 error的上界,可以通过减少loss来实现01问题的求解,即求解分类问题。
- the zero-one loss is what you actually want in classification. Unfortunately it is non-convex and thus not practical since the optimization problem becomes more or less intractable
- the hinge loss (used in support-vector classification) results in solutions which are sparse in the data (due to it being zero for f(x)>1
- ) and is relatively robust to outliers (it grows only linearly for f(x)→−∞
- ) . It doesn't provide well-calibrated probabilities.
- the log-loss (used, e.g., in logistic regression) results in well calibrated probabilities. It is thus the loss of choice if you don't want only binary predictions but also probabilities for the outcomes. On the downside, it's solutions are not sparse in the data space and it is more influenced by outliers than the hinge loss.
- the exponential loss (used in AdaBoost) is very susceptible to outliers (due to its rapid increase when f(x)→−∞
- ). It is primarily used in AdaBoost since it results there in a simple and efficient boosting algorithm.
- the perceptron loss is basically a shifted version of the hinge loss. The hinge loss also penalizes points which are on the correct side of the boundary but very close to it (maximum-margin principle). The perceptron loss, on the other hand, is happy as long as a datapoint is on the correct side of the boundary, which leaves the boundary under-determined if the data is truly linearly separable and results in worse generalization than a maximum-margin boundary.
[Advice for applying Machine Learning]
几种损失函数的可视化图像

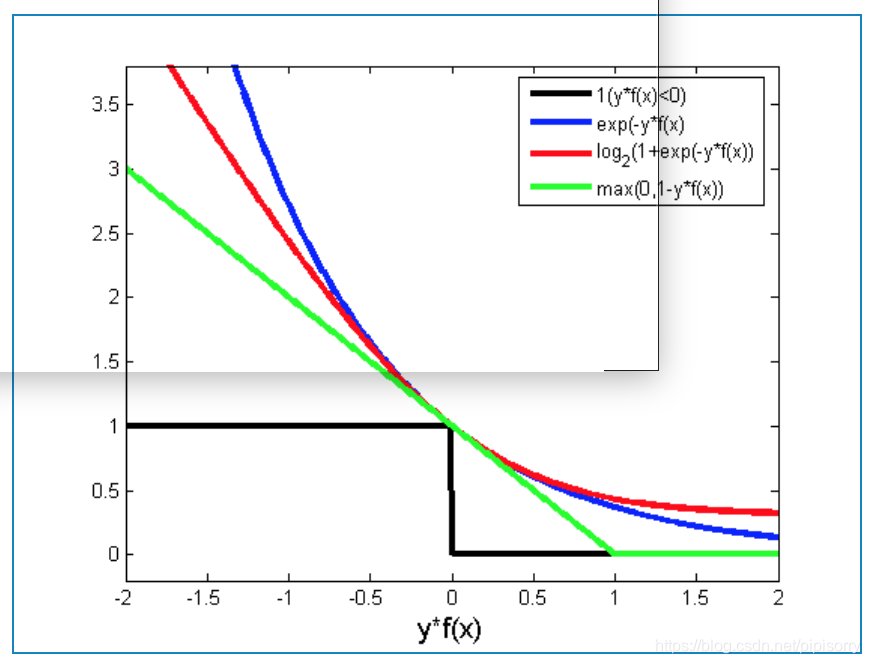
Note: 横轴表示函数间隔ty = t*(wx + b),纵轴表示损失。

[Loss functions · VowpalWabbit/vowpal_wabbit Wiki · GitHub]
from: 损失函数loss_loss函数_-柚子皮-的博客-CSDN博客
ref: [library_design/losses]
[《统计学习方法》 李航]
[机器学习的损失函数 ]
[机器学习-损失函数]*















 7775
7775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









